 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\texttt{WEAVER}$, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
Jun 11, 2026The potential impacts of world models (WMs, i.e., learned simulators) on robotics are far-reaching -- policy evaluation, policy improvement, and test-time planning -- all with limited real-world interaction. To unlock these downstream capabilities, a WM needs to jointly satisfy three desiderata: $\textit{(i)}$ fidelity (i.e., producing simulated trajectories that correlate with reality), $\textit{(ii)}$ consistency (i.e., producing simulated trajectories that are coherent over long horizons), and $\textit{(iii)}$ efficiency (i.e., producing simulated trajectories quickly). We propose $\texttt{WEAVER}$ (World Estimation Across Views for Embodied Reasoning): a WM architecture that simultaneously achieves all three desiderata, providing state-of-the-art results on robotic manipulation tasks. $\texttt{WEAVER}$ is a multi-view WM trained to predict future latents and reward values via a flow-matching loss. We distill the key design decisions across model architecture, memory, and prediction objectives required to unlock the kinds of long-horizon dynamic manipulation tasks that have confounded prior world modeling approaches. We apply $\texttt{WEAVER}$ in robotic hardware, demonstrating its effectiveness at policy evaluation ($ρ$=0.870 correlation with real-world success rate), policy improvement (real-world success rate improvement of $38\%$ on top of the $π_{0.5}$ robot foundation model), and test-time planning (real-world success rate improvement of $14\%$ with a $5-10\times$ speedup over prior WMs). $\texttt{WEAVER}$ also demonstrates better performance than prior WMs when evaluated on out-of-distribution scenarios. Code, models, and videos at: https://arnavkj1995.github.io/WEAVER/ .
Position: Good Embodied Reward Models Need Bad Behavior Data
May 31, 2026This position paper argues that to obtain reliable embodied reward models, the community must invest in ``bad'' robot data: failed, suboptimal, error-prone, and even hazardous behaviors. While reward models are central to any foundation model's lifecycle, today's embodied reward models are trained primarily on successful behaviors. We analyze three state-of-the-art embodied reward models and find that they systematically over-reward behaviors that real human evaluators would penalize, including unsafe interactions, poor execution, and shortcut strategies that only superficially satisfy tasks. We attribute these failures to a key data gap: the scarcity of negative embodied data which is costly to collect and often filtered out or withheld in existing robotics datasets. Furthermore, we show that even modest exposure to real bad behavior data can improve alignment with human preferences and reduce costly false positives. We therefore call on the embodied AI community to curate and release their bad robot data, build synthetic bad data generation engines, develop more decentralized physical evaluation systems, and design benchmarks for fine-grained embodied reward model evaluations.
When to Act, Ask, or Learn: Uncertainty-Aware Policy Steering
Feb 25, 2026Policy steering is an emerging way to adapt robot behaviors at deployment-time: a learned verifier analyzes low-level action samples proposed by a pre-trained policy (e.g., diffusion policy) and selects only those aligned with the task. While Vision-Language Models (VLMs) are promising general-purpose verifiers due to their reasoning capabilities, existing frameworks often assume these models are well-calibrated. In practice, the overconfident judgment from VLM can degrade the steering performance under both high-level semantic uncertainty in task specifications and low-level action uncertainty or incapability of the pre-trained policy. We propose uncertainty-aware policy steering (UPS), a framework that jointly reasons about semantic task uncertainty and low-level action feasibility, and selects an uncertainty resolution strategy: execute a high-confidence action, clarify task ambiguity via natural language queries, or ask for action interventions to correct the low-level policy when it is deemed incapable at the task. We leverage conformal prediction to calibrate the composition of the VLM and the pre-trained base policy, providing statistical assurances that the verifier selects the correct strategy. After collecting interventions during deployment, we employ residual learning to improve the capability of the pre-trained policy, enabling the system to learn continually but with minimal expensive human feedback. We demonstrate our framework through experiments in simulation and on hardware, showing that UPS can disentangle confident, ambiguous, and incapable scenarios and minimizes expensive user interventions compared to uncalibrated baselines and prior human- or robot-gated continual learning approaches. Videos can be found at https://jessie-yuan.github.io/ups/
Empowering Small Language Models with Factual Hallucination-Aware Reasoning for Financial Classification
Jan 04, 2026Small language models (SLMs) are increasingly used for financial classification due to their fast inference and local deployability. However, compared with large language models, SLMs are more prone to factual hallucinations in reasoning and exhibit weaker classification performance. This raises a natural question: Can mitigating factual hallucinations improve SLMs' financial classification? To address this, we propose a three-step pipeline named AAAI (Association Identification, Automated Detection, and Adaptive Inference). Experiments on three representative SLMs reveal that: (1) factual hallucinations are positively correlated with misclassifications; (2) encoder-based verifiers effectively detect factual hallucinations; and (3) incorporating feedback on factual errors enables SLMs' adaptive inference that enhances classification performance. We hope this pipeline contributes to trustworthy and effective applications of SLMs in finance.
