 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwiLTra-Bench: The Swiss Legal Translation Benchmark
Mar 03, 2025In Switzerland legal translation is uniquely important due to the country's four official languages and requirements for multilingual legal documentation. However, this process traditionally relies on professionals who must be both legal experts and skilled translators -- creating bottlenecks and impacting effective access to justice. To address this challenge, we introduce SwiLTra-Bench, a comprehensive multilingual benchmark of over 180K aligned Swiss legal translation pairs comprising laws, headnotes, and press releases across all Swiss languages along with English, designed to evaluate LLM-based translation systems. Our systematic evaluation reveals that frontier models achieve superior translation performance across all document types, while specialized translation systems excel specifically in laws but under-perform in headnotes. Through rigorous testing and human expert validation, we demonstrate that while fine-tuning open SLMs significantly improves their translation quality, they still lag behind the best zero-shot prompted frontier models such as Claude-3.5-Sonnet. Additionally, we present SwiLTra-Judge, a specialized LLM evaluation system that aligns best with human expert assessments.
Unsupervised Feature Learning for Manipulation with Contrastive Domain Randomization
Mar 20, 2021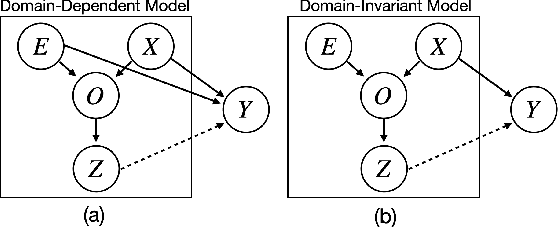
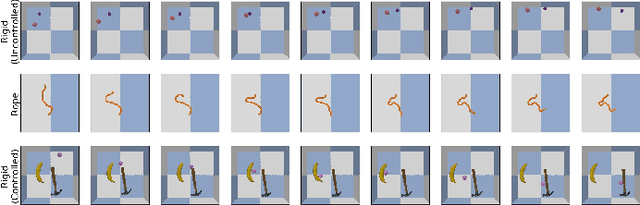

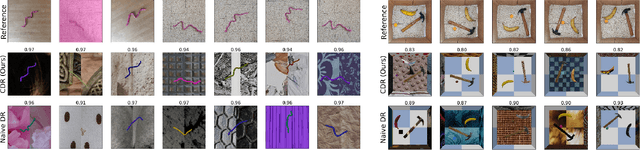
Robotic tasks such as manipulation with visual inputs require image features that capture the physical properties of the scene, e.g., the position and configuration of objects. Recently, it has been suggested to learn such features in an unsupervised manner from simulated, self-supervised, robot interaction; the idea being that high-level physical properties are well captured by modern physical simulators, and their representation from visual inputs may transfer well to the real world. In particular, learning methods based on noise contrastive estimation have shown promising results. To robustify the simulation-to-real transfer, domain randomization (DR) was suggested for learning features that are invariant to irrelevant visual properties such as textures or lighting. In this work, however, we show that a naive application of DR to unsupervised learning based on contrastive estimation does not promote invariance, as the loss function maximizes mutual information between the features and both the relevant and irrelevant visual properties. We propose a simple modification of the contrastive loss to fix this, exploiting the fact that we can control the simulated randomization of visual properties. Our approach learns physical features that are significantly more robust to visual domain variation, as we demonstrate using both rigid and non-rigid objects.