 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWISTED-RL: Hierarchical Skilled Agents for Knot-Tying without Human Demonstrations
Feb 16, 2026Robotic knot-tying represents a fundamental challenge in robotics due to the complex interactions between deformable objects and strict topological constraints. We present TWISTED-RL, a framework that improves upon the previous state-of-the-art in demonstration-free knot-tying (TWISTED), which smartly decomposed a single knot-tying problem into manageable subproblems, each addressed by a specialized agent. Our approach replaces TWISTED's single-step inverse model that was learned via supervised learning with a multi-step Reinforcement Learning policy conditioned on abstract topological actions rather than goal states. This change allows more delicate topological state transitions while avoiding costly and ineffective data collection protocols, thus enabling better generalization across diverse knot configurations. Experimental results demonstrate that TWISTED-RL manages to solve previously unattainable knots of higher complexity, including commonly used knots such as the Figure-8 and the Overhand. Furthermore, the increase in success rates and drop in planning time establishes TWISTED-RL as the new state-of-the-art in robotic knot-tying without human demonstrations.
VLM-Guided Experience Replay
Feb 02, 2026Recent advances in Large Language Models (LLMs) and Vision-Language Models (VLMs) have enabled powerful semantic and multimodal reasoning capabilities, creating new opportunities to enhance sample efficiency, high-level planning, and interpretability in reinforcement learning (RL). While prior work has integrated LLMs and VLMs into various components of RL, the replay buffer, a core component for storing and reusing experiences, remains unexplored. We propose addressing this gap by leveraging VLMs to guide the prioritization of experiences in the replay buffer. Our key idea is to use a frozen, pre-trained VLM (requiring no fine-tuning) as an automated evaluator to identify and prioritize promising sub-trajectories from the agent's experiences. Across scenarios, including game-playing and robotics, spanning both discrete and continuous domains, agents trained with our proposed prioritization method achieve 11-52% higher average success rates and improve sample efficiency by 19-45% compared to previous approaches. https://esharony.me/projects/vlm-rb/
Train-Once Plan-Anywhere Kinodynamic Motion Planning via Diffusion Trees
Aug 28, 2025Kinodynamic motion planning is concerned with computing collision-free trajectories while abiding by the robot's dynamic constraints. This critical problem is often tackled using sampling-based planners (SBPs) that explore the robot's high-dimensional state space by constructing a search tree via action propagations. Although SBPs can offer global guarantees on completeness and solution quality, their performance is often hindered by slow exploration due to uninformed action sampling. Learning-based approaches can yield significantly faster runtimes, yet they fail to generalize to out-of-distribution (OOD) scenarios and lack critical guarantees, e.g., safety, thus limiting their deployment on physical robots. We present Diffusion Tree (DiTree): a \emph{provably-generalizable} framework leveraging diffusion policies (DPs) as informed samplers to efficiently guide state-space search within SBPs. DiTree combines DP's ability to model complex distributions of expert trajectories, conditioned on local observations, with the completeness of SBPs to yield \emph{provably-safe} solutions within a few action propagation iterations for complex dynamical systems. We demonstrate DiTree's power with an implementation combining the popular RRT planner with a DP action sampler trained on a \emph{single environment}. In comprehensive evaluations on OOD scenarios, % DiTree has comparable runtimes to a standalone DP (3x faster than classical SBPs), while improving the average success rate over DP and SBPs. DiTree is on average 3x faster than classical SBPs, and outperforms all other approaches by achieving roughly 30\% higher success rate. Project webpage: https://sites.google.com/view/ditree.
RoboArm-NMP: a Learning Environment for Neural Motion Planning
May 25, 2024We present RoboArm-NMP, a learning and evaluation environment that allows simple and thorough evaluations of Neural Motion Planning (NMP) algorithms, focused on robotic manipulators. Our Python-based environment provides baseline implementations for learning control policies (either supervised or reinforcement learning based), a simulator based on PyBullet, data of solved instances using a classical motion planning solver, various representation learning methods for encoding the obstacles, and a clean interface between the learning and planning frameworks. Using RoboArm-NMP, we compare several prominent NMP design points, and demonstrate that the best methods mostly succeed in generalizing to unseen goals in a scene with fixed obstacles, but have difficulty in generalizing to unseen obstacle configurations, suggesting focus points for future research.