PanoNav: Mapless Zero-Shot Object Navigation with Panoramic Scene Parsing and Dynamic Memory
Nov 10, 2025Zero-shot object navigation (ZSON) in unseen environments remains a challenging problem for household robots, requiring strong perceptual understanding and decision-making capabilities. While recent methods leverage metric maps and Large Language Models (LLMs), they often depend on depth sensors or prebuilt maps, limiting the spatial reasoning ability of Multimodal Large Language Models (MLLMs). Mapless ZSON approaches have emerged to address this, but they typically make short-sighted decisions, leading to local deadlocks due to a lack of historical context. We propose PanoNav, a fully RGB-only, mapless ZSON framework that integrates a Panoramic Scene Parsing module to unlock the spatial parsing potential of MLLMs from panoramic RGB inputs, and a Memory-guided Decision-Making mechanism enhanced by a Dynamic Bounded Memory Queue to incorporate exploration history and avoid local deadlocks. Experiments on the public navigation benchmark show that PanoNav significantly outperforms representative baselines in both SR and SPL metrics.
LargeMvC-Net: Anchor-based Deep Unfolding Network for Large-scale Multi-view Clustering
Jul 28, 2025Deep anchor-based multi-view clustering methods enhance the scalability of neural networks by utilizing representative anchors to reduce the computational complexity of large-scale clustering. Despite their scalability advantages, existing approaches often incorporate anchor structures in a heuristic or task-agnostic manner, either through post-hoc graph construction or as auxiliary components for message passing. Such designs overlook the core structural demands of anchor-based clustering, neglecting key optimization principles. To bridge this gap, we revisit the underlying optimization problem of large-scale anchor-based multi-view clustering and unfold its iterative solution into a novel deep network architecture, termed LargeMvC-Net. The proposed model decomposes the anchor-based clustering process into three modules: RepresentModule, NoiseModule, and AnchorModule, corresponding to representation learning, noise suppression, and anchor indicator estimation. Each module is derived by unfolding a step of the original optimization procedure into a dedicated network component, providing structural clarity and optimization traceability. In addition, an unsupervised reconstruction loss aligns each view with the anchor-induced latent space, encouraging consistent clustering structures across views. Extensive experiments on several large-scale multi-view benchmarks show that LargeMvC-Net consistently outperforms state-of-the-art methods in terms of both effectiveness and scalability.
From Foresight to Forethought: VLM-In-the-Loop Policy Steering via Latent Alignment
Feb 03, 2025



While generative robot policies have demonstrated significant potential in learning complex, multimodal behaviors from demonstrations, they still exhibit diverse failures at deployment-time. Policy steering offers an elegant solution to reducing the chance of failure by using an external verifier to select from low-level actions proposed by an imperfect generative policy. Here, one might hope to use a Vision Language Model (VLM) as a verifier, leveraging its open-world reasoning capabilities. However, off-the-shelf VLMs struggle to understand the consequences of low-level robot actions as they are represented fundamentally differently than the text and images the VLM was trained on. In response, we propose FOREWARN, a novel framework to unlock the potential of VLMs as open-vocabulary verifiers for runtime policy steering. Our key idea is to decouple the VLM's burden of predicting action outcomes (foresight) from evaluation (forethought). For foresight, we leverage a latent world model to imagine future latent states given diverse low-level action plans. For forethought, we align the VLM with these predicted latent states to reason about the consequences of actions in its native representation--natural language--and effectively filter proposed plans. We validate our framework across diverse robotic manipulation tasks, demonstrating its ability to bridge representational gaps and provide robust, generalizable policy steering.
