 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWEAVER, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
Jun 16, 2026The potential impacts of world models (WMs, i.e., learned simulators) on robotics are far-reaching -- policy evaluation, policy improvement, and test-time planning -- all with limited real-world interaction. To unlock these downstream capabilities, a WM needs to jointly satisfy three desiderata: $\textit{(i)}$ fidelity (i.e., producing simulated trajectories that correlate with reality), $\textit{(ii)}$ consistency (i.e., producing simulated trajectories that are coherent over long horizons), and $\textit{(iii)}$ efficiency (i.e., producing simulated trajectories quickly). We propose WEAVER (World Estimation Across Views for Embodied Reasoning): a WM architecture that simultaneously achieves all three desiderata, providing state-of-the-art results on robotic manipulation tasks. WEAVER is a multi-view WM trained to predict future latents and reward values via a flow-matching loss. We distill the key design decisions across model architecture, memory, and prediction objectives required to unlock the kinds of long-horizon dynamic manipulation tasks that have confounded prior world modeling approaches. We apply WEAVER in robotic hardware, demonstrating its effectiveness at policy evaluation ($ρ$=0.870 correlation with real-world success rate), policy improvement (real-world success rate improvement of $38\%$ on top of the $π_{0.5}$ robot foundation model), and test-time planning (real-world success rate improvement of $14\%$ with a $5-10\times$ speedup over prior WMs). WEAVER also demonstrates better performance than prior WMs when evaluated on out-of-distribution scenarios. Code, models, and videos at: https://arnavkj1995.github.io/WEAVER/ .
$\texttt{WEAVER}$, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
Jun 11, 2026The potential impacts of world models (WMs, i.e., learned simulators) on robotics are far-reaching -- policy evaluation, policy improvement, and test-time planning -- all with limited real-world interaction. To unlock these downstream capabilities, a WM needs to jointly satisfy three desiderata: $\textit{(i)}$ fidelity (i.e., producing simulated trajectories that correlate with reality), $\textit{(ii)}$ consistency (i.e., producing simulated trajectories that are coherent over long horizons), and $\textit{(iii)}$ efficiency (i.e., producing simulated trajectories quickly). We propose $\texttt{WEAVER}$ (World Estimation Across Views for Embodied Reasoning): a WM architecture that simultaneously achieves all three desiderata, providing state-of-the-art results on robotic manipulation tasks. $\texttt{WEAVER}$ is a multi-view WM trained to predict future latents and reward values via a flow-matching loss. We distill the key design decisions across model architecture, memory, and prediction objectives required to unlock the kinds of long-horizon dynamic manipulation tasks that have confounded prior world modeling approaches. We apply $\texttt{WEAVER}$ in robotic hardware, demonstrating its effectiveness at policy evaluation ($ρ$=0.870 correlation with real-world success rate), policy improvement (real-world success rate improvement of $38\%$ on top of the $π_{0.5}$ robot foundation model), and test-time planning (real-world success rate improvement of $14\%$ with a $5-10\times$ speedup over prior WMs). $\texttt{WEAVER}$ also demonstrates better performance than prior WMs when evaluated on out-of-distribution scenarios. Code, models, and videos at: https://arnavkj1995.github.io/WEAVER/ .
Learning What to Say to Your VLA: Mostly Harmless Vision Language Action Model Steering
Jun 10, 2026Vision-Language-Action (VLA) models provide a natural language interface to robot control, but the mapping from language to behavior is often brittle and unintuitive: semantically similar instructions can induce drastically different behaviors, while some capabilities may not be elicitable through prompting alone. As a result, both human instructions and zero-shot language models can fail to reliably steer VLAs toward successful task execution. In this work, we propose a framework that interactively searches for language sequences that improve closed-loop VLA task performance, distills these sequences into a test-time language feedback policy (LFP), and learns an improvement head that predicts when language steering will improve performance. We conformalize this improvement head to prevent harmful steering interventions, where the LFP decreases task performance relative to the original instruction on out-of-distribution scenarios. Crucially, our approach operates on arbitrary frozen pre-trained VLAs, requiring neither access to the original training distribution nor fine-tuning of the underlying model. On seen environments, our conformalized LFP improves base VLA performance by 24.7% in simulation and 65.0% in hardware. On visual and semantic perturbations, our conformalized LFP has strong harmlessness guarantees, and produces recovery behaviors not observed with open-loop prompting.