MAMBA: an Effective World Model Approach for Meta-Reinforcement Learning
Mar 14, 2024Meta-reinforcement learning (meta-RL) is a promising framework for tackling challenging domains requiring efficient exploration. Existing meta-RL algorithms are characterized by low sample efficiency, and mostly focus on low-dimensional task distributions. In parallel, model-based RL methods have been successful in solving partially observable MDPs, of which meta-RL is a special case. In this work, we leverage this success and propose a new model-based approach to meta-RL, based on elements from existing state-of-the-art model-based and meta-RL methods. We demonstrate the effectiveness of our approach on common meta-RL benchmark domains, attaining greater return with better sample efficiency (up to $15\times$) while requiring very little hyperparameter tuning. In addition, we validate our approach on a slate of more challenging, higher-dimensional domains, taking a step towards real-world generalizing agents.
Fine-Tuning Generative Models as an Inference Method for Robotic Tasks
Oct 19, 2023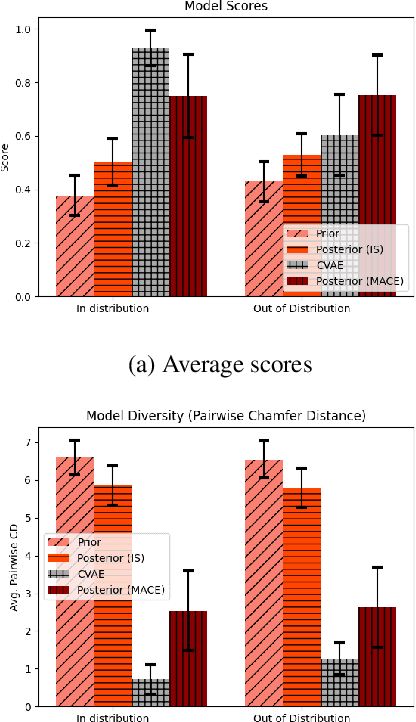
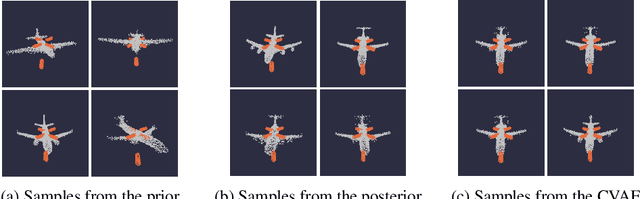

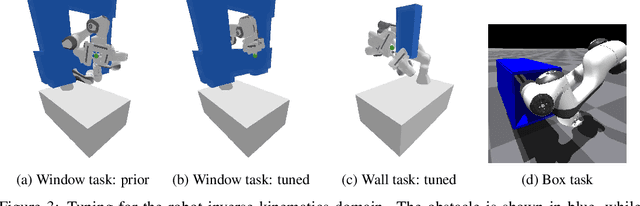
Adaptable models could greatly benefit robotic agents operating in the real world, allowing them to deal with novel and varying conditions. While approaches such as Bayesian inference are well-studied frameworks for adapting models to evidence, we build on recent advances in deep generative models which have greatly affected many areas of robotics. Harnessing modern GPU acceleration, we investigate how to quickly adapt the sample generation of neural network models to observations in robotic tasks. We propose a simple and general method that is applicable to various deep generative models and robotic environments. The key idea is to quickly fine-tune the model by fitting it to generated samples matching the observed evidence, using the cross-entropy method. We show that our method can be applied to both autoregressive models and variational autoencoders, and demonstrate its usability in object shape inference from grasping, inverse kinematics calculation, and point cloud completion.
