 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Manage Investment Portfolios beyond Simple Utility Functions
Oct 30, 2025



While investment funds publicly disclose their objectives in broad terms, their managers optimize for complex combinations of competing goals that go beyond simple risk-return trade-offs. Traditional approaches attempt to model this through multi-objective utility functions, but face fundamental challenges in specification and parameterization. We propose a generative framework that learns latent representations of fund manager strategies without requiring explicit utility specification. Our approach directly models the conditional probability of a fund's portfolio weights, given stock characteristics, historical returns, previous weights, and a latent variable representing the fund's strategy. Unlike methods based on reinforcement learning or imitation learning, which require specified rewards or labeled expert objectives, our GAN-based architecture learns directly from the joint distribution of observed holdings and market data. We validate our framework on a dataset of 1436 U.S. equity mutual funds. The learned representations successfully capture known investment styles, such as "growth" and "value," while also revealing implicit manager objectives. For instance, we find that while many funds exhibit characteristics of Markowitz-like optimization, they do so with heterogeneous realizations for turnover, concentration, and latent factors. To analyze and interpret the end-to-end model, we develop a series of tests that explain the model, and we show that the benchmark's expert labeling are contained in our model's encoding in a linear interpretable way. Our framework provides a data-driven approach for characterizing investment strategies for applications in market simulation, strategy attribution, and regulatory oversight.
Using causal abstractions to accelerate decision-making in complex bandit problems
Sep 04, 2025Although real-world decision-making problems can often be encoded as causal multi-armed bandits (CMABs) at different levels of abstraction, a general methodology exploiting the information and computational advantages of each abstraction level is missing. In this paper, we propose AT-UCB, an algorithm which efficiently exploits shared information between CMAB problem instances defined at different levels of abstraction. More specifically, AT-UCB leverages causal abstraction (CA) theory to explore within a cheap-to-simulate and coarse-grained CMAB instance, before employing the traditional upper confidence bound (UCB) algorithm on a restricted set of potentially optimal actions in the CMAB of interest, leading to significant reductions in cumulative regret when compared to the classical UCB algorithm. We illustrate the advantages of AT-UCB theoretically, through a novel upper bound on the cumulative regret, and empirically, by applying AT-UCB to epidemiological simulators with varying resolution and computational cost.
Automatic Differentiation of Agent-Based Models
Sep 03, 2025Agent-based models (ABMs) simulate complex systems by capturing the bottom-up interactions of individual agents comprising the system. Many complex systems of interest, such as epidemics or financial markets, involve thousands or even millions of agents. Consequently, ABMs often become computationally demanding and rely on the calibration of numerous free parameters, which has significantly hindered their widespread adoption. In this paper, we demonstrate that automatic differentiation (AD) techniques can effectively alleviate these computational burdens. By applying AD to ABMs, the gradients of the simulator become readily available, greatly facilitating essential tasks such as calibration and sensitivity analysis. Specifically, we show how AD enables variational inference (VI) techniques for efficient parameter calibration. Our experiments demonstrate substantial performance improvements and computational savings using VI on three prominent ABMs: Axtell's model of firms; Sugarscape; and the SIR epidemiological model. Our approach thus significantly enhances the practicality and scalability of ABMs for studying complex systems.
Ad-Hoc Human-AI Coordination Challenge
Jun 26, 2025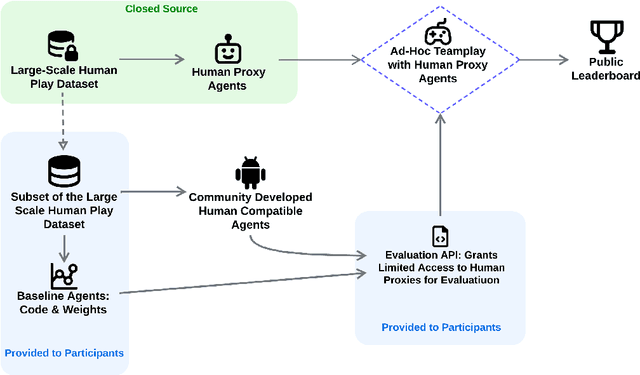

