 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsking the Right Questions: Improving Reasoning with Generated Stepping Stones
Feb 22, 2026Recent years have witnessed tremendous progress in enabling LLMs to solve complex reasoning tasks such as math and coding. As we start to apply LLMs to harder tasks that they may not be able to solve in one shot, it is worth paying attention to their ability to construct intermediate stepping stones that prepare them to better solve the tasks. Examples of stepping stones include simplifications, alternative framings, or subproblems. We study properties and benefits of stepping stones in the context of modern reasoning LLMs via ARQ (\textbf{A}king the \textbf{R}ight \textbf{Q}uestions), our simple framework which introduces a question generator to the default reasoning pipeline. We first show that good stepping stone questions exist and are transferrable, meaning that good questions can be generated, and they substantially help LLMs of various capabilities in solving the target tasks. We next frame stepping stone generation as a post-training task and show that we can fine-tune LLMs to generate more useful stepping stones by SFT and RL on synthetic data.
Multi-Agent Craftax: Benchmarking Open-Ended Multi-Agent Reinforcement Learning at the Hyperscale
Nov 07, 2025Progress in multi-agent reinforcement learning (MARL) requires challenging benchmarks that assess the limits of current methods. However, existing benchmarks often target narrow short-horizon challenges that do not adequately stress the long-term dependencies and generalization capabilities inherent in many multi-agent systems. To address this, we first present \textit{Craftax-MA}: an extension of the popular open-ended RL environment, Craftax, that supports multiple agents and evaluates a wide range of general abilities within a single environment. Written in JAX, \textit{Craftax-MA} is exceptionally fast with a training run using 250 million environment interactions completing in under an hour. To provide a more compelling challenge for MARL, we also present \textit{Craftax-Coop}, an extension introducing heterogeneous agents, trading and more mechanics that require complex cooperation among agents for success. We provide analysis demonstrating that existing algorithms struggle with key challenges in this benchmark, including long-horizon credit assignment, exploration and cooperation, and argue for its potential to drive long-term research in MARL.
Learning When to Plan: Efficiently Allocating Test-Time Compute for LLM Agents
Sep 03, 2025Training large language models (LLMs) to reason via reinforcement learning (RL) significantly improves their problem-solving capabilities. In agentic settings, existing methods like ReAct prompt LLMs to explicitly plan before every action; however, we demonstrate that always planning is computationally expensive and degrades performance on long-horizon tasks, while never planning further limits performance. To address this, we introduce a conceptual framework formalizing dynamic planning for LLM agents, enabling them to flexibly decide when to allocate test-time compute for planning. We propose a simple two-stage training pipeline: (1) supervised fine-tuning on diverse synthetic data to prime models for dynamic planning, and (2) RL to refine this capability in long-horizon environments. Experiments on the Crafter environment show that dynamic planning agents trained with this approach are more sample-efficient and consistently achieve more complex objectives. Additionally, we demonstrate that these agents can be effectively steered by human-written plans, surpassing their independent capabilities. To our knowledge, this work is the first to explore training LLM agents for dynamic test-time compute allocation in sequential decision-making tasks, paving the way for more efficient, adaptive, and controllable agentic systems.
How Should We Meta-Learn Reinforcement Learning Algorithms?
Jul 23, 2025The process of meta-learning algorithms from data, instead of relying on manual design, is growing in popularity as a paradigm for improving the performance of machine learning systems. Meta-learning shows particular promise for reinforcement learning (RL), where algorithms are often adapted from supervised or unsupervised learning despite their suboptimality for RL. However, until now there has been a severe lack of comparison between different meta-learning algorithms, such as using evolution to optimise over black-box functions or LLMs to propose code. In this paper, we carry out this empirical comparison of the different approaches when applied to a range of meta-learned algorithms which target different parts of the RL pipeline. In addition to meta-train and meta-test performance, we also investigate factors including the interpretability, sample cost and train time for each meta-learning algorithm. Based on these findings, we propose several guidelines for meta-learning new RL algorithms which will help ensure that future learned algorithms are as performant as possible.
AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
Jul 03, 2025AI research agents are demonstrating great potential to accelerate scientific progress by automating the design, implementation, and training of machine learning models. We focus on methods for improving agents' performance on MLE-bench, a challenging benchmark where agents compete in Kaggle competitions to solve real-world machine learning problems. We formalize AI research agents as search policies that navigate a space of candidate solutions, iteratively modifying them using operators. By designing and systematically varying different operator sets and search policies (Greedy, MCTS, Evolutionary), we show that their interplay is critical for achieving high performance. Our best pairing of search strategy and operator set achieves a state-of-the-art result on MLE-bench lite, increasing the success rate of achieving a Kaggle medal from 39.6% to 47.7%. Our investigation underscores the importance of jointly considering the search strategy, operator design, and evaluation methodology in advancing automated machine learning.
Ad-Hoc Human-AI Coordination Challenge
Jun 26, 2025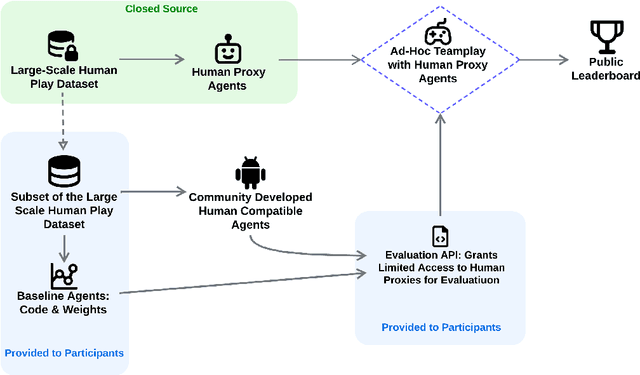

