 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing Alignment with Minimal Feedback: Efficiently Learning Rewards for Visuomotor Robot Policy Alignment
Paper and Code
Dec 06, 2024
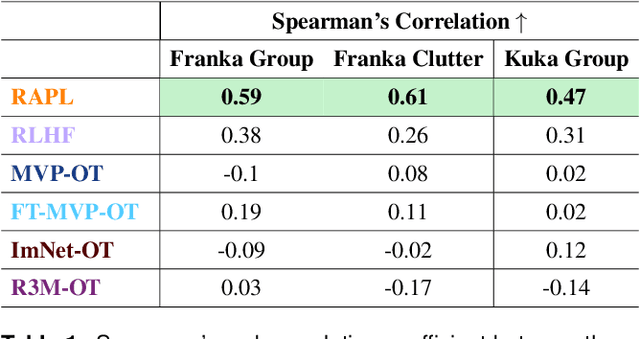

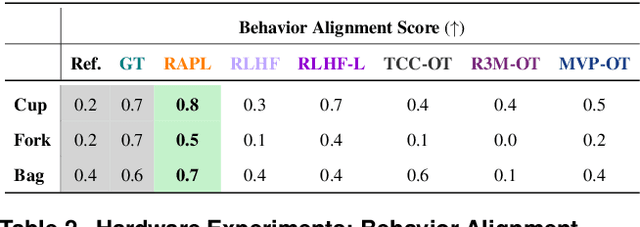
Visuomotor robot policies, increasingly pre-trained on large-scale datasets, promise significant advancements across robotics domains. However, aligning these policies with end-user preferences remains a challenge, particularly when the preferences are hard to specify. While reinforcement learning from human feedback (RLHF) has become the predominant mechanism for alignment in non-embodied domains like large language models, it has not seen the same success in aligning visuomotor policies due to the prohibitive amount of human feedback required to learn visual reward functions. To address this limitation, we propose Representation-Aligned Preference-based Learning (RAPL), an observation-only method for learning visual rewards from significantly less human preference feedback. Unlike traditional RLHF, RAPL focuses human feedback on fine-tuning pre-trained vision encoders to align with the end-user's visual representation and then constructs a dense visual reward via feature matching in this aligned representation space. We first validate RAPL through simulation experiments in the X-Magical benchmark and Franka Panda robotic manipulation, demonstrating that it can learn rewards aligned with human preferences, more efficiently uses preference data, and generalizes across robot embodiments. Finally, our hardware experiments align pre-trained Diffusion Policies for three object manipulation tasks. We find that RAPL can fine-tune these policies with 5x less real human preference data, taking the first step towards minimizing human feedback while maximizing visuomotor robot policy alignment.