 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMastering Atari Games with Limited Data
Oct 30, 2021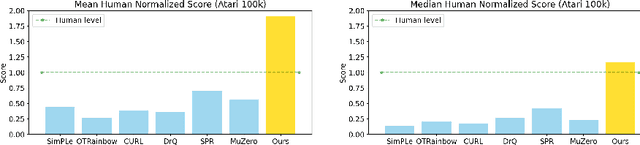
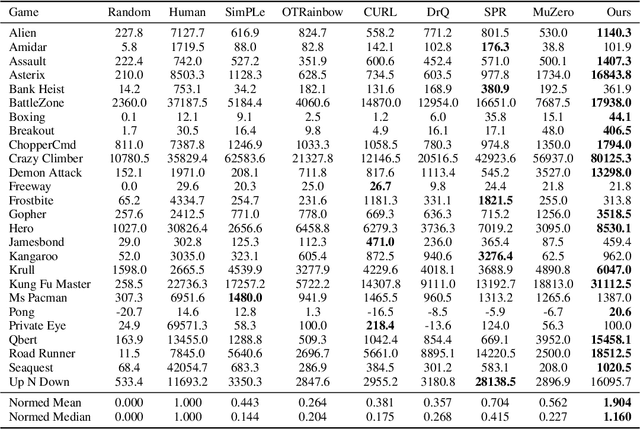
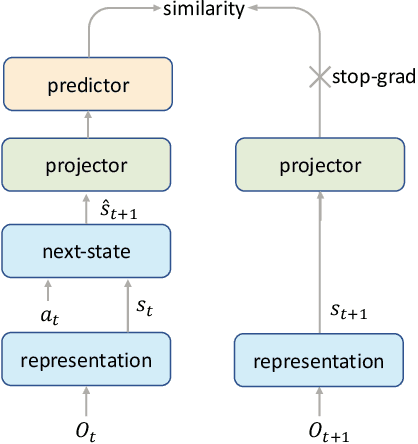

Reinforcement learning has achieved great success in many applications. However, sample efficiency remains a key challenge, with prominent methods requiring millions (or even billions) of environment steps to train. Recently, there has been significant progress in sample efficient image-based RL algorithms; however, consistent human-level performance on the Atari game benchmark remains an elusive goal. We propose a sample efficient model-based visual RL algorithm built on MuZero, which we name EfficientZero. Our method achieves 190.4% mean human performance and 116.0% median performance on the Atari 100k benchmark with only two hours of real-time game experience and outperforms the state SAC in some tasks on the DMControl 100k benchmark. This is the first time an algorithm achieves super-human performance on Atari games with such little data. EfficientZero's performance is also close to DQN's performance at 200 million frames while we consume 500 times less data. EfficientZero's low sample complexity and high performance can bring RL closer to real-world applicability. We implement our algorithm in an easy-to-understand manner and it is available at https://github.com/YeWR/EfficientZero. We hope it will accelerate the research of MCTS-based RL algorithms in the wider community.
Trajectory-wise Multiple Choice Learning for Dynamics Generalization in Reinforcement Learning
Oct 26, 2020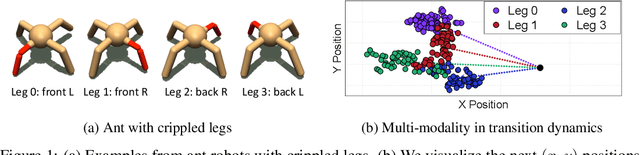
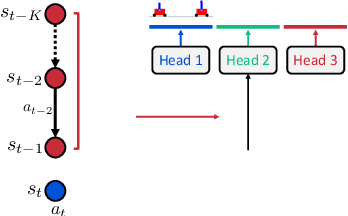
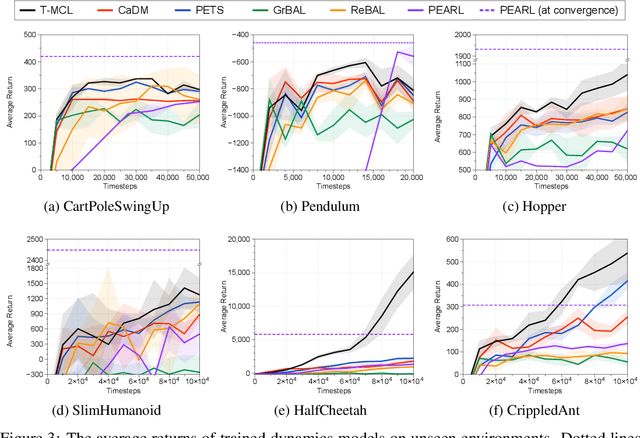

Model-based reinforcement learning (RL) has shown great potential in various control tasks in terms of both sample-efficiency and final performance. However, learning a generalizable dynamics model robust to changes in dynamics remains a challenge since the target transition dynamics follow a multi-modal distribution. In this paper, we present a new model-based RL algorithm, coined trajectory-wise multiple choice learning, that learns a multi-headed dynamics model for dynamics generalization. The main idea is updating the most accurate prediction head to specialize each head in certain environments with similar dynamics, i.e., clustering environments. Moreover, we incorporate context learning, which encodes dynamics-specific information from past experiences into the context latent vector, enabling the model to perform online adaptation to unseen environments. Finally, to utilize the specialized prediction heads more effectively, we propose an adaptive planning method, which selects the most accurate prediction head over a recent experience. Our method exhibits superior zero-shot generalization performance across a variety of control tasks, compared to state-of-the-art RL methods. Source code and videos are available at https://sites.google.com/view/trajectory-mcl.
