 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeleological Inference in Structural Causal Models via Intentional Interventions
Mar 19, 2026Structural causal models (SCMs) were conceived to formulate and answer causal questions. This paper shows that SCMs can also be used to formulate and answer teleological questions, concerning the intentions of a state-aware, goal-directed agent intervening in a causal system. We review limitations of previous approaches to modeling such agents, and then introduce intentional interventions, a new time-agnostic operator that induces a twin SCM we call a structural final model (SFM). SFMs treat observed values as the outcome of intentional interventions and relate them to the counterfactual conditions of those interventions (what would have happened had the agent not intervened). We show how SFMs can be used to empirically detect agents and to discover their intentions.
Multi-Level Causal Embeddings
Feb 25, 2026Abstractions of causal models allow for the coarsening of models such that relations of cause and effect are preserved. Whereas abstractions focus on the relation between two models, in this paper we study a framework for causal embeddings which enable multiple detailed models to be mapped into sub-systems of a coarser causal model. We define causal embeddings as a generalization of abstraction, and present a generalized notion of consistency. By defining a multi-resolution marginal problem, we showcase the relevance of causal embeddings for both the statistical marginal problem and the causal marginal problem; furthermore, we illustrate its practical use in merging datasets coming from models with different representations.
Using causal abstractions to accelerate decision-making in complex bandit problems
Sep 04, 2025
Although real-world decision-making problems can often be encoded as causal multi-armed bandits (CMABs) at different levels of abstraction, a general methodology exploiting the information and computational advantages of each abstraction level is missing. In this paper, we propose AT-UCB, an algorithm which efficiently exploits shared information between CMAB problem instances defined at different levels of abstraction. More specifically, AT-UCB leverages causal abstraction (CA) theory to explore within a cheap-to-simulate and coarse-grained CMAB instance, before employing the traditional upper confidence bound (UCB) algorithm on a restricted set of potentially optimal actions in the CMAB of interest, leading to significant reductions in cumulative regret when compared to the classical UCB algorithm. We illustrate the advantages of AT-UCB theoretically, through a novel upper bound on the cumulative regret, and empirically, by applying AT-UCB to epidemiological simulators with varying resolution and computational cost.
Aligning Graphical and Functional Causal Abstractions
Dec 22, 2024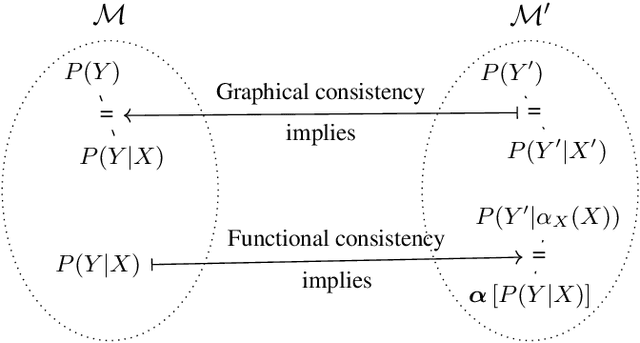


Causal abstractions allow us to relate causal models on different levels of granularity. To ensure that the models agree on cause and effect, frameworks for causal abstractions define notions of consistency. Two distinct methods for causal abstraction are common in the literature: (i) graphical abstractions, such as Cluster DAGs, which relate models on a structural level, and (ii) functional abstractions, like $\alpha$-abstractions, which relate models by maps between variables and their ranges. In this paper we will align the notions of graphical and functional consistency and show an equivalence between the class of Cluster DAGs, consistent $\alpha$-abstractions, and constructive $\tau$-abstractions. Furthermore, we extend this alignment and the expressivity of graphical abstractions by introducing Partial Cluster DAGs. Our results provide a rigorous bridge between the functional and graphical frameworks and allow for adoption and transfer of results between them.
Causally Abstracted Multi-armed Bandits
Apr 26, 2024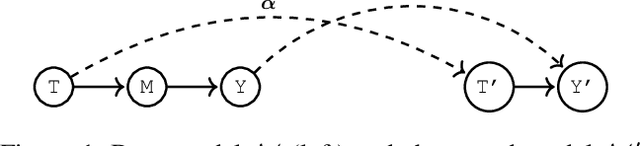