Goal-Conditioned Supervised Learning with Sub-Goal Prediction
May 17, 2023Recently, a simple yet effective algorithm -- goal-conditioned supervised-learning (GCSL) -- was proposed to tackle goal-conditioned reinforcement-learning. GCSL is based on the principle of hindsight learning: by observing states visited in previously executed trajectories and treating them as attained goals, GCSL learns the corresponding actions via supervised learning. However, GCSL only learns a goal-conditioned policy, discarding other information in the process. Our insight is that the same hindsight principle can be used to learn to predict goal-conditioned sub-goals from the same trajectory. Based on this idea, we propose Trajectory Iterative Learner (TraIL), an extension of GCSL that further exploits the information in a trajectory, and uses it for learning to predict both actions and sub-goals. We investigate the settings in which TraIL can make better use of the data, and discover that for several popular problem settings, replacing real goals in GCSL with predicted TraIL sub-goals allows the agent to reach a greater set of goal states using the exact same data as GCSL, thereby improving its overall performance.
Sub-Goal Trees -- a Framework for Goal-Based Reinforcement Learning
Feb 27, 2020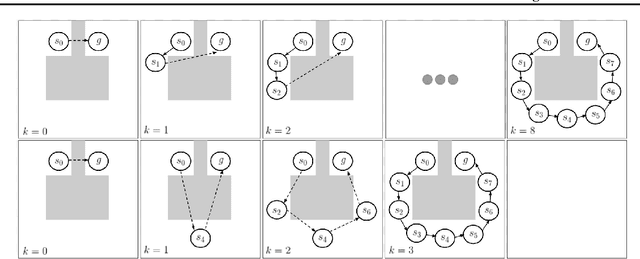
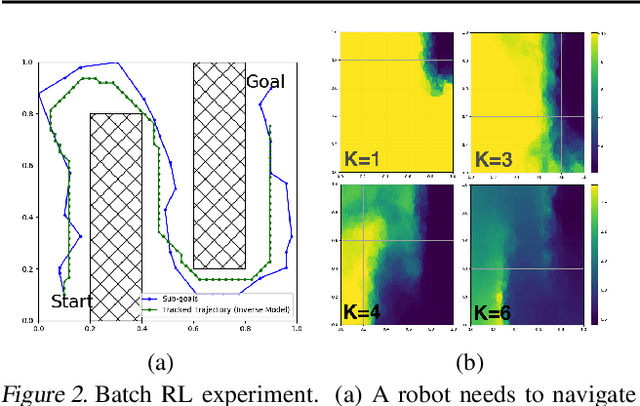

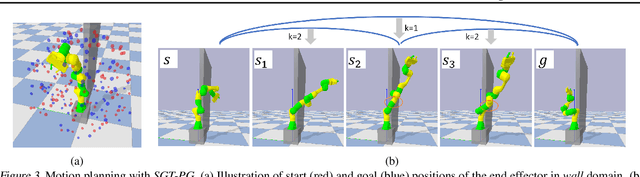
Many AI problems, in robotics and other domains, are goal-based, essentially seeking trajectories leading to various goal states. Reinforcement learning (RL), building on Bellman's optimality equation, naturally optimizes for a single goal, yet can be made multi-goal by augmenting the state with the goal. Instead, we propose a new RL framework, derived from a dynamic programming equation for the all pairs shortest path (APSP) problem, which naturally solves multi-goal queries. We show that this approach has computational benefits for both standard and approximate dynamic programming. Interestingly, our formulation prescribes a novel protocol for computing a trajectory: instead of predicting the next state given its predecessor, as in standard RL, a goal-conditioned trajectory is constructed by first predicting an intermediate state between start and goal, partitioning the trajectory into two. Then, recursively, predicting intermediate points on each sub-segment, until a complete trajectory is obtained. We call this trajectory structure a sub-goal tree. Building on it, we additionally extend the policy gradient methodology to recursively predict sub-goals, resulting in novel goal-based algorithms. Finally, we apply our method to neural motion planning, where we demonstrate significant improvements compared to standard RL on navigating a 7-DoF robot arm between obstacles.