Sparse Graphical Memory for Robust Planning
Mar 13, 2020

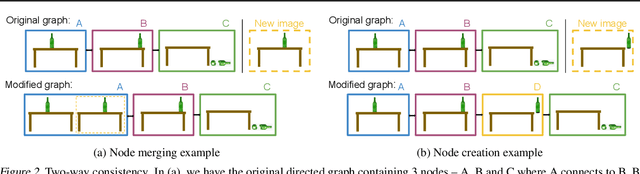
To operate effectively in the real world, artificial agents must act from raw sensory input such as images and achieve diverse goals across long time-horizons. On the one hand, recent strides in deep reinforcement and imitation learning have demonstrated impressive ability to learn goal-conditioned policies from high-dimensional image input, though only for short-horizon tasks. On the other hand, classical graphical methods like A* search are able to solve long-horizon tasks, but assume that the graph structure is abstracted away from raw sensory input and can only be constructed with task-specific priors. We wish to combine the strengths of deep learning and classical planning to solve long-horizon tasks from raw sensory input. To this end, we introduce Sparse Graphical Memory (SGM), a new data structure that stores observations and feasible transitions in a sparse memory. SGM can be combined with goal-conditioned RL or imitative agents to solve long-horizon tasks across a diverse set of domains. We show that SGM significantly outperforms current state of the art methods on long-horizon, sparse-reward visual navigation tasks. Project video and code are available at https://mishalaskin.github.io/sgm/
Hallucinative Topological Memory for Zero-Shot Visual Planning
Feb 27, 2020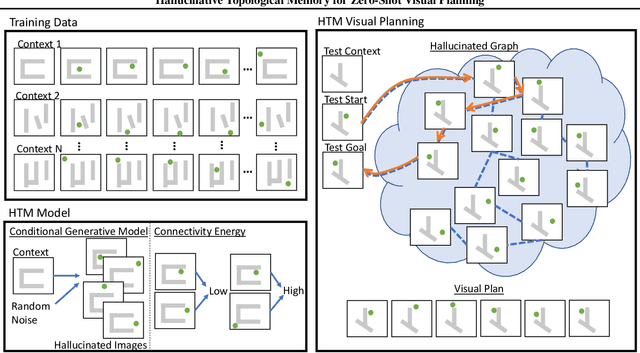
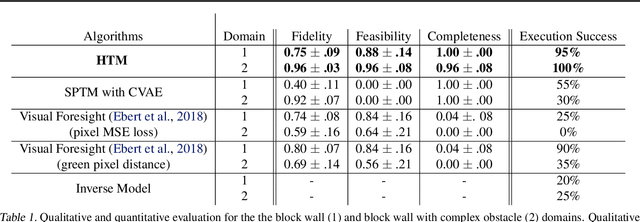
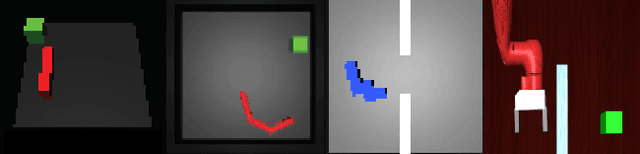
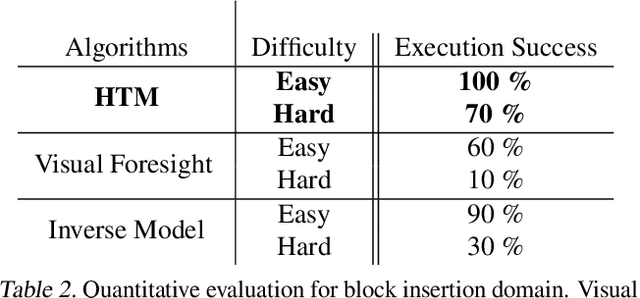
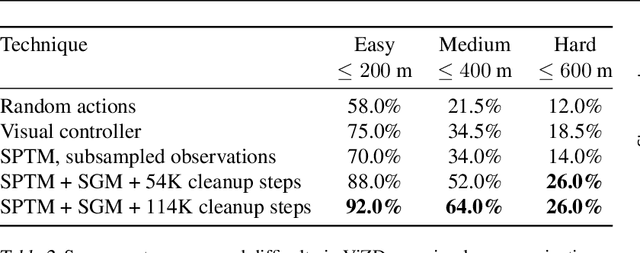
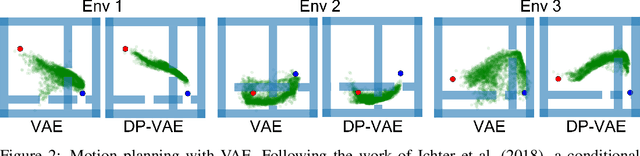
In visual planning (VP), an agent learns to plan goal-directed behavior from observations of a dynamical system obtained offline, e.g., images obtained from self-supervised robot interaction. Most previous works on VP approached the problem by planning in a learned latent space, resulting in low-quality visual plans, and difficult training algorithms. Here, instead, we propose a simple VP method that plans directly in image space and displays competitive performance. We build on the