Justified or Just Convincing? Error Verifiability as a Dimension of LLM Quality
Apr 06, 2026As LLMs are deployed in high-stakes settings, users must judge the correctness of individual responses, often relying on model-generated justifications such as reasoning chains or explanations. Yet, no standard measure exists for whether these justifications help users distinguish correct answers from incorrect ones. We formalize this idea as error verifiability and propose $v_{\text{bal}}$, a balanced metric that measures whether justifications enable raters to accurately assess answer correctness, validated against human raters who show high agreement. We find that neither common approaches, such as post-training and model scaling, nor more targeted interventions recommended improve verifiability. We introduce two methods that succeed at improving verifiability: reflect-and-rephrase (RR) for mathematical reasoning and oracle-rephrase (OR) for factual QA, both of which improve verifiability by incorporating domain-appropriate external information. Together, our results establish error verifiability as a distinct dimension of response quality that does not emerge from accuracy improvements alone and requires dedicated, domain-aware methods to address.
Back to Blackwell: Closing the Loop on Intransitivity in Multi-Objective Preference Fine-Tuning
Feb 22, 2026A recurring challenge in preference fine-tuning (PFT) is handling $\textit{intransitive}$ (i.e., cyclic) preferences. Intransitive preferences often stem from either $\textit{(i)}$ inconsistent rankings along a single objective or $\textit{(ii)}$ scalarizing multiple objectives into a single metric. Regardless of their source, the downstream implication of intransitive preferences is the same: there is no well-defined optimal policy, breaking a core assumption of the standard PFT pipeline. In response, we propose a novel, game-theoretic solution concept -- the $\textit{Maximum Entropy Blackwell Winner}$ ($\textit{MaxEntBW}$) -- that is well-defined under multi-objective intransitive preferences. To enable computing MaxEntBWs at scale, we derive $\texttt{PROSPER}$: a provably efficient PFT algorithm. Unlike prior self-play techniques, $\texttt{PROSPER}$ directly handles multiple objectives without requiring scalarization. We then apply $\texttt{PROSPER}$ to the problem of fine-tuning large language models (LLMs) from multi-objective LLM-as-a-Judge feedback (e.g., rubric-based judges), a setting where both sources of intransitivity arise. We find that $\texttt{PROSPER}$ outperforms all baselines considered across both instruction following and general chat benchmarks, releasing trained model checkpoints at the 7B and 3B parameter scales.
Gained in Translation: Privileged Pairwise Judges Enhance Multilingual Reasoning
Jan 26, 2026When asked a question in a language less seen in its training data, current reasoning large language models (RLMs) often exhibit dramatically lower performance than when asked the same question in English. In response, we introduce \texttt{SP3F} (Self-Play with Privileged Pairwise Feedback), a two-stage framework for enhancing multilingual reasoning without \textit{any} data in the target language(s). First, we supervise fine-tune (SFT) on translated versions of English question-answer pairs to raise base model correctness. Second, we perform RL with feedback from a pairwise judge in a self-play fashion, with the judge receiving the English reference response as \textit{privileged information}. Thus, even when none of the model's responses are completely correct, the privileged pairwise judge can still tell which response is better. End-to-end, \texttt{SP3F} greatly improves base model performance, even outperforming fully post-trained models on multiple math and non-math tasks with less than of the training data across the single-language, multilingual, and generalization to unseen language settings.
