 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-DLP: Self-Supervised 3D Object-Centric Scene Representation Learning
Jun 17, 2026We introduce 3D-DLP, a self-supervised object-centric representation learning model that decomposes scene-level RGB-D or voxel observations into a set of 3D latent particles. Building on the Deep Latent Particles (DLP) framework, each particle encodes disentangled attributes, including 3D keypoint position, bounding box dimensions, and appearance features, and represents a distinct entity in the scene. The model learns interpretable per-particle segmentation maps through an end-to-end self-supervised reconstruction objective. We demonstrate on both simulated and real-world datasets that the learned latent space is interpretable and controllable: by manipulating particle positions and decoding, we can generate novel scene configurations. Furthermore, we show that leveraging these compact 3D latent particles for downstream robotic manipulation improves performance over baselines that either lack explicit 3D information or rely on memory-intensive dense 3D inputs without object-centric structure. Code and videos are available at https://eubooks3003.github.io/3d-dlp.
Latent Particle World Models: Self-supervised Object-centric Stochastic Dynamics Modeling
Mar 04, 2026We introduce Latent Particle World Model (LPWM), a self-supervised object-centric world model scaled to real-world multi-object datasets and applicable in decision-making. LPWM autonomously discovers keypoints, bounding boxes, and object masks directly from video data, enabling it to learn rich scene decompositions without supervision. Our architecture is trained end-to-end purely from videos and supports flexible conditioning on actions, language, and image goals. LPWM models stochastic particle dynamics via a novel latent action module and achieves state-of-the-art results on diverse real-world and synthetic datasets. Beyond stochastic video modeling, LPWM is readily applicable to decision-making, including goal-conditioned imitation learning, as we demonstrate in the paper. Code, data, pre-trained models and video rollouts are available: https://taldatech.github.io/lpwm-web
Hierarchical Entity-centric Reinforcement Learning with Factored Subgoal Diffusion
Feb 02, 2026We propose a hierarchical entity-centric framework for offline Goal-Conditioned Reinforcement Learning (GCRL) that combines subgoal decomposition with factored structure to solve long-horizon tasks in domains with multiple entities. Achieving long-horizon goals in complex environments remains a core challenge in Reinforcement Learning (RL). Domains with multiple entities are particularly difficult due to their combinatorial complexity. GCRL facilitates generalization across goals and the use of subgoal structure, but struggles with high-dimensional observations and combinatorial state-spaces, especially under sparse reward. We employ a two-level hierarchy composed of a value-based GCRL agent and a factored subgoal-generating conditional diffusion model. The RL agent and subgoal generator are trained independently and composed post hoc through selective subgoal generation based on the value function, making the approach modular and compatible with existing GCRL algorithms. We introduce new variations to benchmark tasks that highlight the challenges of multi-entity domains, and show that our method consistently boosts performance of the underlying RL agent on image-based long-horizon tasks with sparse rewards, achieving over 150% higher success rates on the hardest task in our suite and generalizing to increasing horizons and numbers of entities. Rollout videos are provided at: https://sites.google.com/view/hecrl
EC-Diffuser: Multi-Object Manipulation via Entity-Centric Behavior Generation
Dec 25, 2024



Object manipulation is a common component of everyday tasks, but learning to manipulate objects from high-dimensional observations presents significant challenges. These challenges are heightened in multi-object environments due to the combinatorial complexity of the state space as well as of the desired behaviors. While recent approaches have utilized large-scale offline data to train models from pixel observations, achieving performance gains through scaling, these methods struggle with compositional generalization in unseen object configurations with constrained network and dataset sizes. To address these issues, we propose a novel behavioral cloning (BC) approach that leverages object-centric representations and an entity-centric Transformer with diffusion-based optimization, enabling efficient learning from offline image data. Our method first decomposes observations into an object-centric representation, which is then processed by our entity-centric Transformer that computes attention at the object level, simultaneously predicting object dynamics and the agent's actions. Combined with the ability of diffusion models to capture multi-modal behavior distributions, this results in substantial performance improvements in multi-object tasks and, more importantly, enables compositional generalization. We present BC agents capable of zero-shot generalization to tasks with novel compositions of objects and goals, including larger numbers of objects than seen during training. We provide video rollouts on our webpage: https://sites.google.com/view/ec-diffuser.
Entity-Centric Reinforcement Learning for Object Manipulation from Pixels
Apr 01, 2024