semi-parametric topological memory (SPTM) method: image samples are treated as nodes in a graph, the graph connectivity is learned from image sequence data, and planning can be performed using conventional graph search methods. We propose two modifications on SPTM. First, we train an energy-based graph connectivity function using contrastive predictive coding that admits stable training. Second, to allow zero-shot planning in new domains, we learn a conditional VAE model that generates images given a context of the domain, and use these hallucinated samples for building the connectivity graph and planning. We show that this simple approach significantly outperform the state-of-the-art VP methods, in terms of both plan interpretability and success rate when using the plan to guide a trajectory-following controller. Interestingly, our method can pick up non-trivial visual properties of objects, such as their geometry, and account for it in the plans.
Deep Variational Semi-Supervised Novelty Detection
Nov 12, 2019
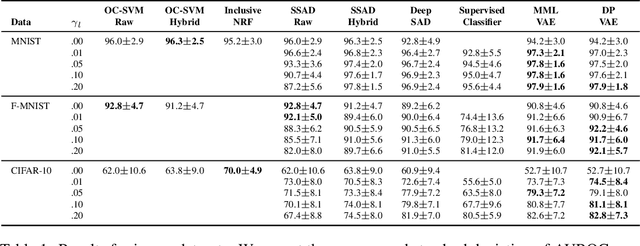

In anomaly detection (AD), one seeks to identify whether a test sample is abnormal, given a data set of normal samples. A recent and promising approach to AD relies on deep generative models, such as variational autoencoders (VAEs), for unsupervised learning of the normal data distribution. In semi-supervised AD (SSAD), the data also includes a small sample of labeled anomalies. In this work, we propose two variational methods for training VAEs for SSAD. The intuitive idea in both methods is to train the encoder to `separate' between latent vectors for normal and outlier data. We show that this idea can be derived from principled probabilistic formulations of the problem, and propose simple and effective algorithms. Our methods can be applied to various data types, as we demonstrate on SSAD datasets ranging from natural images to astronomy and medicine, and can be combined with any VAE model architecture. When comparing to state-of-the-art SSAD methods that are not specific to particular data types, we obtain marked improvement in outlier detection.