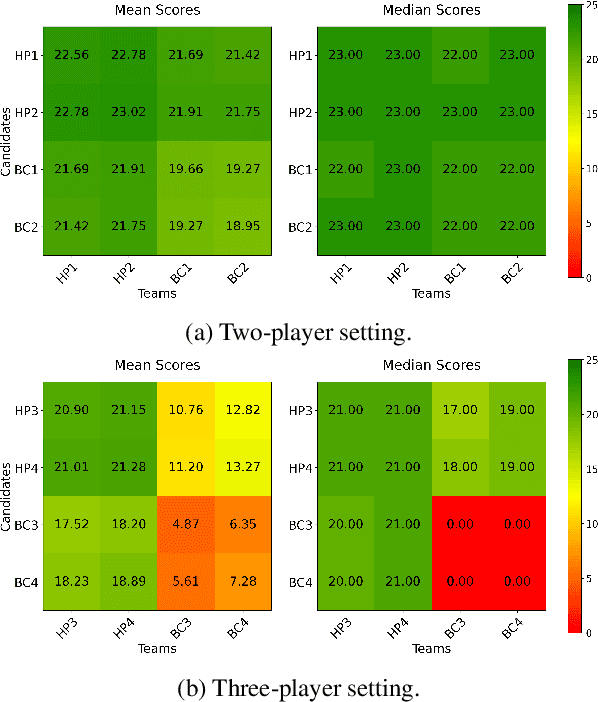

Achieving seamless coordination between AI agents and humans is crucial for real-world applications, yet it remains a significant open challenge. Hanabi is a cooperative card game featuring imperfect information, constrained communication, theory of mind requirements, and coordinated action -- making it an ideal testbed for human-AI coordination. However, its use for human-AI interaction has been limited by the challenges of human evaluation. In this work, we introduce the Ad-Hoc Human-AI Coordination Challenge (AH2AC2) to overcome the constraints of costly and difficult-to-reproduce human evaluations. We develop \textit{human proxy agents} on a large-scale human dataset that serve as robust, cheap, and reproducible human-like evaluation partners in AH2AC2. To encourage the development of data-efficient methods, we open-source a dataset of 3,079 games, deliberately limiting the amount of available human gameplay data. We present baseline results for both two- and three- player Hanabi scenarios. To ensure fair evaluation, we host the proxy agents through a controlled evaluation system rather than releasing them publicly. The code is available at \href{https://github.com/FLAIROx/ah2ac2}{https://github.com/FLAIROx/ah2ac2}.
A Clean Slate for Offline Reinforcement Learning
Apr 15, 2025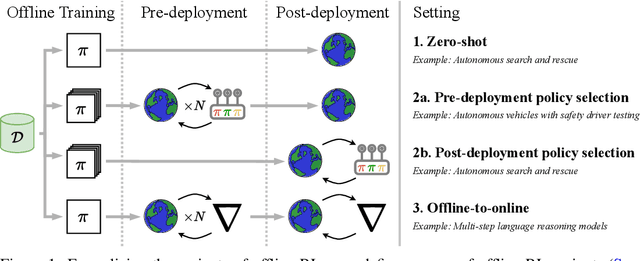

