 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Good Embodied Reward Models Need Bad Behavior Data
May 31, 2026This position paper argues that to obtain reliable embodied reward models, the community must invest in ``bad'' robot data: failed, suboptimal, error-prone, and even hazardous behaviors. While reward models are central to any foundation model's lifecycle, today's embodied reward models are trained primarily on successful behaviors. We analyze three state-of-the-art embodied reward models and find that they systematically over-reward behaviors that real human evaluators would penalize, including unsafe interactions, poor execution, and shortcut strategies that only superficially satisfy tasks. We attribute these failures to a key data gap: the scarcity of negative embodied data which is costly to collect and often filtered out or withheld in existing robotics datasets. Furthermore, we show that even modest exposure to real bad behavior data can improve alignment with human preferences and reduce costly false positives. We therefore call on the embodied AI community to curate and release their bad robot data, build synthetic bad data generation engines, develop more decentralized physical evaluation systems, and design benchmarks for fine-grained embodied reward model evaluations.
StressDream: Steering Video World Models for Robust Policy Evaluation and Improvement
May 29, 2026Video world models (WMs) have shown promise for policy evaluation and improvement by imagining realistic future observations conditioned on ego-robot actions. While WMs can model distributions over futures, policy evaluation and improvement typically rely on nominal imaginations, which can miss high-impact outcomes of robot actions unless prohibitively many samples are drawn. To enable robust policy evaluation and improvement over WM imaginations, we propose StressDream, which steers imaginations toward high-impact yet plausible outcomes specified at inference time by optimizing the initial noise of diffusion-based WMs. However, optimizing high-dimensional noise is challenging: the optimization must reason about nuanced, scene-dependent target events in generated videos while avoiding out-of-distribution (OOD) noise that yields implausible imaginations. We address this with two complementary objectives: a semantic objective with a Vision-Language Model that provides informative gradients by reasoning about the generated video, and a plausibility objective that prevents the optimized noise from drifting OOD. With state-of-the-art video world models for autonomous driving and robotic manipulation, we show that StressDream effectively steers imaginations toward high-impact yet plausible outcomes specified by text at inference time, such as task failures, enabling robust policy evaluation and improvement by identifying actions whose plausible futures include undesirable outcomes. Video results are available at https://junwon.me/StressDream/.
AdaGamma: State-Dependent Discounting for Temporal Adaptation in Reinforcement Learning
May 07, 2026The discount factor in reinforcement learning controls both the effective planning horizon and the strength of bootstrapping, yet most deep RL methods use a single fixed value across all states. While state-dependent discounting is conceptually appealing, naive deep actor--critic implementations can become unstable and degenerate toward TD-error collapse. We propose AdaGamma, a practical deep actor--critic method for state-dependent discounting that learns a state-dependent discount function together with a return-consistency objective to regularize the induced backup structure. On the theory side, we analyze the Bellman operator induced by state-dependent discounting and establish its basic well-posedness properties under suitable conditions. Empirically, AdaGamma integrates into both SAC and PPO, yielding consistent improvements on continuous-control benchmarks, and achieves statistically significant gains in an online A/B test on the JD Logistics platform. These results suggest that state-dependent discounting can be made effective in deep RL when coupled with a return-consistency objective that prevents degenerate target manipulation.
\$OneMillion-Bench: How Far are Language Agents from Human Experts?
Mar 09, 2026As language models (LMs) evolve from chat assistants to long-horizon agents capable of multi-step reasoning and tool use, existing benchmarks remain largely confined to structured or exam-style tasks that fall short of real-world professional demands. To this end, we introduce \$OneMillion-Bench \$OneMillion-Bench, a benchmark of 400 expert-curated tasks spanning Law, Finance, Industry, Healthcare, and Natural Science, built to evaluate agents across economically consequential scenarios. Unlike prior work, the benchmark requires retrieving authoritative sources, resolving conflicting evidence, applying domain-specific rules, and making constraint decisions, where correctness depends as much on the reasoning process as the final answer. We adopt a rubric-based evaluation protocol scoring factual accuracy, logical coherence, practical feasibility, and professional compliance, focused on expert-level problems to ensure meaningful differentiation across agents. Together, \$OneMillion-Bench provides a unified testbed for assessing agentic reliability, professional depth, and practical readiness in domain-intensive scenarios.