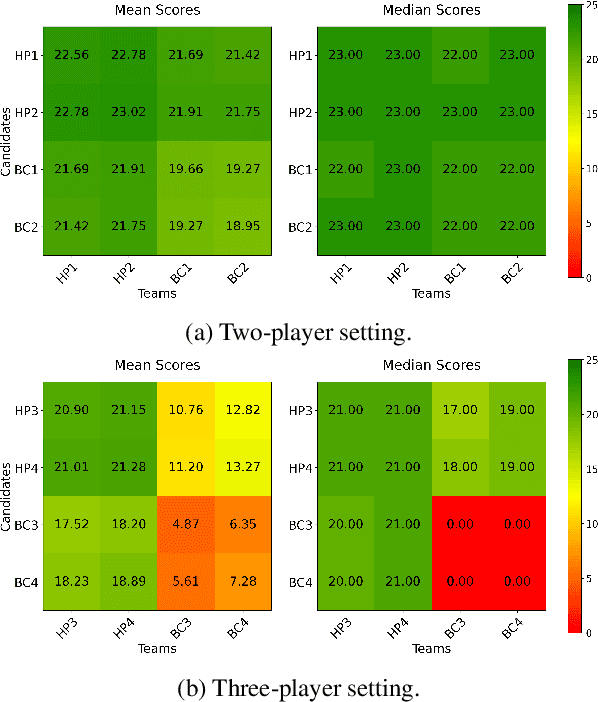

Achieving seamless coordination between AI agents and humans is crucial for real-world applications, yet it remains a significant open challenge. Hanabi is a cooperative card game featuring imperfect information, constrained communication, theory of mind requirements, and coordinated action -- making it an ideal testbed for human-AI coordination. However, its use for human-AI interaction has been limited by the challenges of human evaluation. In this work, we introduce the Ad-Hoc Human-AI Coordination Challenge (AH2AC2) to overcome the constraints of costly and difficult-to-reproduce human evaluations. We develop \textit{human proxy agents} on a large-scale human dataset that serve as robust, cheap, and reproducible human-like evaluation partners in AH2AC2. To encourage the development of data-efficient methods, we open-source a dataset of 3,079 games, deliberately limiting the amount of available human gameplay data. We present baseline results for both two- and three- player Hanabi scenarios. To ensure fair evaluation, we host the proxy agents through a controlled evaluation system rather than releasing them publicly. The code is available at \href{https://github.com/FLAIROx/ah2ac2}{https://github.com/FLAIROx/ah2ac2}.
IMAGIC-500: IMputation benchmark on A Generative Imaginary Country (500k samples)
Jun 10, 2025Missing data imputation in tabular datasets remains a pivotal challenge in data science and machine learning, particularly within socioeconomic research. However, real-world socioeconomic datasets are typically subject to strict data protection protocols, which often prohibit public sharing, even for synthetic derivatives. This severely limits the reproducibility and accessibility of benchmark studies in such settings. Further, there are very few publicly available synthetic datasets. Thus, there is limited availability of benchmarks for systematic evaluation of imputation methods on socioeconomic datasets, whether real or synthetic. In this study, we utilize the World Bank's publicly available synthetic dataset, Synthetic Data for an Imaginary Country, which closely mimics a real World Bank household survey while being fully public, enabling broad access for methodological research. With this as a starting point, we derived the IMAGIC-500 dataset: we select a subset of 500k individuals across approximately 100k households with 19 socioeconomic features, designed to reflect the hierarchical structure of real-world household surveys. This paper introduces a comprehensive missing data imputation benchmark on IMAGIC-500 under various missing mechanisms (MCAR, MAR, MNAR) and missingness ratios (10\%, 20\%, 30\%, 40\%, 50\%). Our evaluation considers the imputation accuracy for continuous and categorical variables, computational efficiency, and impact on downstream predictive tasks, such as estimating educational attainment at the individual level. The results highlight the strengths and weaknesses of statistical, traditional machine learning, and deep learning imputation techniques, including recent diffusion-based methods. The IMAGIC-500 dataset and benchmark aim to facilitate the development of robust imputation algorithms and foster reproducible social science research.
SAGE: Scalable Ground Truth Evaluations for Large Sparse Autoencoders
Oct 09, 2024