A Smooth Sea Never Made a Skilled $\texttt{SAILOR}$: Robust Imitation via Learning to Search
Jun 05, 2025



The fundamental limitation of the behavioral cloning (BC) approach to imitation learning is that it only teaches an agent what the expert did at states the expert visited. This means that when a BC agent makes a mistake which takes them out of the support of the demonstrations, they often don't know how to recover from it. In this sense, BC is akin to giving the agent the fish -- giving them dense supervision across a narrow set of states -- rather than teaching them to fish: to be able to reason independently about achieving the expert's outcome even when faced with unseen situations at test-time. In response, we explore learning to search (L2S) from expert demonstrations, i.e. learning the components required to, at test time, plan to match expert outcomes, even after making a mistake. These include (1) a world model and (2) a reward model. We carefully ablate the set of algorithmic and design decisions required to combine these and other components for stable and sample/interaction-efficient learning of recovery behavior without additional human corrections. Across a dozen visual manipulation tasks from three benchmarks, our approach $\texttt{SAILOR}$ consistently out-performs state-of-the-art Diffusion Policies trained via BC on the same data. Furthermore, scaling up the amount of demonstrations used for BC by 5-10$\times$ still leaves a performance gap. We find that $\texttt{SAILOR}$ can identify nuanced failures and is robust to reward hacking. Our code is available at https://github.com/arnavkj1995/SAILOR .
Scaling Offline RL via Efficient and Expressive Shortcut Models
May 28, 2025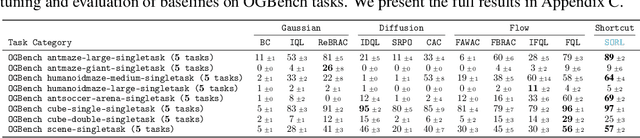
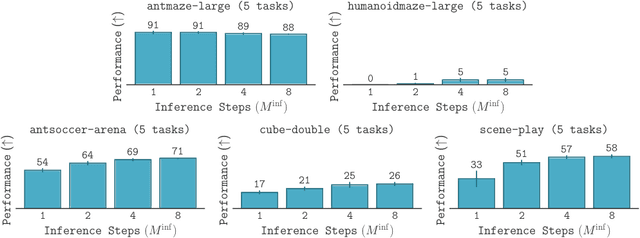
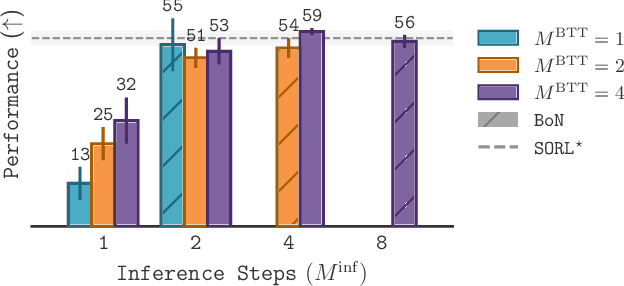
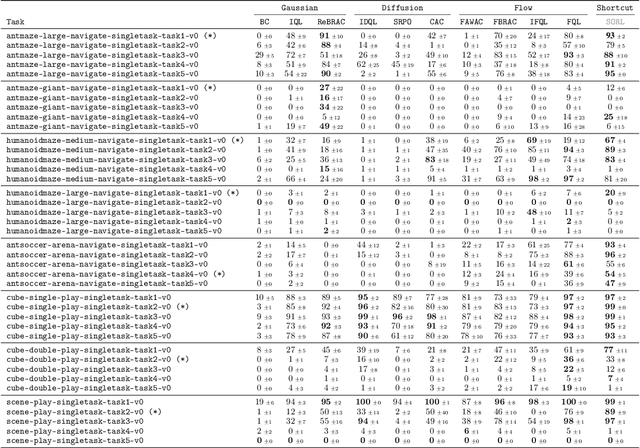
Diffusion and flow models have emerged as powerful generative approaches capable of modeling diverse and multimodal behavior. However, applying these models to offline reinforcement learning (RL) remains challenging due to the iterative nature of their noise sampling processes, making policy optimization difficult. In this paper, we introduce Scalable Offline Reinforcement Learning (SORL), a new offline RL algorithm that leverages shortcut models - a novel class of generative models - to scale both training and inference. SORL's policy can capture complex data distributions and can be trained simply and efficiently in a one-stage training procedure. At test time, SORL introduces both sequential and parallel inference scaling by using the learned Q-function as a verifier. We demonstrate that SORL achieves strong performance across a range of offline RL tasks and exhibits positive scaling behavior with increased test-time compute. We release the code at nico-espinosadice.github.io/projects/sorl.