Latent Chain-of-Thought World Modeling for End-to-End Driving
Dec 11, 2025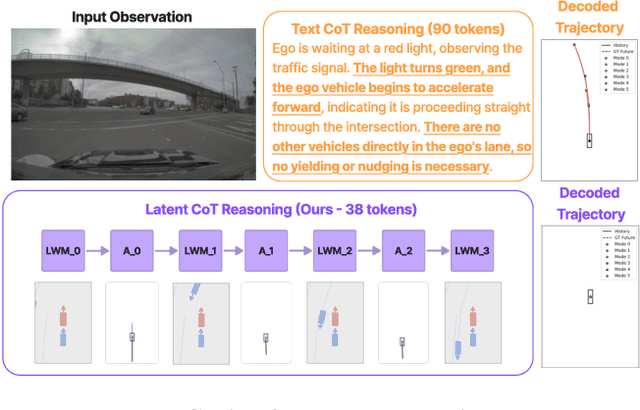
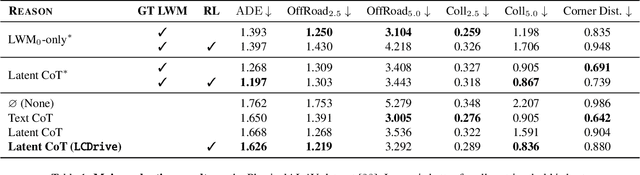
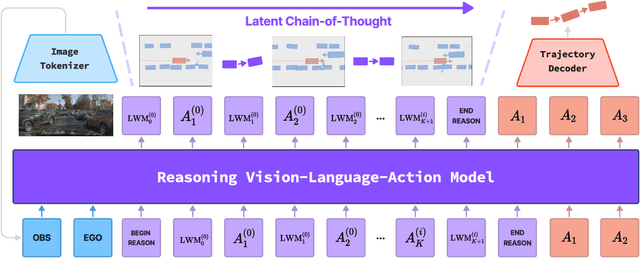
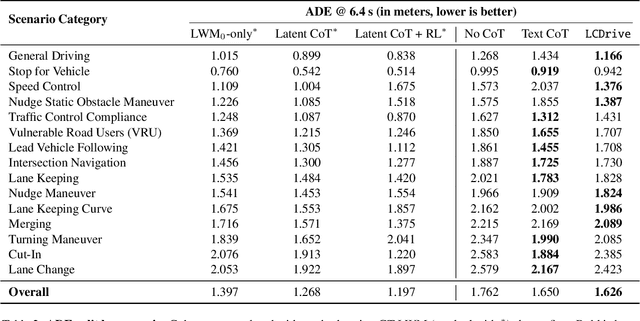
Recent Vision-Language-Action (VLA) models for autonomous driving explore inference-time reasoning as a way to improve driving performance and safety in challenging scenarios. Most prior work uses natural language to express chain-of-thought (CoT) reasoning before producing driving actions. However, text may not be the most efficient representation for reasoning. In this work, we present Latent-CoT-Drive (LCDrive): a model that expresses CoT in a latent language that captures possible outcomes of the driving actions being considered. Our approach unifies CoT reasoning and decision making by representing both in an action-aligned latent space. Instead of natural language, the model reasons by interleaving (1) action-proposal tokens, which use the same vocabulary as the model's output actions; and (2) world model tokens, which are grounded in a learned latent world model and express future outcomes of these actions. We cold start latent CoT by supervising the model's action proposals and world model tokens based on ground-truth future rollouts of the scene. We then post-train with closed-loop reinforcement learning to strengthen reasoning capabilities. On a large-scale end-to-end driving benchmark, LCDrive achieves faster inference, better trajectory quality, and larger improvements from interactive reinforcement learning compared to both non-reasoning and text-reasoning baselines.