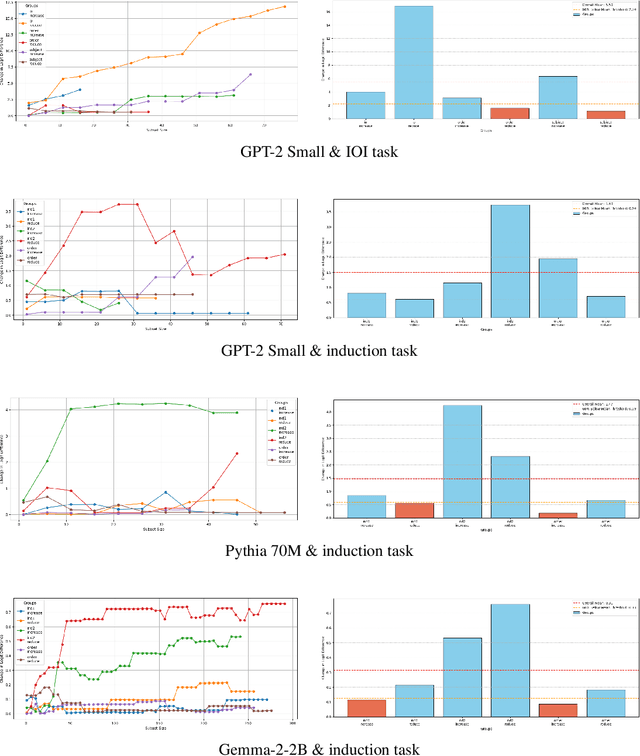
A key challenge in interpretability is to decompose model activations into meaningful features. Sparse autoencoders (SAEs) have emerged as a promising tool for this task. However, a central problem in evaluating the quality of SAEs is the absence of ground truth features to serve as an evaluation gold standard. Current evaluation methods for SAEs are therefore confronted with a significant trade-off: SAEs can either leverage toy models or other proxies with predefined ground truth features; or they use extensive prior knowledge of realistic task circuits. The former limits the generalizability of the evaluation results, while the latter limits the range of models and tasks that can be used for evaluations. We introduce SAGE: Scalable Autoencoder Ground-truth Evaluation, a ground truth evaluation framework for SAEs that scales to large state-of-the-art SAEs and models. We demonstrate that our method can automatically identify task-specific activations and compute ground truth features at these points. Compared to previous methods we reduce the training overhead by introducing a novel reconstruction method that allows to apply residual stream SAEs to sublayer activations. This eliminates the need for SAEs trained on every task-specific activation location. Then we validate the scalability of our framework, by evaluating SAEs on novel tasks on Pythia70M, GPT-2 Small, and Gemma-2-2. Our framework therefore paves the way for generalizable, large-scale evaluations of SAEs in interpretability research.
A multi-objective combinatorial optimisation framework for large scale hierarchical population synthesis
Jul 03, 2024



In agent-based simulations, synthetic populations of agents are commonly used to represent the structure, behaviour, and interactions of individuals. However, generating a synthetic population that accurately reflects real population statistics is a challenging task, particularly when performed at scale. In this paper, we propose a multi objective combinatorial optimisation technique for large scale population synthesis. We demonstrate the effectiveness of our approach by generating a synthetic population for selected regions and validating it on contingency tables from real population data. Our approach supports complex hierarchical structures between individuals and households, is scalable to large populations and achieves minimal contigency table reconstruction error. Hence, it provides a useful tool for policymakers and researchers for simulating the dynamics of complex populations.
Causally Abstracted Multi-armed Bandits
Apr 26, 2024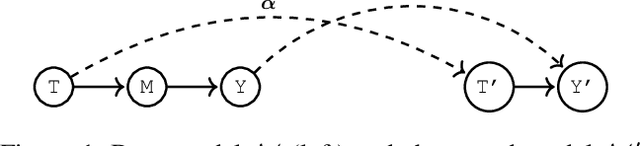


