 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcedural Generation of Algorithm Discovery Tasks in Machine Learning
Mar 18, 2026Automating the development of machine learning algorithms has the potential to unlock new breakthroughs. However, our ability to improve and evaluate algorithm discovery systems has thus far been limited by existing task suites. They suffer from many issues, such as: poor evaluation methodologies; data contamination; and containing saturated or very similar problems. Here, we introduce DiscoGen, a procedural generator of algorithm discovery tasks for machine learning, such as developing optimisers for reinforcement learning or loss functions for image classification. Motivated by the success of procedural generation in reinforcement learning, DiscoGen spans millions of tasks of varying difficulty and complexity from a range of machine learning fields. These tasks are specified by a small number of configuration parameters and can be used to optimise algorithm discovery agents (ADAs). We present DiscoBench, a benchmark consisting of a fixed, small subset of DiscoGen tasks for principled evaluation of ADAs. Finally, we propose a number of ambitious, impactful research directions enabled by DiscoGen, in addition to experiments demonstrating its use for prompt optimisation of an ADA. DiscoGen is released open-source at https://github.com/AlexGoldie/discogen.
Opponent Shaping for Antibody Development
Sep 19, 2024Anti-viral therapies are typically designed or evolved towards the current strains of a virus. In learning terms, this corresponds to a myopic best response, i.e., not considering the possible adaptive moves of the opponent. However, therapy-induced selective pressures act on viral antigens to drive the emergence of mutated strains, against which initial therapies have reduced efficacy. To motivate our work, we consider antibody designs that target not only the current viral strains but also the wide range of possible future variants that the virus might evolve into under the evolutionary pressure exerted by said antibodies. Building on a computational model of binding between antibodies and viral antigens (the Absolut! framework), we design and implement a genetic simulation of the viral evolutionary escape. Crucially, this allows our antibody optimisation algorithm to consider and influence the entire escape curve of the virus, i.e. to guide (or ''shape'') the viral evolution. This is inspired by opponent shaping which, in general-sum learning, accounts for the adaptation of the co-player rather than playing a myopic best response. Hence we call the optimised antibodies shapers. Within our simulations, we demonstrate that our shapers target both current and simulated future viral variants, outperforming the antibodies chosen in a myopic way. Furthermore, we show that shapers exert specific evolutionary pressure on the virus compared to myopic antibodies. Altogether, shapers modify the evolutionary trajectories of viral strains and minimise the viral escape compared to their myopic counterparts. While this is a simple model, we hope that our proposed paradigm will enable the discovery of better long-lived vaccines and antibody therapies in the future, enabled by rapid advancements in the capabilities of simulation tools.
Learning to Prune Deep Neural Networks via Reinforcement Learning
Jul 09, 2020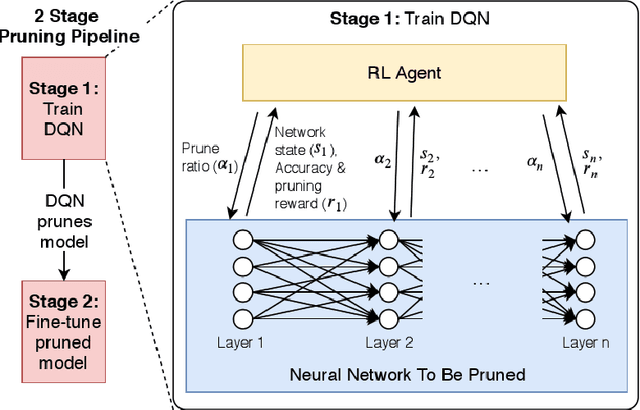
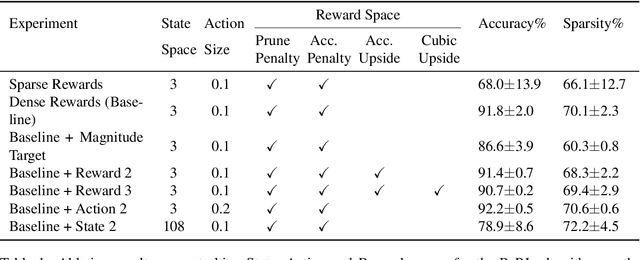
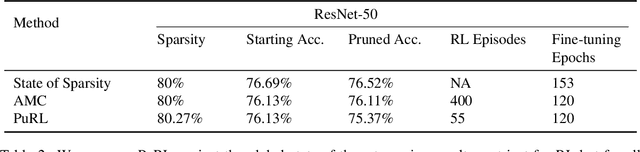
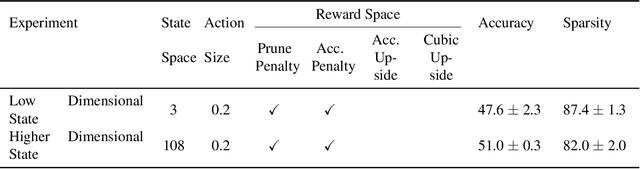
This paper proposes PuRL - a deep reinforcement learning (RL) based algorithm for pruning neural networks. Unlike current RL based model compression approaches where feedback is given only at the end of each episode to the agent, PuRL provides rewards at every pruning step. This enables PuRL to achieve sparsity and accuracy comparable to current state-of-the-art methods, while having a much shorter training cycle. PuRL achieves more than 80% sparsity on the ResNet-50 model while retaining a Top-1 accuracy of 75.37% on the ImageNet dataset. Through our experiments we show that PuRL is also able to sparsify already efficient architectures like MobileNet-V2. In addition to performance characterisation experiments, we also provide a discussion and analysis of the various RL design choices that went into the tuning of the Markov Decision Process underlying PuRL. Lastly, we point out that PuRL is simple to use and can be easily adapted for various architectures.