 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Particle World Models: Self-supervised Object-centric Stochastic Dynamics Modeling
Mar 04, 2026We introduce Latent Particle World Model (LPWM), a self-supervised object-centric world model scaled to real-world multi-object datasets and applicable in decision-making. LPWM autonomously discovers keypoints, bounding boxes, and object masks directly from video data, enabling it to learn rich scene decompositions without supervision. Our architecture is trained end-to-end purely from videos and supports flexible conditioning on actions, language, and image goals. LPWM models stochastic particle dynamics via a novel latent action module and achieves state-of-the-art results on diverse real-world and synthetic datasets. Beyond stochastic video modeling, LPWM is readily applicable to decision-making, including goal-conditioned imitation learning, as we demonstrate in the paper. Code, data, pre-trained models and video rollouts are available: https://taldatech.github.io/lpwm-web
Hierarchical Entity-centric Reinforcement Learning with Factored Subgoal Diffusion
Feb 02, 2026We propose a hierarchical entity-centric framework for offline Goal-Conditioned Reinforcement Learning (GCRL) that combines subgoal decomposition with factored structure to solve long-horizon tasks in domains with multiple entities. Achieving long-horizon goals in complex environments remains a core challenge in Reinforcement Learning (RL). Domains with multiple entities are particularly difficult due to their combinatorial complexity. GCRL facilitates generalization across goals and the use of subgoal structure, but struggles with high-dimensional observations and combinatorial state-spaces, especially under sparse reward. We employ a two-level hierarchy composed of a value-based GCRL agent and a factored subgoal-generating conditional diffusion model. The RL agent and subgoal generator are trained independently and composed post hoc through selective subgoal generation based on the value function, making the approach modular and compatible with existing GCRL algorithms. We introduce new variations to benchmark tasks that highlight the challenges of multi-entity domains, and show that our method consistently boosts performance of the underlying RL agent on image-based long-horizon tasks with sparse rewards, achieving over 150% higher success rates on the hardest task in our suite and generalizing to increasing horizons and numbers of entities. Rollout videos are provided at: https://sites.google.com/view/hecrl
A Classification View on Meta Learning Bandits
Apr 06, 2025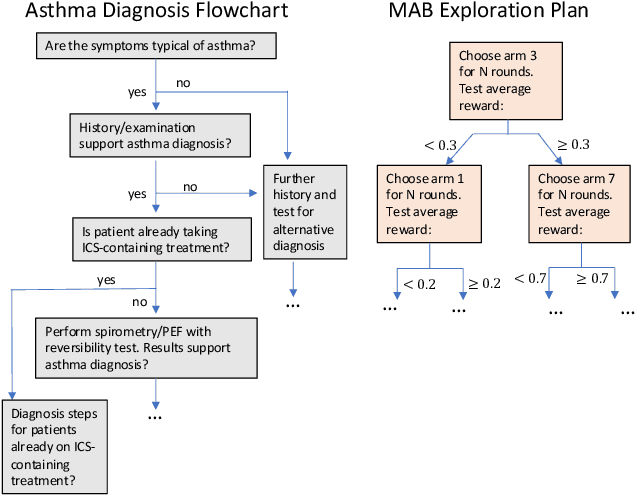
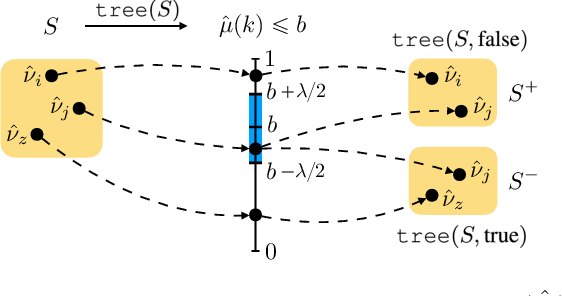
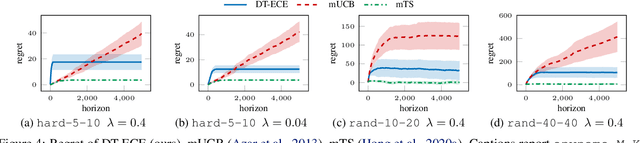