Maximizing Alignment with Minimal Feedback: Efficiently Learning Rewards for Visuomotor Robot Policy Alignment
Dec 06, 2024
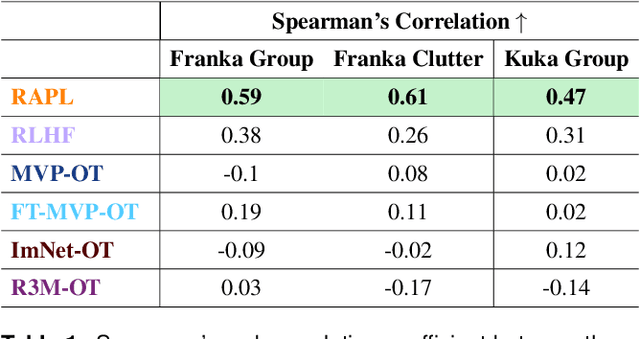

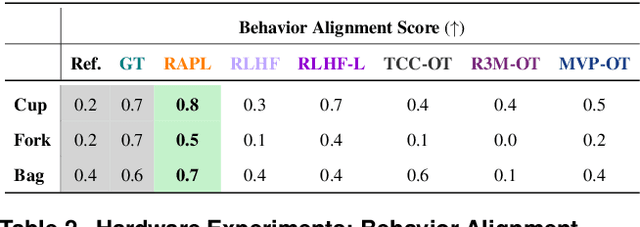
Visuomotor robot policies, increasingly pre-trained on large-scale datasets, promise significant advancements across robotics domains. However, aligning these policies with end-user preferences remains a challenge, particularly when the preferences are hard to specify. While reinforcement learning from human feedback (RLHF) has become the predominant mechanism for alignment in non-embodied domains like large language models, it has not seen the same success in aligning visuomotor policies due to the prohibitive amount of human feedback required to learn visual reward functions. To address this limitation, we propose Representation-Aligned Preference-based Learning (RAPL), an observation-only method for learning visual rewards from significantly less human preference feedback. Unlike traditional RLHF, RAPL focuses human feedback on fine-tuning pre-trained vision encoders to align with the end-user's visual representation and then constructs a dense visual reward via feature matching in this aligned representation space. We first validate RAPL through simulation experiments in the X-Magical benchmark and Franka Panda robotic manipulation, demonstrating that it can learn rewards aligned with human preferences, more efficiently uses preference data, and generalizes across robot embodiments. Finally, our hardware experiments align pre-trained Diffusion Policies for three object manipulation tasks. We find that RAPL can fine-tune these policies with 5x less real human preference data, taking the first step towards minimizing human feedback while maximizing visuomotor robot policy alignment.
FinRobot: AI Agent for Equity Research and Valuation with Large Language Models
Nov 13, 2024



As financial markets grow increasingly complex, there is a rising need for automated tools that can effectively assist human analysts in equity research, particularly within sell-side research. While Generative AI (GenAI) has attracted significant attention in this field, existing AI solutions often fall short due to their narrow focus on technical factors and limited capacity for discretionary judgment. These limitations hinder their ability to adapt to new data in real-time and accurately assess risks, which diminishes their practical value for investors. This paper presents FinRobot, the first AI agent framework specifically designed for equity research. FinRobot employs a multi-agent Chain of Thought (CoT) system, integrating both quantitative and qualitative analyses to emulate the comprehensive reasoning of a human analyst. The system is structured around three specialized agents: the Data-CoT Agent, which aggregates diverse data sources for robust financial integration; the Concept-CoT Agent, which mimics an analysts reasoning to generate actionable insights; and the Thesis-CoT Agent, which synthesizes these insights into a coherent investment thesis and report. FinRobot provides thorough company analysis supported by precise numerical data, industry-appropriate valuation metrics, and realistic risk assessments. Its dynamically updatable data pipeline ensures that research remains timely and relevant, adapting seamlessly to new financial information. Unlike existing automated research tools, such as CapitalCube and Wright Reports, FinRobot delivers insights comparable to those produced by major brokerage firms and fundamental research vendors. We open-source FinRobot at \url{https://github. com/AI4Finance-Foundation/FinRobot}.
HACMan++: Spatially-Grounded Motion Primitives for Manipulation
Jul 11, 2024



Although end-to-end robot learning has shown some success for robot manipulation, the learned policies are often not sufficiently robust to variations in object pose or geometry. To improve the policy generalization, we introduce spatially-grounded parameterized motion primitives in our method HACMan++. Specifically, we propose an action representation consisting of three components: what primitive type (such as grasp or push) to execute, where the primitive will be grounded (e.g. where the gripper will make contact with the world), and how the primitive motion is executed, such as parameters specifying the push direction or grasp orientation. These three components define a novel discrete-continuous action space for reinforcement learning. Our framework enables robot agents to learn to chain diverse motion primitives together and select appropriate primitive parameters to complete long-horizon manipulation tasks. By grounding the primitives on a spatial location in the environment, our method is able to effectively generalize across object shape and pose variations. Our approach significantly outperforms existing methods, particularly in complex scenarios demanding both high-level sequential reasoning and object generalization. With zero-shot sim-to-real transfer, our policy succeeds in challenging real-world manipulation tasks, with generalization to unseen objects. Videos can be found on the project website: https://sgmp-rss2024.github.io.