 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLM-Guided Experience Replay
Feb 02, 2026Recent advances in Large Language Models (LLMs) and Vision-Language Models (VLMs) have enabled powerful semantic and multimodal reasoning capabilities, creating new opportunities to enhance sample efficiency, high-level planning, and interpretability in reinforcement learning (RL). While prior work has integrated LLMs and VLMs into various components of RL, the replay buffer, a core component for storing and reusing experiences, remains unexplored. We propose addressing this gap by leveraging VLMs to guide the prioritization of experiences in the replay buffer. Our key idea is to use a frozen, pre-trained VLM (requiring no fine-tuning) as an automated evaluator to identify and prioritize promising sub-trajectories from the agent's experiences. Across scenarios, including game-playing and robotics, spanning both discrete and continuous domains, agents trained with our proposed prioritization method achieve 11-52% higher average success rates and improve sample efficiency by 19-45% compared to previous approaches. https://esharony.me/projects/vlm-rb/
MAMBA: an Effective World Model Approach for Meta-Reinforcement Learning
Mar 14, 2024Meta-reinforcement learning (meta-RL) is a promising framework for tackling challenging domains requiring efficient exploration. Existing meta-RL algorithms are characterized by low sample efficiency, and mostly focus on low-dimensional task distributions. In parallel, model-based RL methods have been successful in solving partially observable MDPs, of which meta-RL is a special case. In this work, we leverage this success and propose a new model-based approach to meta-RL, based on elements from existing state-of-the-art model-based and meta-RL methods. We demonstrate the effectiveness of our approach on common meta-RL benchmark domains, attaining greater return with better sample efficiency (up to $15\times$) while requiring very little hyperparameter tuning. In addition, we validate our approach on a slate of more challenging, higher-dimensional domains, taking a step towards real-world generalizing agents.
Fine-Tuning Generative Models as an Inference Method for Robotic Tasks
Oct 19, 2023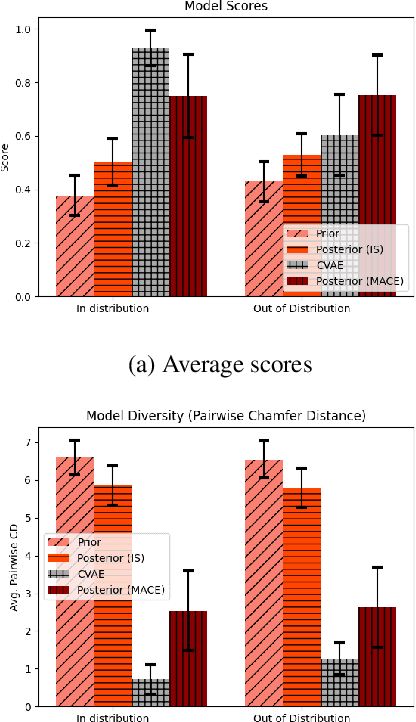
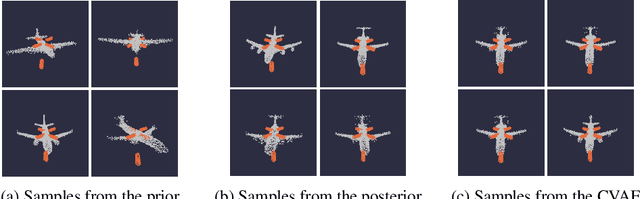

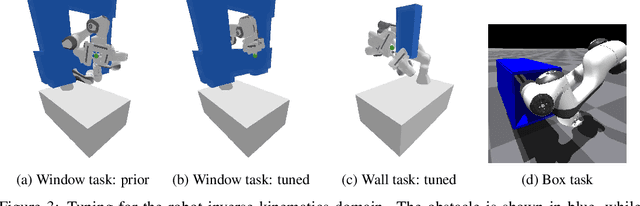
Adaptable models could greatly benefit robotic agents operating in the real world, allowing them to deal with novel and varying conditions. While approaches such as Bayesian inference are well-studied frameworks for adapting models to evidence, we build on recent advances in deep generative models which have greatly affected many areas of robotics. Harnessing modern GPU acceleration, we investigate how to quickly adapt the sample generation of neural network models to observations in robotic tasks. We propose a simple and general method that is applicable to various deep generative models and robotic environments. The key idea is to quickly fine-tune the model by fitting it to generated samples matching the observed evidence, using the cross-entropy method. We show that our method can be applied to both autoregressive models and variational autoencoders, and demonstrate its usability in object shape inference from grasping, inverse kinematics calculation, and point cloud completion.
Multi Agent Reinforcement Learning with Multi-Step Generative Models
Jan 29, 2019

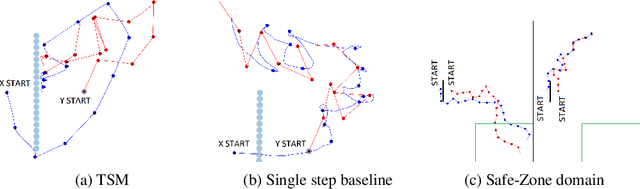

The dynamics between agents and the environment are an important component of multi-agent Reinforcement Learning (RL), and learning them provides a basis for decision making. However, a major challenge in optimizing a learned dynamics model is the accumulation of error when predicting multiple steps into the future. Recent advances in variational inference provide model based solutions that predict complete trajectory segments, and optimize over a latent representation of trajectories. For single-agent scenarios, several recent studies have explored this idea, and showed its benefits over conventional methods. In this work, we extend this approach to the multi-agent case, and effectively optimize over a latent space that encodes multi-agent strategies. We discuss the challenges in optimizing over a latent variable model for multiple agents, both in the optimization algorithm and in the model representation, and propose a method for both cooperative and competitive settings based on risk-sensitive optimization. We evaluate our method on tasks in the multi-agent particle environment and on a simulated RoboCup domain.