 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAMBA: an Effective World Model Approach for Meta-Reinforcement Learning
Mar 14, 2024Meta-reinforcement learning (meta-RL) is a promising framework for tackling challenging domains requiring efficient exploration. Existing meta-RL algorithms are characterized by low sample efficiency, and mostly focus on low-dimensional task distributions. In parallel, model-based RL methods have been successful in solving partially observable MDPs, of which meta-RL is a special case. In this work, we leverage this success and propose a new model-based approach to meta-RL, based on elements from existing state-of-the-art model-based and meta-RL methods. We demonstrate the effectiveness of our approach on common meta-RL benchmark domains, attaining greater return with better sample efficiency (up to $15\times$) while requiring very little hyperparameter tuning. In addition, we validate our approach on a slate of more challenging, higher-dimensional domains, taking a step towards real-world generalizing agents.
Meta Reinforcement Learning with Finite Training Tasks -- a Density Estimation Approach
Jun 21, 2022

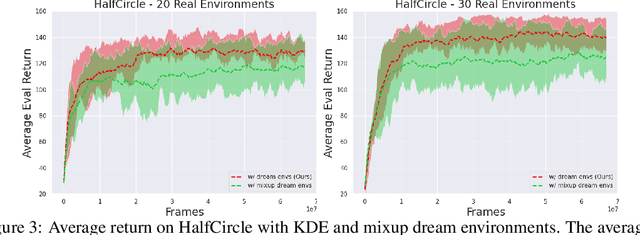

In meta reinforcement learning (meta RL), an agent learns from a set of training tasks how to quickly solve a new task, drawn from the same task distribution. The optimal meta RL policy, a.k.a. the Bayes-optimal behavior, is well defined, and guarantees optimal reward in expectation, taken with respect to the task distribution. The question we explore in this work is how many training tasks are required to guarantee approximately optimal behavior with high probability. Recent work provided the first such PAC analysis for a model-free setting, where a history-dependent policy was learned from the training tasks. In this work, we propose a different approach: directly learn the task distribution, using density estimation techniques, and then train a policy on the learned task distribution. We show that our approach leads to bounds that depend on the dimension of the task distribution. In particular, in settings where the task distribution lies in a low-dimensional manifold, we extend our analysis to use dimensionality reduction techniques and account for such structure, obtaining significantly better bounds than previous work, which strictly depend on the number of states and actions. The key of our approach is the regularization implied by the kernel density estimation method. We further demonstrate that this regularization is useful in practice, when `plugged in' the state-of-the-art VariBAD meta RL algorithm.