 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Self-Taught Faithfulness Evaluators
Jul 28, 2025The growing use of large language models (LLMs) has increased the need for automatic evaluation systems, particularly to address the challenge of information hallucination. Although existing faithfulness evaluation approaches have shown promise, they are predominantly English-focused and often require expensive human-labeled training data for fine-tuning specialized models. As LLMs see increased adoption in multilingual contexts, there is a need for accurate faithfulness evaluators that can operate across languages without extensive labeled data. This paper presents Self-Taught Evaluators for Multilingual Faithfulness, a framework that learns exclusively from synthetic multilingual summarization data while leveraging cross-lingual transfer learning. Through experiments comparing language-specific and mixed-language fine-tuning approaches, we demonstrate a consistent relationship between an LLM's general language capabilities and its performance in language-specific evaluation tasks. Our framework shows improvements over existing baselines, including state-of-the-art English evaluators and machine translation-based approaches.
Learning Loss Landscapes in Preference Optimization
Nov 10, 2024



We present an empirical study investigating how specific properties of preference datasets, such as mixed-quality or noisy data, affect the performance of Preference Optimization (PO) algorithms. Our experiments, conducted in MuJoCo environments, reveal several scenarios where state-of-the-art PO methods experience significant drops in performance. To address this issue, we introduce a novel PO framework based on mirror descent, which can recover existing methods like Direct Preference Optimization (DPO) and Odds-Ratio Preference Optimization (ORPO) for specific choices of the mirror map. Within this framework, we employ evolutionary strategies to discover new loss functions capable of handling the identified problematic scenarios. These new loss functions lead to significant performance improvements over DPO and ORPO across several tasks. Additionally, we demonstrate the generalization capability of our approach by applying the discovered loss functions to fine-tuning large language models using mixed-quality data, where they outperform ORPO.
Meta-learning the mirror map in policy mirror descent
Feb 07, 2024
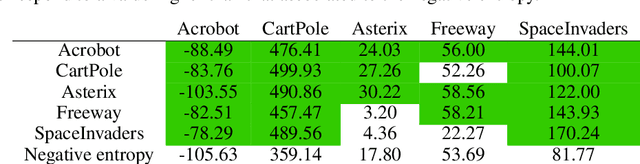
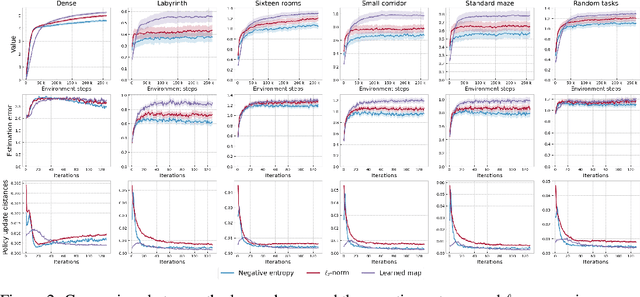
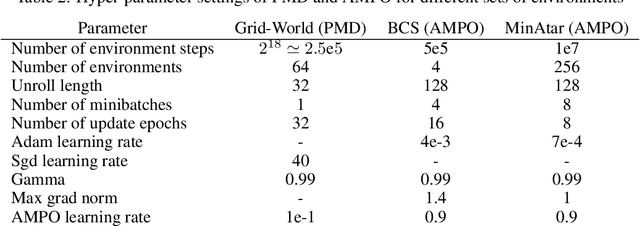
Policy Mirror Descent (PMD) is a popular framework in reinforcement learning, serving as a unifying perspective that encompasses numerous algorithms. These algorithms are derived through the selection of a mirror map and enjoy finite-time convergence guarantees. Despite its popularity, the exploration of PMD's full potential is limited, with the majority of research focusing on a particular mirror map -- namely, the negative entropy -- which gives rise to the renowned Natural Policy Gradient (NPG) method. It remains uncertain from existing theoretical studies whether the choice of mirror map significantly influences PMD's efficacy. In our work, we conduct empirical investigations to show that the conventional mirror map choice (NPG) often yields less-than-optimal outcomes across several standard benchmark environments. By applying a meta-learning approach, we identify more efficient mirror maps that enhance performance, both on average and in terms of best performance achieved along the training trajectory. We analyze the characteristics of these learned mirror maps and reveal shared traits among certain settings. Our results suggest that mirror maps have the potential to be adaptable across various environments, raising questions about how to best match a mirror map to an environment's structure and characteristics.
A Novel Framework for Policy Mirror Descent with General Parametrization and Linear Convergence
Jan 30, 2023

Modern policy optimization methods in applied reinforcement learning are often inspired by the trust region policy optimization algorithm, which can be interpreted as a particular instance of policy mirror descent. While theoretical guarantees have been established for this framework, particularly in the tabular setting, the use of a general parametrization scheme remains mostly unjustified. In this work, we introduce a novel framework for policy optimization based on mirror descent that naturally accommodates general parametrizations. The policy class induced by our scheme recovers known classes, e.g. tabular softmax, log-linear, and neural policies. It also generates new ones, depending on the choice of the mirror map. For a general mirror map and parametrization function, we establish the quasi-monotonicity of the updates in value function, global linear convergence rates, and we bound the total variation of the algorithm along its path. To showcase the ability of our framework to accommodate general parametrization schemes, we present a case study involving shallow neural networks.
Linear Convergence for Natural Policy Gradient with Log-linear Policy Parametrization
Sep 30, 2022We analyze the convergence rate of the unregularized natural policy gradient algorithm with log-linear policy parametrizations in infinite-horizon discounted Markov decision processes. In the deterministic case, when the Q-value is known and can be approximated by a linear combination of a known feature function up to a bias error, we show that a geometrically-increasing step size yields a linear convergence rate towards an optimal policy. We then consider the sample-based case, when the best representation of the Q- value function among linear combinations of a known feature function is known up to an estimation error. In this setting, we show that the algorithm enjoys the same linear guarantees as in the deterministic case up to an error term that depends on the estimation error, the bias error, and the condition number of the feature covariance matrix. Our results build upon the general framework of policy mirror descent and extend previous findings for the softmax tabular parametrization to the log-linear policy class.
Dimension-Free Rates for Natural Policy Gradient in Multi-Agent Reinforcement Learning
Sep 23, 2021Cooperative multi-agent reinforcement learning is a decentralized paradigm in sequential decision making where agents distributed over a network iteratively collaborate with neighbors to maximize global (network-wide) notions of rewards. Exact computations typically involve a complexity that scales exponentially with the number of agents. To address this curse of dimensionality, we design a scalable algorithm based on the Natural Policy Gradient framework that uses local information and only requires agents to communicate with neighbors within a certain range. Under standard assumptions on the spatial decay of correlations for the transition dynamics of the underlying Markov process and the localized learning policy, we show that our algorithm converges to the globally optimal policy with a dimension-free statistical and computational complexity, incurring a localization error that does not depend on the number of agents and converges to zero exponentially fast as a function of the range of communication.