Contextual multi-armed bandits are a popular choice to model sequential decision-making. E.g., in a healthcare application we may perform various tests to asses a patient condition (exploration) and then decide on the best treatment to give (exploitation). When humans design strategies, they aim for the exploration to be fast, since the patient's health is at stake, and easy to interpret for a physician overseeing the process. However, common bandit algorithms are nothing like that: The regret caused by exploration scales with $\sqrt{H}$ over $H$ rounds and decision strategies are based on opaque statistical considerations. In this paper, we use an original classification view to meta learn interpretable and fast exploration plans for a fixed collection of bandits $\mathbb{M}$. The plan is prescribed by an interpretable decision tree probing decisions' payoff to classify the test bandit. The test regret of the plan in the stochastic and contextual setting scales with $O (\lambda^{-2} C_{\lambda} (\mathbb{M}) \log^2 (MH))$, being $M$ the size of $\mathbb{M}$, $\lambda$ a separation parameter over the bandits, and $C_\lambda (\mathbb{M})$ a novel classification-coefficient that fundamentally links meta learning bandits with classification. Through a nearly matching lower bound, we show that $C_\lambda (\mathbb{M})$ inherently captures the complexity of the setting.
From Configuration-Space Clearance to Feature-Space Margin: Sample Complexity in Learning-Based Collision Detection
Feb 06, 2025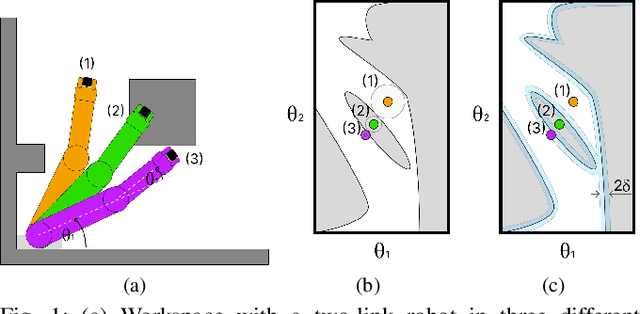
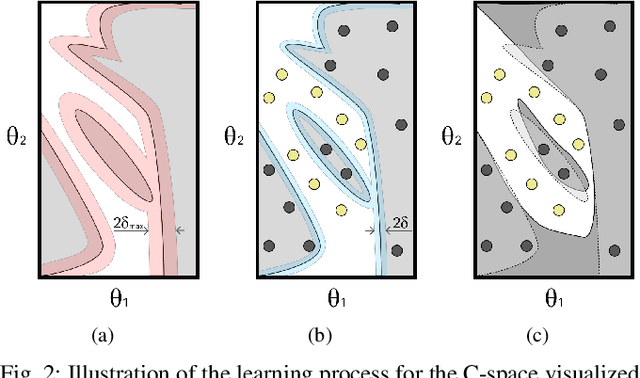
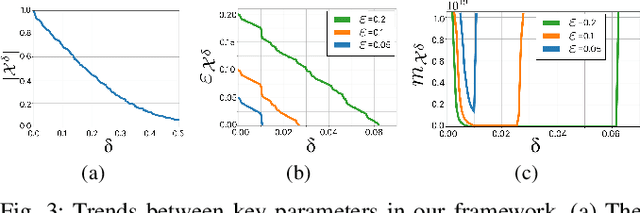
Motion planning is a central challenge in robotics, with learning-based approaches gaining significant attention in recent years. Our work focuses on a specific aspect of these approaches: using machine-learning techniques, particularly Support Vector Machines (SVM), to evaluate whether robot configurations are collision free, an operation termed ``collision detection''. Despite the growing popularity of these methods, there is a lack of theory supporting their efficiency and prediction accuracy. This is in stark contrast to the rich theoretical results of machine-learning methods in general and of SVMs in particular. Our work bridges this gap by analyzing the sample complexity of an SVM classifier for learning-based collision detection in motion planning. We bound the number of samples needed to achieve a specified accuracy at a given confidence level. This result is stated in terms relevant to robot motion-planning such as the system's clearance. Building on these theoretical results, we propose a collision-detection algorithm that can also provide statistical guarantees on the algorithm's error in classifying robot configurations as collision-free or not.