QuantV2X: A Fully Quantized Multi-Agent System for Cooperative Perception
Sep 03, 2025Cooperative perception through Vehicle-to-Everything (V2X) communication offers significant potential for enhancing vehicle perception by mitigating occlusions and expanding the field of view. However, past research has predominantly focused on improving accuracy metrics without addressing the crucial system-level considerations of efficiency, latency, and real-world deployability. Noticeably, most existing systems rely on full-precision models, which incur high computational and transmission costs, making them impractical for real-time operation in resource-constrained environments. In this paper, we introduce \textbf{QuantV2X}, the first fully quantized multi-agent system designed specifically for efficient and scalable deployment of multi-modal, multi-agent V2X cooperative perception. QuantV2X introduces a unified end-to-end quantization strategy across both neural network models and transmitted message representations that simultaneously reduces computational load and transmission bandwidth. Remarkably, despite operating under low-bit constraints, QuantV2X achieves accuracy comparable to full-precision systems. More importantly, when evaluated under deployment-oriented metrics, QuantV2X reduces system-level latency by 3.2$\times$ and achieves a +9.5 improvement in mAP30 over full-precision baselines. Furthermore, QuantV2X scales more effectively, enabling larger and more capable models to fit within strict memory budgets. These results highlight the viability of a fully quantized multi-agent intermediate fusion system for real-world deployment. The system will be publicly released to promote research in this field: https://github.com/ucla-mobility/QuantV2X.
Direct Post-Training Preference Alignment for Multi-Agent Motion Generation Models Using Implicit Feedback from Pre-training Demonstrations
Mar 25, 2025Recent advancements in LLMs have revolutionized motion generation models in embodied applications. While LLM-type auto-regressive motion generation models benefit from training scalability, there remains a discrepancy between their token prediction objectives and human preferences. As a result, models pre-trained solely with token-prediction objectives often generate behaviors that deviate from what humans would prefer, making post-training preference alignment crucial for producing human-preferred motions. Unfortunately, post-training alignment requires extensive preference rankings of motions generated by the pre-trained model, which are costly to annotate, especially in multi-agent settings. Recently, there has been growing interest in leveraging pre-training demonstrations to scalably generate preference data for post-training alignment. However, these methods often adopt an adversarial assumption, treating all pre-trained model-generated samples as unpreferred examples. This adversarial approach overlooks the valuable signal provided by preference rankings among the model's own generations, ultimately reducing alignment effectiveness and potentially leading to misaligned behaviors. In this work, instead of treating all generated samples as equally bad, we leverage implicit preferences encoded in pre-training demonstrations to construct preference rankings among the pre-trained model's generations, offering more nuanced preference alignment guidance with zero human cost. We apply our approach to large-scale traffic simulation and demonstrate its effectiveness in improving the realism of pre-trained model's generated behaviors, making a lightweight 1M motion generation model comparable to SOTA large imitation-based models by relying solely on implicit feedback from pre-training demonstrations, without additional post-training human preference annotations or high computational costs.
From Foresight to Forethought: VLM-In-the-Loop Policy Steering via Latent Alignment
Feb 03, 2025



While generative robot policies have demonstrated significant potential in learning complex, multimodal behaviors from demonstrations, they still exhibit diverse failures at deployment-time. Policy steering offers an elegant solution to reducing the chance of failure by using an external verifier to select from low-level actions proposed by an imperfect generative policy. Here, one might hope to use a Vision Language Model (VLM) as a verifier, leveraging its open-world reasoning capabilities. However, off-the-shelf VLMs struggle to understand the consequences of low-level robot actions as they are represented fundamentally differently than the text and images the VLM was trained on. In response, we propose FOREWARN, a novel framework to unlock the potential of VLMs as open-vocabulary verifiers for runtime policy steering. Our key idea is to decouple the VLM's burden of predicting action outcomes (foresight) from evaluation (forethought). For foresight, we leverage a latent world model to imagine future latent states given diverse low-level action plans. For forethought, we align the VLM with these predicted latent states to reason about the consequences of actions in its native representation--natural language--and effectively filter proposed plans. We validate our framework across diverse robotic manipulation tasks, demonstrating its ability to bridge representational gaps and provide robust, generalizable policy steering.