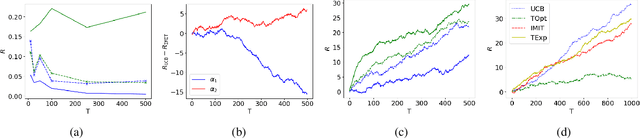
Multi-armed bandits (MAB) and causal MABs (CMAB) are established frameworks for decision-making problems. The majority of prior work typically studies and solves individual MAB and CMAB in isolation for a given problem and associated data. However, decision-makers are often faced with multiple related problems and multi-scale observations where joint formulations are needed in order to efficiently exploit the problem structures and data dependencies. Transfer learning for CMABs addresses the situation where models are defined on identical variables, although causal connections may differ. In this work, we extend transfer learning to setups involving CMABs defined on potentially different variables, with varying degrees of granularity, and related via an abstraction map. Formally, we introduce the problem of causally abstracted MABs (CAMABs) by relying on the theory of causal abstraction in order to express a rigorous abstraction map. We propose algorithms to learn in a CAMAB, and study their regret. We illustrate the limitations and the strengths of our algorithms on a real-world scenario related to online advertising.
Interventionally Consistent Surrogates for Agent-based Simulators
Dec 18, 2023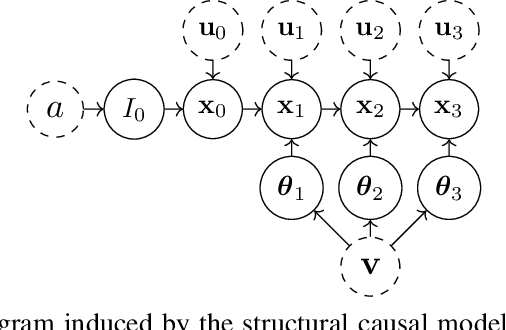
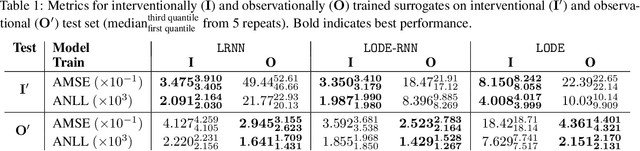
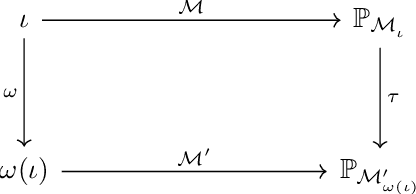
Agent-based simulators provide granular representations of complex intelligent systems by directly modelling the interactions of the system's constituent agents. Their high-fidelity nature enables hyper-local policy evaluation and testing of what-if scenarios, but is associated with large computational costs that inhibits their widespread use. Surrogate models can address these computational limitations, but they must behave consistently with the agent-based model under policy interventions of interest. In this paper, we capitalise on recent developments on causal abstractions to develop a framework for learning interventionally consistent surrogate models for agent-based simulators. Our proposed approach facilitates rapid experimentation with policy interventions in complex systems, while inducing surrogates to behave consistently with high probability with respect to the agent-based simulator across interventions of interest. We demonstrate with empirical studies that observationally trained surrogates can misjudge the effect of interventions and misguide policymakers towards suboptimal policies, while surrogates trained for interventional consistency with our proposed method closely mimic the behaviour of an agent-based model under interventions of interest.
JAX-LOB: A GPU-Accelerated limit order book simulator to unlock large scale reinforcement learning for trading
Aug 25, 2023

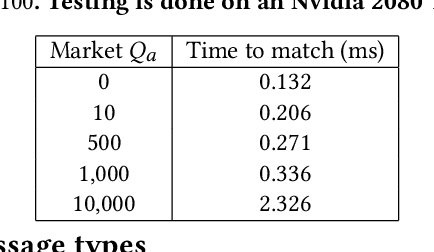
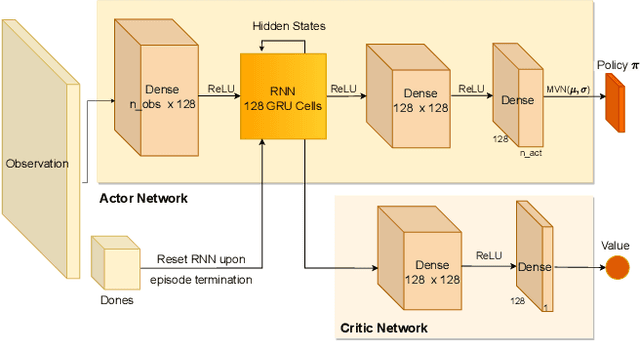
Financial exchanges across the world use limit order books (LOBs) to process orders and match trades. For research purposes it is important to have large scale efficient simulators of LOB dynamics. LOB simulators have previously been implemented in the context of agent-based models (ABMs), reinforcement learning (RL) environments, and generative models, processing order flows from historical data sets and hand-crafted agents alike. For many applications, there is a requirement for processing multiple books, either for the calibration of ABMs or for the training of RL agents. We showcase the first GPU-enabled LOB simulator designed to process thousands of books in parallel, with a notably reduced per-message processing time. The implementation of our simulator - JAX-LOB - is based on design choices that aim to best exploit the powers of JAX without compromising on the realism of LOB-related mechanisms. We integrate JAX-LOB with other JAX packages, to provide an example of how one may address an optimal execution problem with reinforcement learning, and to share some preliminary results from end-to-end RL training on GPUs.