EC-Diffuser: Multi-Object Manipulation via Entity-Centric Behavior Generation
Dec 25, 2024



Object manipulation is a common component of everyday tasks, but learning to manipulate objects from high-dimensional observations presents significant challenges. These challenges are heightened in multi-object environments due to the combinatorial complexity of the state space as well as of the desired behaviors. While recent approaches have utilized large-scale offline data to train models from pixel observations, achieving performance gains through scaling, these methods struggle with compositional generalization in unseen object configurations with constrained network and dataset sizes. To address these issues, we propose a novel behavioral cloning (BC) approach that leverages object-centric representations and an entity-centric Transformer with diffusion-based optimization, enabling efficient learning from offline image data. Our method first decomposes observations into an object-centric representation, which is then processed by our entity-centric Transformer that computes attention at the object level, simultaneously predicting object dynamics and the agent's actions. Combined with the ability of diffusion models to capture multi-modal behavior distributions, this results in substantial performance improvements in multi-object tasks and, more importantly, enables compositional generalization. We present BC agents capable of zero-shot generalization to tasks with novel compositions of objects and goals, including larger numbers of objects than seen during training. We provide video rollouts on our webpage: https://sites.google.com/view/ec-diffuser.
A Bayesian Approach to Online Planning
Jun 04, 2024


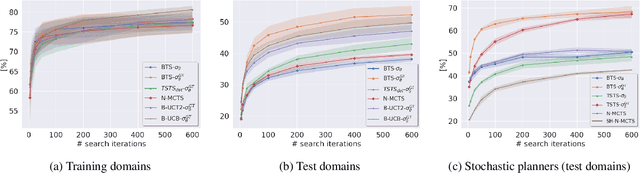
The combination of Monte Carlo tree search and neural networks has revolutionized online planning. As neural network approximations are often imperfect, we ask whether uncertainty estimates about the network outputs could be used to improve planning. We develop a Bayesian planning approach that facilitates such uncertainty quantification, inspired by classical ideas from the meta-reasoning literature. We propose a Thompson sampling based algorithm for searching the tree of possible actions, for which we prove the first (to our knowledge) finite time Bayesian regret bound, and propose an efficient implementation for a restricted family of posterior distributions. In addition we propose a variant of the Bayes-UCB method applied to trees. Empirically, we demonstrate that on the ProcGen Maze and Leaper environments, when the uncertainty estimates are accurate but the neural network output is inaccurate, our Bayesian approach searches the tree much more effectively. In addition, we investigate whether popular uncertainty estimation methods are accurate enough to yield significant gains in planning. Our code is available at: https://github.com/nirgreshler/bayesian-online-planning.
