 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian Approach to Online Planning
Jun 04, 2024


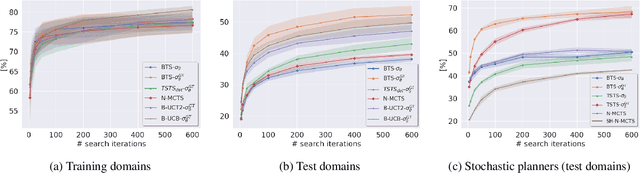
The combination of Monte Carlo tree search and neural networks has revolutionized online planning. As neural network approximations are often imperfect, we ask whether uncertainty estimates about the network outputs could be used to improve planning. We develop a Bayesian planning approach that facilitates such uncertainty quantification, inspired by classical ideas from the meta-reasoning literature. We propose a Thompson sampling based algorithm for searching the tree of possible actions, for which we prove the first (to our knowledge) finite time Bayesian regret bound, and propose an efficient implementation for a restricted family of posterior distributions. In addition we propose a variant of the Bayes-UCB method applied to trees. Empirically, we demonstrate that on the ProcGen Maze and Leaper environments, when the uncertainty estimates are accurate but the neural network output is inaccurate, our Bayesian approach searches the tree much more effectively. In addition, we investigate whether popular uncertainty estimation methods are accurate enough to yield significant gains in planning. Our code is available at: https://github.com/nirgreshler/bayesian-online-planning.
Unsupervised Feature Learning for Manipulation with Contrastive Domain Randomization
Mar 20, 2021
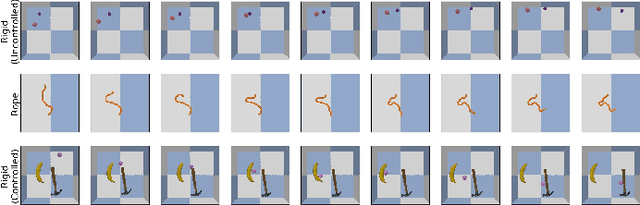

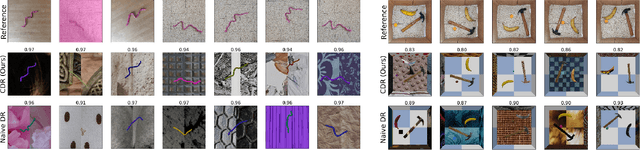
Robotic tasks such as manipulation with visual inputs require image features that capture the physical properties of the scene, e.g., the position and configuration of objects. Recently, it has been suggested to learn such features in an unsupervised manner from simulated, self-supervised, robot interaction; the idea being that high-level physical properties are well captured by modern physical simulators, and their representation from visual inputs may transfer well to the real world. In particular, learning methods based on noise contrastive estimation have shown promising results. To robustify the simulation-to-real transfer, domain randomization (DR) was suggested for learning features that are invariant to irrelevant visual properties such as textures or lighting. In this work, however, we show that a naive application of DR to unsupervised learning based on contrastive estimation does not promote invariance, as the loss function maximizes mutual information between the features and both the relevant and irrelevant visual properties. We propose a simple modification of the contrastive loss to fix this, exploiting the fact that we can control the simulated randomization of visual properties. Our approach learns physical features that are significantly more robust to visual domain variation, as we demonstrate using both rigid and non-rigid objects.
PERL: Pivot-based Domain Adaptation for Pre-trained Deep Contextualized Embedding Models
Jun 16, 2020
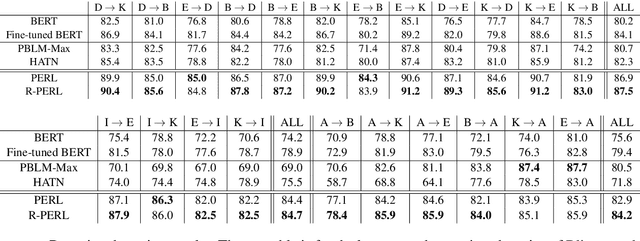


Pivot-based neural representation models have lead to significant progress in domain adaptation for NLP. However, previous works that follow this approach utilize only labeled data from the source domain and unlabeled data from the source and target domains, but neglect to incorporate massive unlabeled corpora that are not necessarily drawn from these domains. To alleviate this, we propose PERL: A representation learning model that extends contextualized word embedding models such as BERT with pivot-based fine-tuning. PERL outperforms strong baselines across 22 sentiment classification domain adaptation setups, improves in-domain model performance, yields effective reduced-size models and increases model stability.