Learning to Manipulate Deformable Objects without Demonstrations
Oct 29, 2019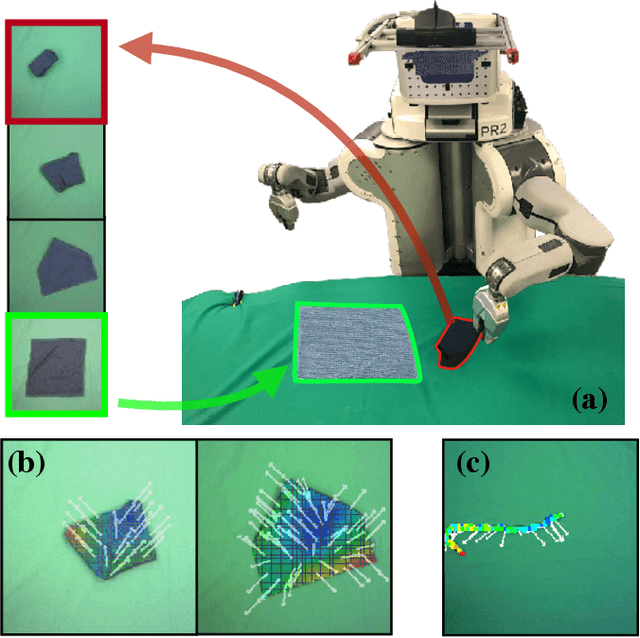

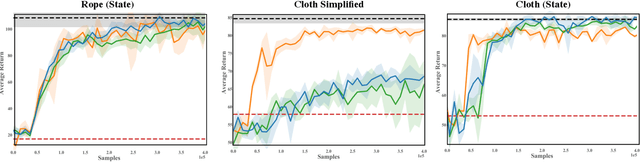
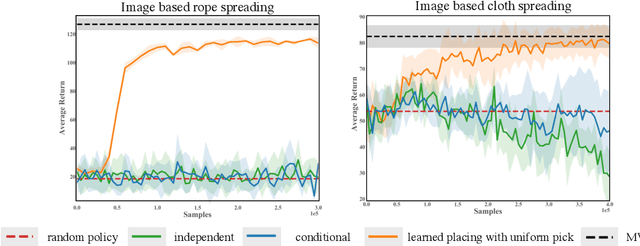
In this paper we tackle the problem of deformable object manipulation through model-free visual reinforcement learning (RL). In order to circumvent the sample inefficiency of RL, we propose two key ideas that accelerate learning. First, we propose an iterative pick-place action space that encodes the conditional relationship between picking and placing on deformable objects. The explicit structural encoding enables faster learning under complex object dynamics. Second, instead of jointly learning both the pick and the place locations, we only explicitly learn the placing policy conditioned on random pick points. Then, by selecting the pick point that has Maximal Value under Placing (MVP), we obtain our picking policy. Using this learning framework, we obtain an order of magnitude faster learning compared to independent action-spaces on our suite of deformable object manipulation tasks. Finally, using domain randomization, we transfer our policies to a real PR2 robot for challenging cloth and rope manipulation.
Learning Robotic Manipulation through Visual Planning and Acting
May 11, 2019
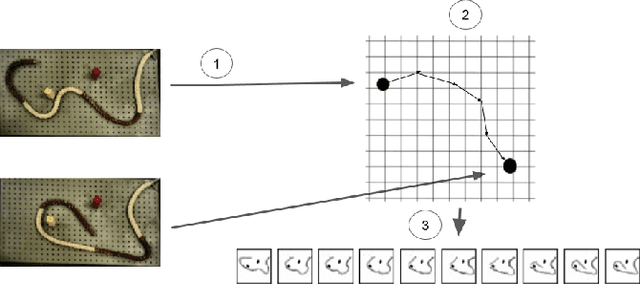
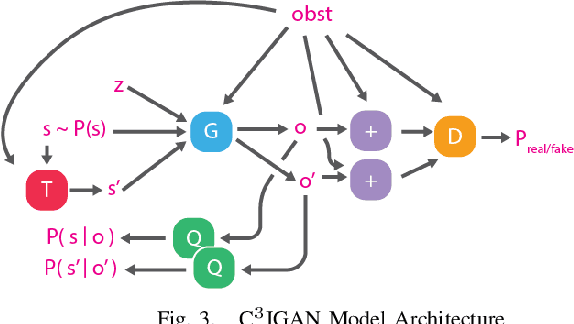
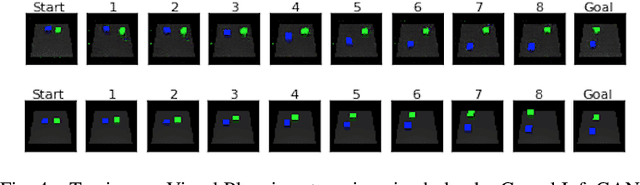
Planning for robotic manipulation requires reasoning about the changes a robot can affect on objects. When such interactions can be modelled analytically, as in domains with rigid objects, efficient planning algorithms exist. However, in both domestic and industrial domains, the objects of interest can be soft, or deformable, and hard to model analytically. For such cases, we posit that a data-driven modelling approach is more suitable. In recent years, progress in deep generative models has produced methods that learn to `imagine' plausible images from data. Building on the recent Causal InfoGAN generative model, in this work we learn to imagine goal-directed object manipulation directly from raw image data of self-supervised interaction of the robot with the object. After learning, given a goal observation of the system, our model can generate an imagined plan -- a sequence of images that transition the object into the desired goal. To execute the plan, we use it as a reference trajectory to track with a visual servoing controller, which we also learn from the data as an inverse dynamics model. In a simulated manipulation task, we show that separating the problem into visual planning and visual tracking control is more sample efficient and more interpretable than alternative data-driven approaches. We further demonstrate our approach on learning to imagine and execute in 3 environments, the final of which is deformable rope manipulation on a PR2 robot.