Test-Time Regret Minimization in Meta Reinforcement Learning
Jun 04, 2024
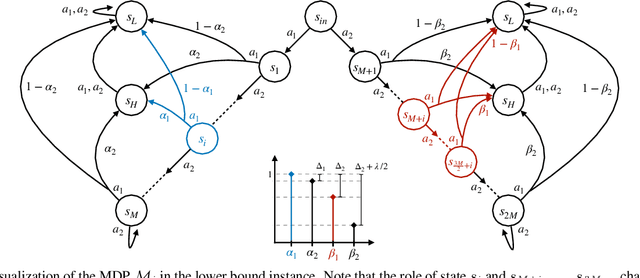
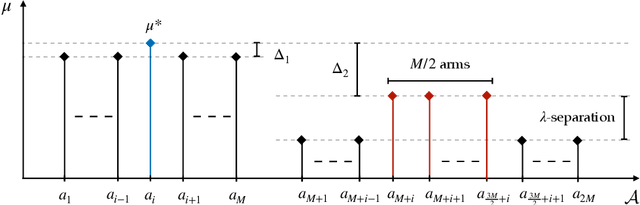
Meta reinforcement learning sets a distribution over a set of tasks on which the agent can train at will, then is asked to learn an optimal policy for any test task efficiently. In this paper, we consider a finite set of tasks modeled through Markov decision processes with various dynamics. We assume to have endured a long training phase, from which the set of tasks is perfectly recovered, and we focus on regret minimization against the optimal policy in the unknown test task. Under a separation condition that states the existence of a state-action pair revealing a task against another, Chen et al. (2022) show that $O(M^2 \log(H))$ regret can be achieved, where $M, H$ are the number of tasks in the set and test episodes, respectively. In our first contribution, we demonstrate that the latter rate is nearly optimal by developing a novel lower bound for test-time regret minimization under separation, showing that a linear dependence with $M$ is unavoidable. Then, we present a family of stronger yet reasonable assumptions beyond separation, which we call strong identifiability, enabling algorithms achieving fast rates $\log (H)$ and sublinear dependence with $M$ simultaneously. Our paper provides a new understanding of the statistical barriers of test-time regret minimization and when fast rates can be achieved.
RoboArm-NMP: a Learning Environment for Neural Motion Planning
May 25, 2024We present RoboArm-NMP, a learning and evaluation environment that allows simple and thorough evaluations of Neural Motion Planning (NMP) algorithms, focused on robotic manipulators. Our Python-based environment provides baseline implementations for learning control policies (either supervised or reinforcement learning based), a simulator based on PyBullet, data of solved instances using a classical motion planning solver, various representation learning methods for encoding the obstacles, and a clean interface between the learning and planning frameworks. Using RoboArm-NMP, we compare several prominent NMP design points, and demonstrate that the best methods mostly succeed in generalizing to unseen goals in a scene with fixed obstacles, but have difficulty in generalizing to unseen obstacle configurations, suggesting focus points for future research.
Entity-Centric Reinforcement Learning for Object Manipulation from Pixels
Apr 01, 2024



Manipulating objects is a hallmark of human intelligence, and an important task in domains such as robotics. In principle, Reinforcement Learning (RL) offers a general approach to learn object manipulation. In practice, however, domains with more than a few objects are difficult for RL agents due to the curse of dimensionality, especially when learning from raw image observations. In this work we propose a structured approach for visual RL that is suitable for representing multiple objects and their interaction, and use it to learn goal-conditioned manipulation of several objects. Key to our method is the ability to handle goals with dependencies between the objects (e.g., moving objects in a certain order). We further relate our architecture to the generalization capability of the trained agent, based on a theoretical result for compositional generalization, and demonstrate agents that learn with 3 objects but generalize to similar tasks with over 10 objects. Videos and code are available on the project website: https://sites.google.com/view/entity-centric-rl
MAMBA: an Effective World Model Approach for Meta-Reinforcement Learning
Mar 14, 2024Meta-reinforcement learning (meta-RL) is a promising framework for tackling challenging domains requiring efficient exploration. Existing meta-RL algorithms are characterized by low sample efficiency, and mostly focus on low-dimensional task distributions. In parallel, model-based RL methods have been successful in solving partially observable MDPs, of which meta-RL is a special case. In this work, we leverage this success and propose a new model-based approach to meta-RL, based on elements from existing state-of-the-art model-based and meta-RL methods. We demonstrate the effectiveness of our approach on common meta-RL benchmark domains, attaining greater return with better sample efficiency (up to $15\times$) while requiring very little hyperparameter tuning. In addition, we validate our approach on a slate of more challenging, higher-dimensional domains, taking a step towards real-world generalizing agents.