Manipulating objects is a hallmark of human intelligence, and an important task in domains such as robotics. In principle, Reinforcement Learning (RL) offers a general approach to learn object manipulation. In practice, however, domains with more than a few objects are difficult for RL agents due to the curse of dimensionality, especially when learning from raw image observations. In this work we propose a structured approach for visual RL that is suitable for representing multiple objects and their interaction, and use it to learn goal-conditioned manipulation of several objects. Key to our method is the ability to handle goals with dependencies between the objects (e.g., moving objects in a certain order). We further relate our architecture to the generalization capability of the trained agent, based on a theoretical result for compositional generalization, and demonstrate agents that learn with 3 objects but generalize to similar tasks with over 10 objects. Videos and code are available on the project website: https://sites.google.com/view/entity-centric-rl
DDLP: Unsupervised Object-Centric Video Prediction with Deep Dynamic Latent Particles
Jun 09, 2023

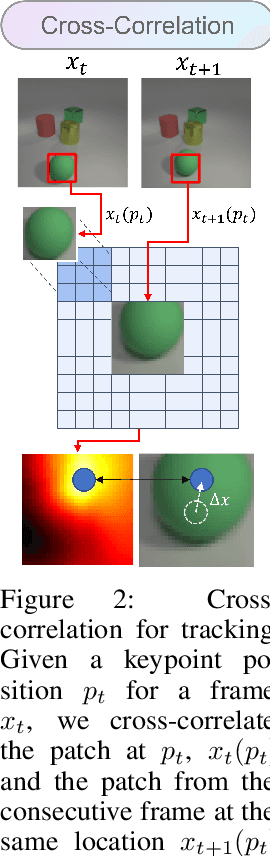

We propose a new object-centric video prediction algorithm based on the deep latent particle (DLP) representation. In comparison to existing slot- or patch-based representations, DLPs model the scene using a set of keypoints with learned parameters for properties such as position and size, and are both efficient and interpretable. Our method, deep dynamic latent particles (DDLP), yields state-of-the-art object-centric video prediction results on several challenging datasets. The interpretable nature of DDLP allows us to perform ``what-if'' generation -- predict the consequence of changing properties of objects in the initial frames, and DLP's compact structure enables efficient diffusion-based unconditional video generation. Videos, code and pre-trained models are available: https://taldatech.github.io/ddlp-web
Unsupervised Image Representation Learning with Deep Latent Particles
May 31, 2022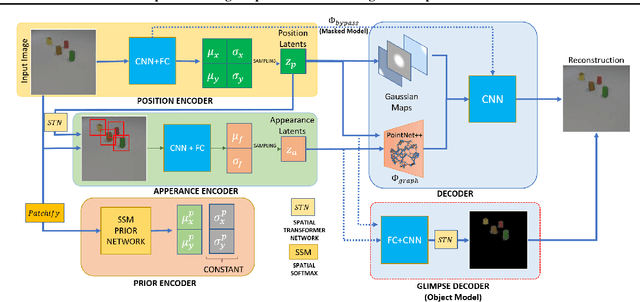
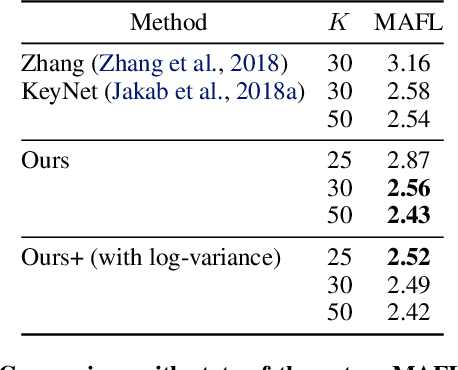


We propose a new representation of visual data that disentangles object position from appearance. Our method, termed Deep Latent Particles (DLP), decomposes the visual input into low-dimensional latent ``particles'', where each particle is described by its spatial location and features of its surrounding region. To drive learning of such representations, we follow a VAE-based approach and introduce a prior for particle positions based on a spatial-softmax architecture, and a modification of the evidence lower bound loss inspired by the Chamfer distance between particles. We demonstrate that our DLP representations are useful for downstream tasks such as unsupervised keypoint (KP) detection, image manipulation, and video prediction for scenes composed of multiple dynamic objects. In addition, we show that our probabilistic interpretation of the problem naturally provides uncertainty estimates for particle locations, which can be used for model selection, among other tasks. Videos and code are available: https://taldatech.github.io/deep-latent-particles-web/
Soft-IntroVAE: Analyzing and Improving the Introspective Variational Autoencoder
Dec 24, 2020