Model-Ensemble Trust-Region Policy Optimization
Oct 05, 2018
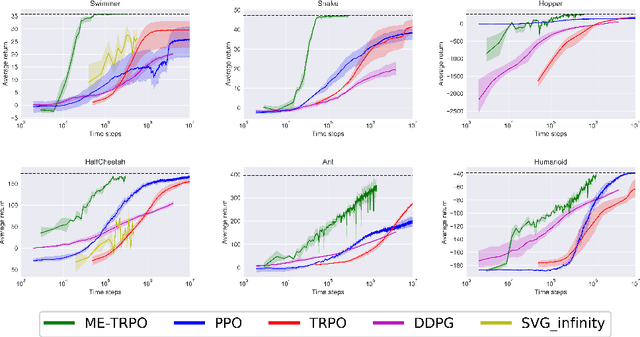
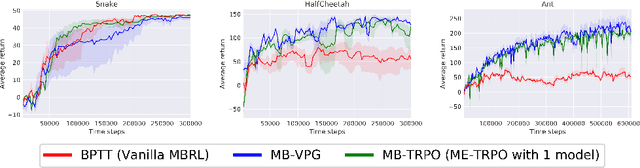
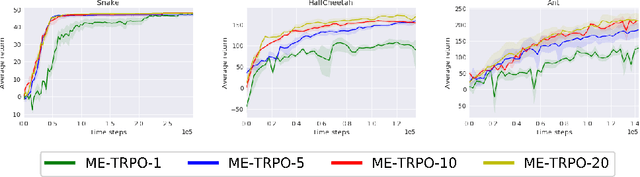
Model-free reinforcement learning (RL) methods are succeeding in a growing number of tasks, aided by recent advances in deep learning. However, they tend to suffer from high sample complexity, which hinders their use in real-world domains. Alternatively, model-based reinforcement learning promises to reduce sample complexity, but tends to require careful tuning and to date have succeeded mainly in restrictive domains where simple models are sufficient for learning. In this paper, we analyze the behavior of vanilla model-based reinforcement learning methods when deep neural networks are used to learn both the model and the policy, and show that the learned policy tends to exploit regions where insufficient data is available for the model to be learned, causing instability in training. To overcome this issue, we propose to use an ensemble of models to maintain the model uncertainty and regularize the learning process. We further show that the use of likelihood ratio derivatives yields much more stable learning than backpropagation through time. Altogether, our approach Model-Ensemble Trust-Region Policy Optimization (ME-TRPO) significantly reduces the sample complexity compared to model-free deep RL methods on challenging continuous control benchmark tasks.
