 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative 4D Scene Gaussian Splatting with Object View-Synthesis Priors
Jun 15, 2025We tackle the challenge of generating dynamic 4D scenes from monocular, multi-object videos with heavy occlusions, and introduce GenMOJO, a novel approach that integrates rendering-based deformable 3D Gaussian optimization with generative priors for view synthesis. While existing models perform well on novel view synthesis for isolated objects, they struggle to generalize to complex, cluttered scenes. To address this, GenMOJO decomposes the scene into individual objects, optimizing a differentiable set of deformable Gaussians per object. This object-wise decomposition allows leveraging object-centric diffusion models to infer unobserved regions in novel viewpoints. It performs joint Gaussian splatting to render the full scene, capturing cross-object occlusions, and enabling occlusion-aware supervision. To bridge the gap between object-centric priors and the global frame-centric coordinate system of videos, GenMOJO uses differentiable transformations that align generative and rendering constraints within a unified framework. The resulting model generates 4D object reconstructions over space and time, and produces accurate 2D and 3D point tracks from monocular input. Quantitative evaluations and perceptual human studies confirm that GenMOJO generates more realistic novel views of scenes and produces more accurate point tracks compared to existing approaches.
Sparse Diffusion Policy: A Sparse, Reusable, and Flexible Policy for Robot Learning
Jul 01, 2024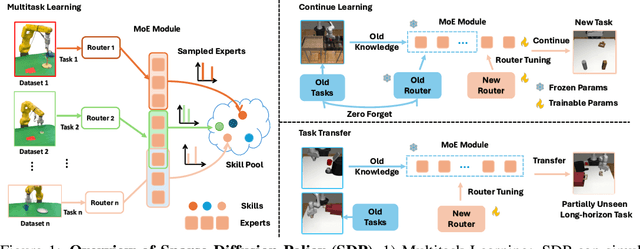

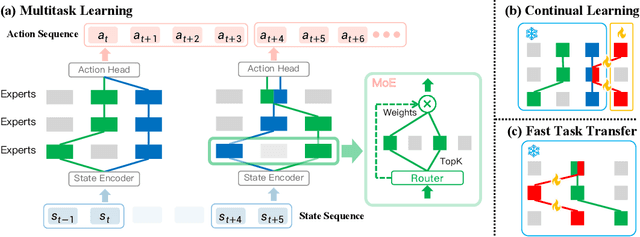

The increasing complexity of tasks in robotics demands efficient strategies for multitask and continual learning. Traditional models typically rely on a universal policy for all tasks, facing challenges such as high computational costs and catastrophic forgetting when learning new tasks. To address these issues, we introduce a sparse, reusable, and flexible policy, Sparse Diffusion Policy (SDP). By adopting Mixture of Experts (MoE) within a transformer-based diffusion policy, SDP selectively activates experts and skills, enabling efficient and task-specific learning without retraining the entire model. SDP not only reduces the burden of active parameters but also facilitates the seamless integration and reuse of experts across various tasks. Extensive experiments on diverse tasks in both simulations and real world show that SDP 1) excels in multitask scenarios with negligible increases in active parameters, 2) prevents forgetting in continual learning of new tasks, and 3) enables efficient task transfer, offering a promising solution for advanced robotic applications. Demos and codes can be found in https://forrest-110.github.io/sparse_diffusion_policy/.
Joint Pedestrian Trajectory Prediction through Posterior Sampling
Mar 30, 2024Joint pedestrian trajectory prediction has long grappled with the inherent unpredictability of human behaviors. Recent investigations employing variants of conditional diffusion models in trajectory prediction have exhibited notable success. Nevertheless, the heavy dependence on accurate historical data results in their vulnerability to noise disturbances and data incompleteness. To improve the robustness and reliability, we introduce the Guided Full Trajectory Diffuser (GFTD), a novel diffusion model framework that captures the joint full (historical and future) trajectory distribution. By learning from the full trajectory, GFTD can recover the noisy and missing data, hence improving the robustness. In addition, GFTD can adapt to data imperfections without additional training requirements, leveraging posterior sampling for reliable prediction and controllable generation. Our approach not only simplifies the prediction process but also enhances generalizability in scenarios with noise and incomplete inputs. Through rigorous experimental evaluation, GFTD exhibits superior performance in both trajectory prediction and controllable generation.
Human-oriented Representation Learning for Robotic Manipulation
Oct 04, 2023Humans inherently possess generalizable visual representations that empower them to efficiently explore and interact with the environments in manipulation tasks. We advocate that such a representation automatically arises from simultaneously learning about multiple simple perceptual skills that are critical for everyday scenarios (e.g., hand detection, state estimate, etc.) and is better suited for learning robot manipulation policies compared to current state-of-the-art visual representations purely based on self-supervised objectives. We formalize this idea through the lens of human-oriented multi-task fine-tuning on top of pre-trained visual encoders, where each task is a perceptual skill tied to human-environment interactions. We introduce Task Fusion Decoder as a plug-and-play embedding translator that utilizes the underlying relationships among these perceptual skills to guide the representation learning towards encoding meaningful structure for what's important for all perceptual skills, ultimately empowering learning of downstream robotic manipulation tasks. Extensive experiments across a range of robotic tasks and embodiments, in both simulations and real-world environments, show that our Task Fusion Decoder consistently improves the representation of three state-of-the-art visual encoders including R3M, MVP, and EgoVLP, for downstream manipulation policy-learning. Project page: https://sites.google.com/view/human-oriented-robot-learning
AbHE: All Attention-based Homography Estimation
Dec 07, 2022



Homography estimation is a basic computer vision task, which aims to obtain the transformation from multi-view images for image alignment. Unsupervised learning homography estimation trains a convolution neural network for feature extraction and transformation matrix regression. While the state-of-theart homography method is based on convolution neural networks, few work focuses on transformer which shows superiority in highlevel vision tasks. In this paper, we propose a strong-baseline model based on the Swin Transformer, which combines convolution neural network for local features and transformer module for global features. Moreover, a cross non-local layer is introduced to search the matched features within the feature maps coarsely. In the homography regression stage, we adopt an attention layer for the channels of correlation volume, which can drop out some weak correlation feature points. The experiment shows that in 8 Degree-of-Freedoms(DOFs) homography estimation our method overperforms the state-of-the-art method.