Maximizing Alignment with Minimal Feedback: Efficiently Learning Rewards for Visuomotor Robot Policy Alignment
Dec 06, 2024
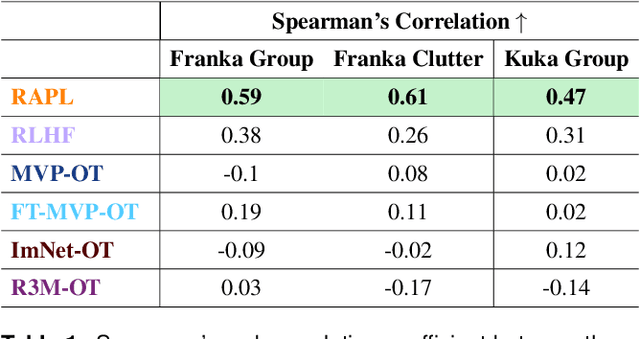

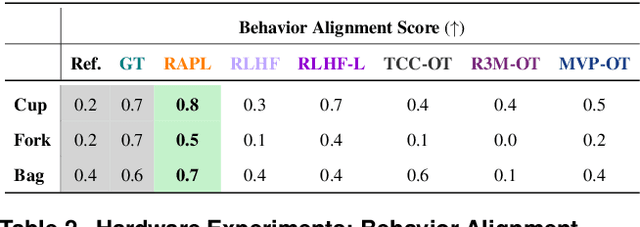
Visuomotor robot policies, increasingly pre-trained on large-scale datasets, promise significant advancements across robotics domains. However, aligning these policies with end-user preferences remains a challenge, particularly when the preferences are hard to specify. While reinforcement learning from human feedback (RLHF) has become the predominant mechanism for alignment in non-embodied domains like large language models, it has not seen the same success in aligning visuomotor policies due to the prohibitive amount of human feedback required to learn visual reward functions. To address this limitation, we propose Representation-Aligned Preference-based Learning (RAPL), an observation-only method for learning visual rewards from significantly less human preference feedback. Unlike traditional RLHF, RAPL focuses human feedback on fine-tuning pre-trained vision encoders to align with the end-user's visual representation and then constructs a dense visual reward via feature matching in this aligned representation space. We first validate RAPL through simulation experiments in the X-Magical benchmark and Franka Panda robotic manipulation, demonstrating that it can learn rewards aligned with human preferences, more efficiently uses preference data, and generalizes across robot embodiments. Finally, our hardware experiments align pre-trained Diffusion Policies for three object manipulation tasks. We find that RAPL can fine-tune these policies with 5x less real human preference data, taking the first step towards minimizing human feedback while maximizing visuomotor robot policy alignment.
Wolf: Captioning Everything with a World Summarization Framework
Jul 26, 2024



We propose Wolf, a WOrLd summarization Framework for accurate video captioning. Wolf is an automated captioning framework that adopts a mixture-of-experts approach, leveraging complementary strengths of Vision Language Models (VLMs). By utilizing both image and video models, our framework captures different levels of information and summarizes them efficiently. Our approach can be applied to enhance video understanding, auto-labeling, and captioning. To evaluate caption quality, we introduce CapScore, an LLM-based metric to assess the similarity and quality of generated captions compared to the ground truth captions. We further build four human-annotated datasets in three domains: autonomous driving, general scenes, and robotics, to facilitate comprehensive comparisons. We show that Wolf achieves superior captioning performance compared to state-of-the-art approaches from the research community (VILA1.5, CogAgent) and commercial solutions (Gemini-Pro-1.5, GPT-4V). For instance, in comparison with GPT-4V, Wolf improves CapScore both quality-wise by 55.6% and similarity-wise by 77.4% on challenging driving videos. Finally, we establish a benchmark for video captioning and introduce a leaderboard, aiming to accelerate advancements in video understanding, captioning, and data alignment. Leaderboard: https://wolfv0.github.io/leaderboard.html.