Efficient Imitation Under Misspecification
Mar 17, 2025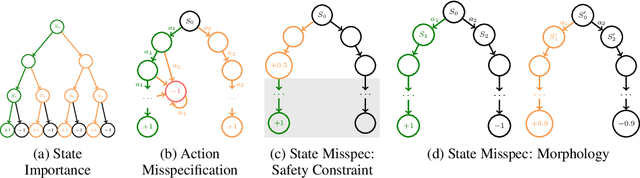

Interactive imitation learning (IL) is a powerful paradigm for learning to make sequences of decisions from an expert demonstrating how to perform a task. Prior work in efficient imitation learning has focused on the realizable setting, where the expert's policy lies within the learner's policy class (i.e. the learner can perfectly imitate the expert in all states). However, in practice, perfect imitation of the expert is often impossible due to differences in state information and action space expressiveness (e.g. morphological differences between robots and humans.) In this paper, we consider the more general misspecified setting, where no assumptions are made about the expert policy's realizability. We introduce a novel structural condition, reward-agnostic policy completeness, and prove that it is sufficient for interactive IL algorithms to efficiently avoid the quadratically compounding errors that stymie offline approaches like behavioral cloning. We address an additional practical constraint-the case of limited expert data-and propose a principled method for using additional offline data to further improve the sample-efficiency of interactive IL algorithms. Finally, we empirically investigate the optimal reset distribution in efficient IL under misspecification with a suite of continuous control tasks.
All Roads Lead to Likelihood: The Value of Reinforcement Learning in Fine-Tuning
Mar 03, 2025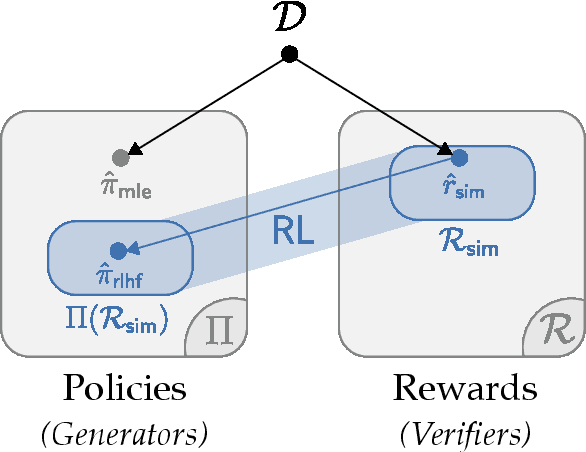

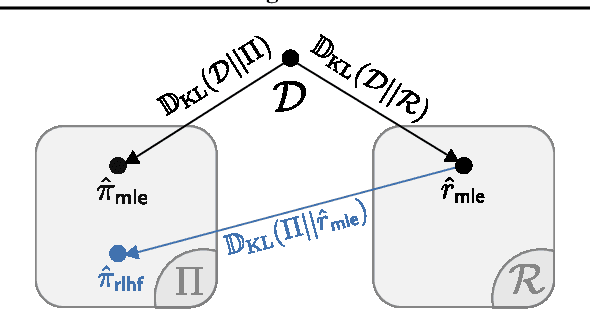

From a first-principles perspective, it may seem odd that the strongest results in foundation model fine-tuning (FT) are achieved via a relatively complex, two-stage training procedure. Specifically, one first trains a reward model (RM) on some dataset (e.g. human preferences) before using it to provide online feedback as part of a downstream reinforcement learning (RL) procedure, rather than directly optimizing the policy parameters on the dataset via offline maximum likelihood estimation. In fact, from an information-theoretic perspective, we can only lose information via passing through a reward model and cannot create any new information via on-policy sampling. To explain this discrepancy, we scrutinize several hypotheses on the value of RL in FT through both theoretical and empirical lenses. Of the hypotheses considered, we find the most support for the explanation that on problems with a generation-verification gap, the combination of the ease of learning the relatively simple RM (verifier) from the preference data, coupled with the ability of the downstream RL procedure to then filter its search space to the subset of policies (generators) that are optimal for relatively simple verifiers is what leads to the superior performance of online FT.