 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA differentiable model of supply-chain shocks
Nov 07, 2025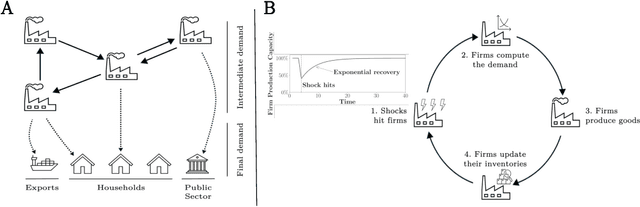
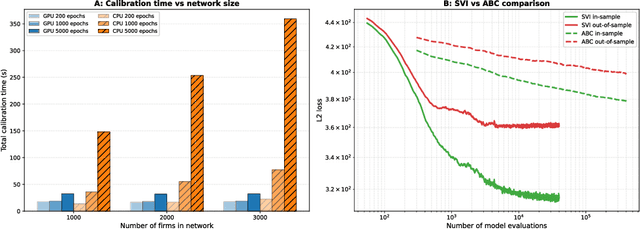
Modelling how shocks propagate in supply chains is an increasingly important challenge in economics. Its relevance has been highlighted in recent years by events such as Covid-19 and the Russian invasion of Ukraine. Agent-based models (ABMs) are a promising approach for this problem. However, calibrating them is hard. We show empirically that it is possible to achieve speed ups of over 3 orders of magnitude when calibrating ABMs of supply networks by running them on GPUs and using automatic differentiation, compared to non-differentiable baselines. This opens the door to scaling ABMs to model the whole global supply network.
Opponent Shaping for Antibody Development
Sep 19, 2024Anti-viral therapies are typically designed or evolved towards the current strains of a virus. In learning terms, this corresponds to a myopic best response, i.e., not considering the possible adaptive moves of the opponent. However, therapy-induced selective pressures act on viral antigens to drive the emergence of mutated strains, against which initial therapies have reduced efficacy. To motivate our work, we consider antibody designs that target not only the current viral strains but also the wide range of possible future variants that the virus might evolve into under the evolutionary pressure exerted by said antibodies. Building on a computational model of binding between antibodies and viral antigens (the Absolut! framework), we design and implement a genetic simulation of the viral evolutionary escape. Crucially, this allows our antibody optimisation algorithm to consider and influence the entire escape curve of the virus, i.e. to guide (or ''shape'') the viral evolution. This is inspired by opponent shaping which, in general-sum learning, accounts for the adaptation of the co-player rather than playing a myopic best response. Hence we call the optimised antibodies shapers. Within our simulations, we demonstrate that our shapers target both current and simulated future viral variants, outperforming the antibodies chosen in a myopic way. Furthermore, we show that shapers exert specific evolutionary pressure on the virus compared to myopic antibodies. Altogether, shapers modify the evolutionary trajectories of viral strains and minimise the viral escape compared to their myopic counterparts. While this is a simple model, we hope that our proposed paradigm will enable the discovery of better long-lived vaccines and antibody therapies in the future, enabled by rapid advancements in the capabilities of simulation tools.
Meta-learning the mirror map in policy mirror descent
Feb 07, 2024
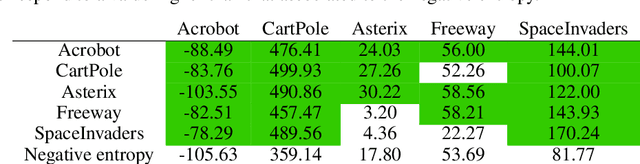
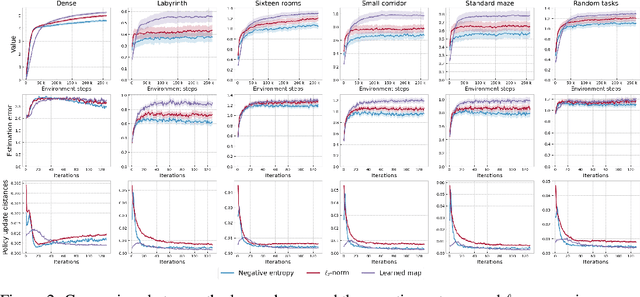
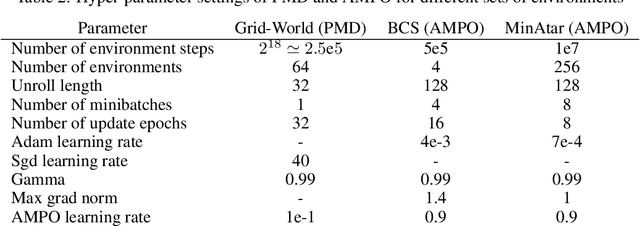
Policy Mirror Descent (PMD) is a popular framework in reinforcement learning, serving as a unifying perspective that encompasses numerous algorithms. These algorithms are derived through the selection of a mirror map and enjoy finite-time convergence guarantees. Despite its popularity, the exploration of PMD's full potential is limited, with the majority of research focusing on a particular mirror map -- namely, the negative entropy -- which gives rise to the renowned Natural Policy Gradient (NPG) method. It remains uncertain from existing theoretical studies whether the choice of mirror map significantly influences PMD's efficacy. In our work, we conduct empirical investigations to show that the conventional mirror map choice (NPG) often yields less-than-optimal outcomes across several standard benchmark environments. By applying a meta-learning approach, we identify more efficient mirror maps that enhance performance, both on average and in terms of best performance achieved along the training trajectory. We analyze the characteristics of these learned mirror maps and reveal shared traits among certain settings. Our results suggest that mirror maps have the potential to be adaptable across various environments, raising questions about how to best match a mirror map to an environment's structure and characteristics.
Arbitrary Order Meta-Learning with Simple Population-Based Evolution
Mar 16, 2023

Meta-learning, the notion of learning to learn, enables learning systems to quickly and flexibly solve new tasks. This usually involves defining a set of outer-loop meta-parameters that are then used to update a set of inner-loop parameters. Most meta-learning approaches use complicated and computationally expensive bi-level optimisation schemes to update these meta-parameters. Ideally, systems should perform multiple orders of meta-learning, i.e. to learn to learn to learn and so on, to accelerate their own learning. Unfortunately, standard meta-learning techniques are often inappropriate for these higher-order meta-parameters because the meta-optimisation procedure becomes too complicated or unstable. Inspired by the higher-order meta-learning we observe in real-world evolution, we show that using simple population-based evolution implicitly optimises for arbitrarily-high order meta-parameters. First, we theoretically prove and empirically show that population-based evolution implicitly optimises meta-parameters of arbitrarily-high order in a simple setting. We then introduce a minimal self-referential parameterisation, which in principle enables arbitrary-order meta-learning. Finally, we show that higher-order meta-learning improves performance on time series forecasting tasks.