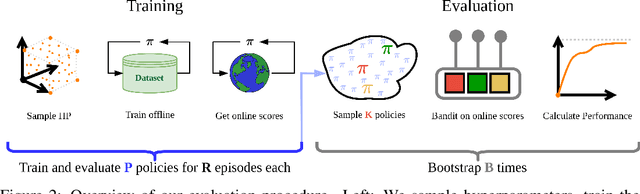

Progress in offline reinforcement learning (RL) has been impeded by ambiguous problem definitions and entangled algorithmic designs, resulting in inconsistent implementations, insufficient ablations, and unfair evaluations. Although offline RL explicitly avoids environment interaction, prior methods frequently employ extensive, undocumented online evaluation for hyperparameter tuning, complicating method comparisons. Moreover, existing reference implementations differ significantly in boilerplate code, obscuring their core algorithmic contributions. We address these challenges by first introducing a rigorous taxonomy and a transparent evaluation protocol that explicitly quantifies online tuning budgets. To resolve opaque algorithmic design, we provide clean, minimalistic, single-file implementations of various model-free and model-based offline RL methods, significantly enhancing clarity and achieving substantial speed-ups. Leveraging these streamlined implementations, we propose Unifloral, a unified algorithm that encapsulates diverse prior approaches within a single, comprehensive hyperparameter space, enabling algorithm development in a shared hyperparameter space. Using Unifloral with our rigorous evaluation protocol, we develop two novel algorithms - TD3-AWR (model-free) and MoBRAC (model-based) - which substantially outperform established baselines. Our implementation is publicly available at https://github.com/EmptyJackson/unifloral.
AgentBreeder: Mitigating the AI Safety Impact of Multi-Agent Scaffolds
Feb 02, 2025Scaffolding Large Language Models (LLMs) into multi-agent systems often improves performance on complex tasks, but the safety impact of such scaffolds has not been as thoroughly explored. In this paper, we introduce AGENTBREEDER a framework for multi-objective evolutionary search over scaffolds. Our REDAGENTBREEDER evolves scaffolds towards jailbreaking the base LLM while achieving high task success, while BLUEAGENTBREEDER instead aims to combine safety with task reward. We evaluate the systems discovered by the different instances of AGENTBREEDER and popular baselines using widely recognized reasoning, mathematics, and safety benchmarks. Our work highlights and mitigates the safety risks due to multi-agent scaffolding.
BALROG: Benchmarking Agentic LLM and VLM Reasoning On Games
Nov 20, 2024



Large Language Models (LLMs) and Vision Language Models (VLMs) possess extensive knowledge and exhibit promising reasoning abilities; however, they still struggle to perform well in complex, dynamic environments. Real-world tasks require handling intricate interactions, advanced spatial reasoning, long-term planning, and continuous exploration of new strategies-areas in which we lack effective methodologies for comprehensively evaluating these capabilities. To address this gap, we introduce BALROG, a novel benchmark designed to assess the agentic capabilities of LLMs and VLMs through a diverse set of challenging games. Our benchmark incorporates a range of existing reinforcement learning environments with varying levels of difficulty, including tasks that are solvable by non-expert humans in seconds to extremely challenging ones that may take years to master (e.g., the NetHack Learning Environment). We devise fine-grained metrics to measure performance and conduct an extensive evaluation of several popular open-source and closed-source LLMs and VLMs. Our findings indicate that while current models achieve partial success in the easier games, they struggle significantly with more challenging tasks. Notably, we observe severe deficiencies in vision-based decision-making, as models perform worse when visual representations of the environments are provided. We release BALROG as an open and user-friendly benchmark to facilitate future research and development in the agentic community.
Learning Loss Landscapes in Preference Optimization
Nov 10, 2024



We present an empirical study investigating how specific properties of preference datasets, such as mixed-quality or noisy data, affect the performance of Preference Optimization (PO) algorithms. Our experiments, conducted in MuJoCo environments, reveal several scenarios where state-of-the-art PO methods experience significant drops in performance. To address this issue, we introduce a novel PO framework based on mirror descent, which can recover existing methods like Direct Preference Optimization (DPO) and Odds-Ratio Preference Optimization (ORPO) for specific choices of the mirror map. Within this framework, we employ evolutionary strategies to discover new loss functions capable of handling the identified problematic scenarios. These new loss functions lead to significant performance improvements over DPO and ORPO across several tasks. Additionally, we demonstrate the generalization capability of our approach by applying the discovered loss functions to fine-tuning large language models using mixed-quality data, where they outperform ORPO.