Sub-Goal Trees -- a Framework for Goal-Directed Trajectory Prediction and Optimization
Jun 12, 2019


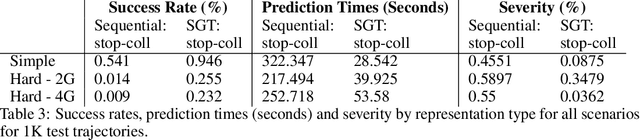
Many AI problems, in robotics and other domains, are goal-directed, essentially seeking a trajectory leading to some goal state. In such problems, the way we choose to represent a trajectory underlies algorithms for trajectory prediction and optimization. Interestingly, most all prior work in imitation and reinforcement learning builds on a sequential trajectory representation -- calculating the next state in the trajectory given its predecessors. We propose a different perspective: a goal-conditioned trajectory can be represented by first selecting an intermediate state between start and goal, partitioning the trajectory into two. Then, recursively, predicting intermediate points on each sub-segment, until a complete trajectory is obtained. We call this representation a sub-goal tree, and building on it, we develop new methods for trajectory prediction, learning, and optimization. We show that in a supervised learning setting, sub-goal trees better account for trajectory variability, and can predict trajectories exponentially faster at test time by leveraging a concurrent computation. Then, for optimization, we derive a new dynamic programming equation for sub-goal trees, and use it to develop new planning and reinforcement learning algorithms. These algorithms, which are not based on the standard Bellman equation, naturally account for hierarchical sub-goal structure in a task. Empirical results on motion planning domains show that the sub-goal tree framework significantly improves both accuracy and prediction time.
Harnessing Reinforcement Learning for Neural Motion Planning
Jun 01, 2019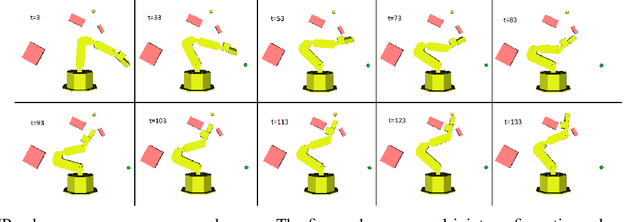

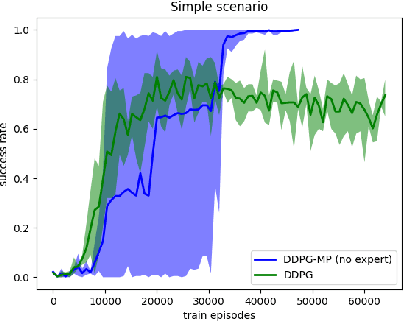
Motion planning is an essential component in most of today's robotic applications. In this work, we consider the learning setting, where a set of solved motion planning problems is used to improve the efficiency of motion planning on different, yet similar problems. This setting is important in applications with rapidly changing environments such as in e-commerce, among others. We investigate a general deep learning based approach, where a neural network is trained to map an image of the domain, the current robot state, and a goal robot state to the next robot state in the plan. We focus on the learning algorithm, and compare supervised learning methods with reinforcement learning (RL) algorithms. We first establish that supervised learning approaches are inferior in their accuracy due to insufficient data on the boundary of the obstacles, an issue that RL methods mitigate by actively exploring the domain. We then propose a modification of the popular DDPG RL algorithm that is tailored to motion planning domains, by exploiting the known model in the problem and the set of solved plans in the data. We show that our algorithm, dubbed DDPG-MP, significantly improves the accuracy of the learned motion planning policy. Finally, we show that given enough training data, our method can plan significantly faster on novel domains than off-the-shelf sampling based motion planners. Results of our experiments are shown in https://youtu.be/wHQ4Y4mBRb8.