 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Multimodal Fine-Tuning: Spatial Features
Feb 06, 2026Contemporary Vision-Language Models (VLMs) achieve strong performance on a wide range of tasks by pairing a vision encoder with a pre-trained language model, fine-tuned for visual-text inputs. Yet despite these gains, it remains unclear how language backbone representations adapt during multimodal training and when vision-specific capabilities emerge. In this work, we present the first mechanistic analysis of VLM adaptation. Using stage-wise model diffing, a technique that isolates representational changes introduced during multimodal fine-tuning, we reveal how a language model learns to "see". We first identify vision-preferring features that emerge or reorient during fine-tuning. We then show that a selective subset of these features reliably encodes spatial relations, revealed through controlled shifts to spatial prompts. Finally, we trace the causal activation of these features to a small group of attention heads. Our findings show that stage-wise model diffing reveals when and where spatially grounded multimodal features arise. It also provides a clearer view of modality fusion by showing how visual grounding reshapes features that were previously text-only. This methodology enhances the interpretability of multimodal training and provides a foundation for understanding and refining how pretrained language models acquire vision-grounded capabilities.
Sparse CLIP: Co-Optimizing Interpretability and Performance in Contrastive Learning
Jan 27, 2026Contrastive Language-Image Pre-training (CLIP) has become a cornerstone in vision-language representation learning, powering diverse downstream tasks and serving as the default vision backbone in multimodal large language models (MLLMs). Despite its success, CLIP's dense and opaque latent representations pose significant interpretability challenges. A common assumption is that interpretability and performance are in tension: enforcing sparsity during training degrades accuracy, motivating recent post-hoc approaches such as Sparse Autoencoders (SAEs). However, these post-hoc approaches often suffer from degraded downstream performance and loss of CLIP's inherent multimodal capabilities, with most learned features remaining unimodal. We propose a simple yet effective approach that integrates sparsity directly into CLIP training, yielding representations that are both interpretable and performant. Compared to SAEs, our Sparse CLIP representations preserve strong downstream task performance, achieve superior interpretability, and retain multimodal capabilities. We show that multimodal sparse features enable straightforward semantic concept alignment and reveal training dynamics of how cross-modal knowledge emerges. Finally, as a proof of concept, we train a vision-language model on sparse CLIP representations that enables interpretable, vision-based steering capabilities. Our findings challenge conventional wisdom that interpretability requires sacrificing accuracy and demonstrate that interpretability and performance can be co-optimized, offering a promising design principle for future models.
How Visual Representations Map to Language Feature Space in Multimodal LLMs
Jun 13, 2025Effective multimodal reasoning depends on the alignment of visual and linguistic representations, yet the mechanisms by which vision-language models (VLMs) achieve this alignment remain poorly understood. We introduce a methodological framework that deliberately maintains a frozen large language model (LLM) and a frozen vision transformer (ViT), connected solely by training a linear adapter during visual instruction tuning. This design is fundamental to our approach: by keeping the language model frozen, we ensure it maintains its original language representations without adaptation to visual data. Consequently, the linear adapter must map visual features directly into the LLM's existing representational space rather than allowing the language model to develop specialized visual understanding through fine-tuning. Our experimental design uniquely enables the use of pre-trained sparse autoencoders (SAEs) of the LLM as analytical probes. These SAEs remain perfectly aligned with the unchanged language model and serve as a snapshot of the learned language feature-representations. Through systematic analysis of SAE reconstruction error, sparsity patterns, and feature SAE descriptions, we reveal the layer-wise progression through which visual representations gradually align with language feature representations, converging in middle-to-later layers. This suggests a fundamental misalignment between ViT outputs and early LLM layers, raising important questions about whether current adapter-based architectures optimally facilitate cross-modal representation learning.
SAGE: Scalable Ground Truth Evaluations for Large Sparse Autoencoders
Oct 09, 2024


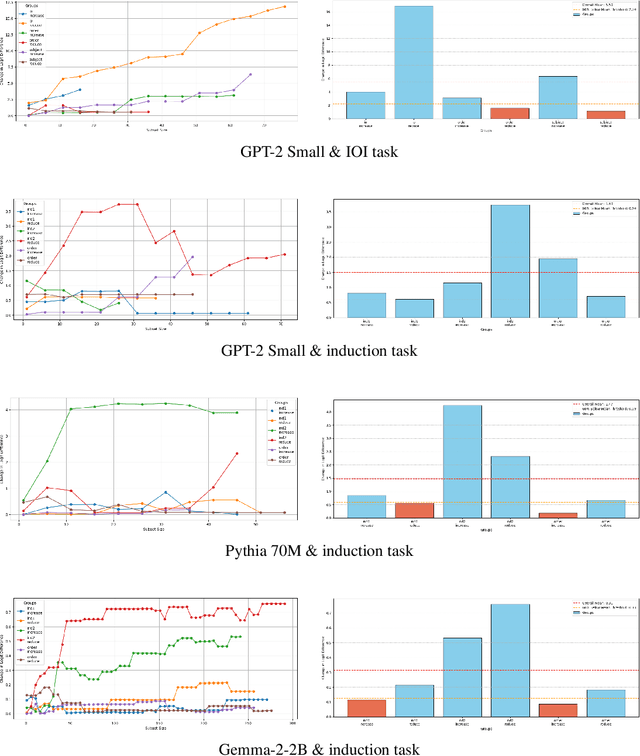
A key challenge in interpretability is to decompose model activations into meaningful features. Sparse autoencoders (SAEs) have emerged as a promising tool for this task. However, a central problem in evaluating the quality of SAEs is the absence of ground truth features to serve as an evaluation gold standard. Current evaluation methods for SAEs are therefore confronted with a significant trade-off: SAEs can either leverage toy models or other proxies with predefined ground truth features; or they use extensive prior knowledge of realistic task circuits. The former limits the generalizability of the evaluation results, while the latter limits the range of models and tasks that can be used for evaluations. We introduce SAGE: Scalable Autoencoder Ground-truth Evaluation, a ground truth evaluation framework for SAEs that scales to large state-of-the-art SAEs and models. We demonstrate that our method can automatically identify task-specific activations and compute ground truth features at these points. Compared to previous methods we reduce the training overhead by introducing a novel reconstruction method that allows to apply residual stream SAEs to sublayer activations. This eliminates the need for SAEs trained on every task-specific activation location. Then we validate the scalability of our framework, by evaluating SAEs on novel tasks on Pythia70M, GPT-2 Small, and Gemma-2-2. Our framework therefore paves the way for generalizable, large-scale evaluations of SAEs in interpretability research.