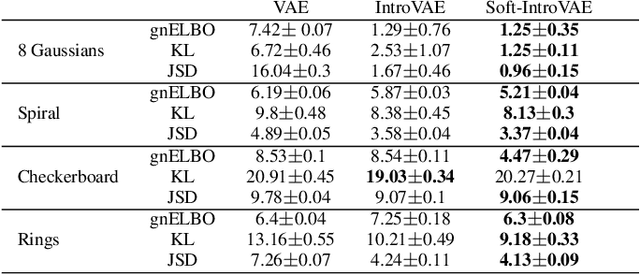
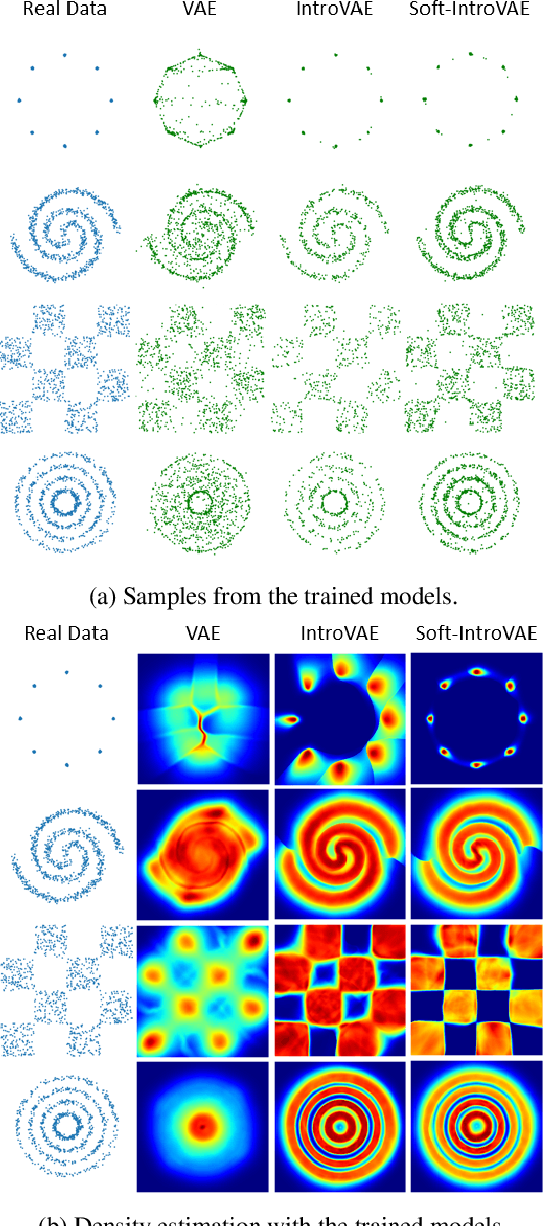
The recently introduced introspective variational autoencoder (IntroVAE) exhibits outstanding image generations, and allows for amortized inference using an image encoder. The main idea in IntroVAE is to train a VAE adversarially, using the VAE encoder to discriminate between generated and real data samples. However, the original IntroVAE loss function relied on a particular hinge-loss formulation that is very hard to stabilize in practice, and its theoretical convergence analysis ignored important terms in the loss. In this work, we take a step towards better understanding of the IntroVAE model, its practical implementation, and its applications. We propose the Soft-IntroVAE, a modified IntroVAE that replaces the hinge-loss terms with a smooth exponential loss on generated samples. This change significantly improves training stability, and also enables theoretical analysis of the complete algorithm. Interestingly, we show that the IntroVAE converges to a distribution that minimizes a sum of KL distance from the data distribution and an entropy term. We discuss the implications of this result, and demonstrate that it induces competitive image generation and reconstruction. Finally, we describe two applications of Soft-IntroVAE to unsupervised image translation and out-of-distribution detection, and demonstrate compelling results. Code and additional information is available on the project website -- https://taldatech.github.io/soft-intro-vae-web
Deep Variational Semi-Supervised Novelty Detection
Nov 12, 2019
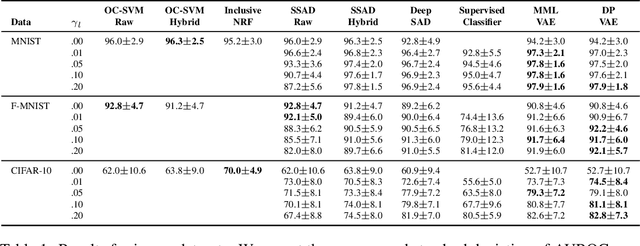

In anomaly detection (AD), one seeks to identify whether a test sample is abnormal, given a data set of normal samples. A recent and promising approach to AD relies on deep generative models, such as variational autoencoders (VAEs), for unsupervised learning of the normal data distribution. In semi-supervised AD (SSAD), the data also includes a small sample of labeled anomalies. In this work, we propose two variational methods for training VAEs for SSAD. The intuitive idea in both methods is to train the encoder to `separate' between latent vectors for normal and outlier data. We show that this idea can be derived from principled probabilistic formulations of the problem, and propose simple and effective algorithms. Our methods can be applied to various data types, as we demonstrate on SSAD datasets ranging from natural images to astronomy and medicine, and can be combined with any VAE model architecture. When comparing to state-of-the-art SSAD methods that are not specific to particular data types, we obtain marked improvement in outlier detection.