Learning Plannable Representations with Causal InfoGAN
Jul 24, 2018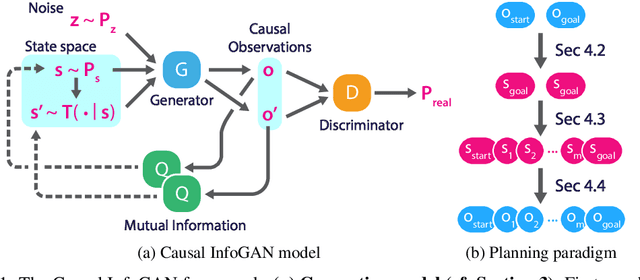

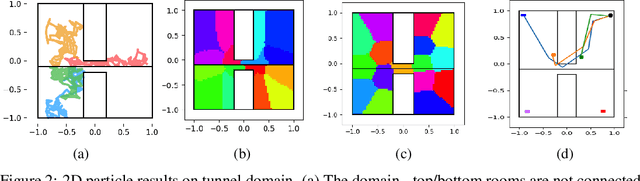
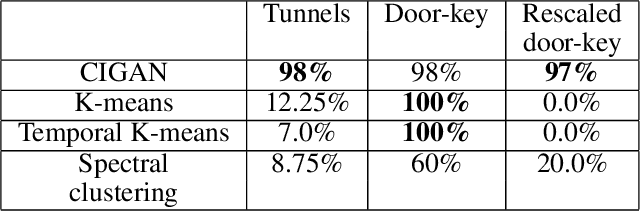
In recent years, deep generative models have been shown to 'imagine' convincing high-dimensional observations such as images, audio, and even video, learning directly from raw data. In this work, we ask how to imagine goal-directed visual plans -- a plausible sequence of observations that transition a dynamical system from its current configuration to a desired goal state, which can later be used as a reference trajectory for control. We focus on systems with high-dimensional observations, such as images, and propose an approach that naturally combines representation learning and planning. Our framework learns a generative model of sequential observations, where the generative process is induced by a transition in a low-dimensional planning model, and an additional noise. By maximizing the mutual information between the generated observations and the transition in the planning model, we obtain a low-dimensional representation that best explains the causal nature of the data. We structure the planning model to be compatible with efficient planning algorithms, and we propose several such models based on either discrete or continuous states. Finally, to generate a visual plan, we project the current and goal observations onto their respective states in the planning model, plan a trajectory, and then use the generative model to transform the trajectory to a sequence of observations. We demonstrate our method on imagining plausible visual plans of rope manipulation.
Object-based World Modeling in Semi-Static Environments with Dependent Dirichlet-Process Mixtures
Dec 02, 2015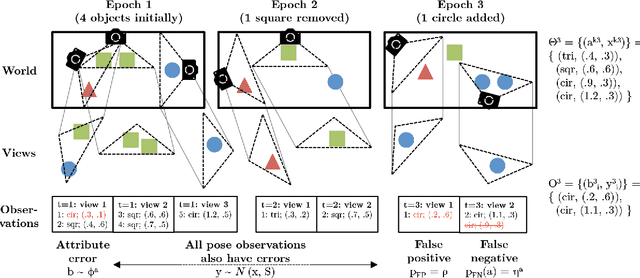

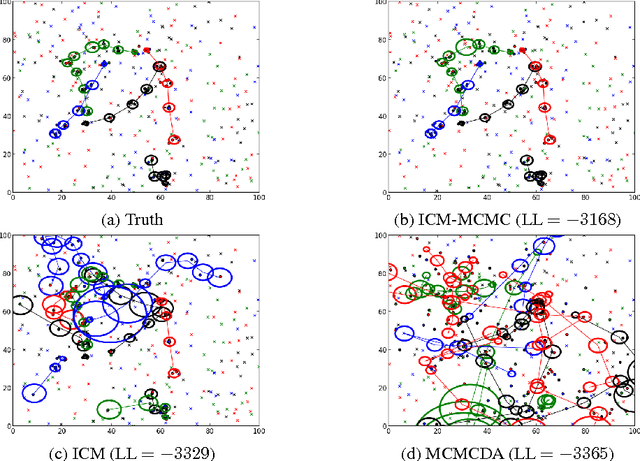
To accomplish tasks in human-centric indoor environments, robots need to represent and understand the world in terms of objects and their attributes. We refer to this attribute-based representation as a world model, and consider how to acquire it via noisy perception and maintain it over time, as objects are added, changed, and removed in the world. Previous work has framed this as multiple-target tracking problem, where objects are potentially in motion at all times. Although this approach is general, it is computationally expensive. We argue that such generality is not needed in typical world modeling tasks, where objects only change state occasionally. More efficient approaches are enabled by restricting ourselves to such semi-static environments. We consider a previously-proposed clustering-based world modeling approach that assumed static environments, and extend it to semi-static domains by applying a dependent Dirichlet-process (DDP) mixture model. We derive a novel MAP inference algorithm under this model, subject to data association constraints. We demonstrate our approach improves computational performance in semi-static environments.