Multi-armed bandits (MAB) and causal MABs (CMAB) are established frameworks for decision-making problems. The majority of prior work typically studies and solves individual MAB and CMAB in isolation for a given problem and associated data. However, decision-makers are often faced with multiple related problems and multi-scale observations where joint formulations are needed in order to efficiently exploit the problem structures and data dependencies. Transfer learning for CMABs addresses the situation where models are defined on identical variables, although causal connections may differ. In this work, we extend transfer learning to setups involving CMABs defined on potentially different variables, with varying degrees of granularity, and related via an abstraction map. Formally, we introduce the problem of causally abstracted MABs (CAMABs) by relying on the theory of causal abstraction in order to express a rigorous abstraction map. We propose algorithms to learn in a CAMAB, and study their regret. We illustrate the limitations and the strengths of our algorithms on a real-world scenario related to online advertising.
Interventionally Consistent Surrogates for Agent-based Simulators
Dec 18, 2023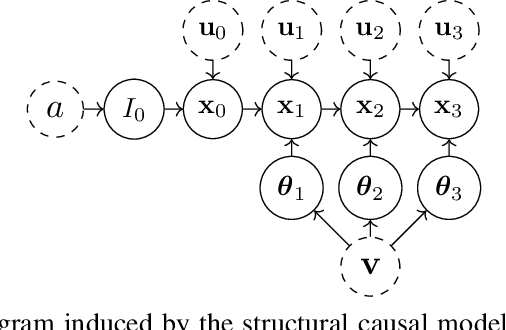
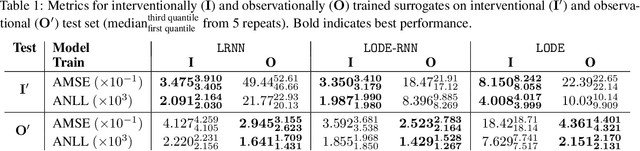
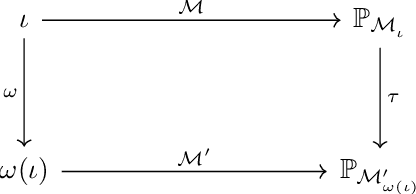
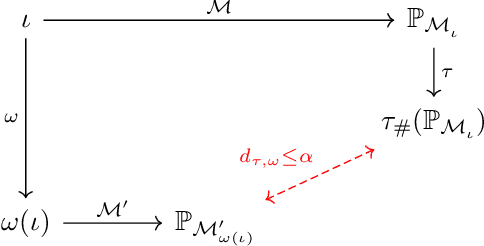
Agent-based simulators provide granular representations of complex intelligent systems by directly modelling the interactions of the system's constituent agents. Their high-fidelity nature enables hyper-local policy evaluation and testing of what-if scenarios, but is associated with large computational costs that inhibits their widespread use. Surrogate models can address these computational limitations, but they must behave consistently with the agent-based model under policy interventions of interest. In this paper, we capitalise on recent developments on causal abstractions to develop a framework for learning interventionally consistent surrogate models for agent-based simulators. Our proposed approach facilitates rapid experimentation with policy interventions in complex systems, while inducing surrogates to behave consistently with high probability with respect to the agent-based simulator across interventions of interest. We demonstrate with empirical studies that observationally trained surrogates can misjudge the effect of interventions and misguide policymakers towards suboptimal policies, while surrogates trained for interventional consistency with our proposed method closely mimic the behaviour of an agent-based model under interventions of interest.
Causal Optimal Transport of Abstractions
Dec 13, 2023



Causal abstraction (CA) theory establishes formal criteria for relating multiple structural causal models (SCMs) at different levels of granularity by defining maps between them. These maps have significant relevance for real-world challenges such as synthesizing causal evidence from multiple experimental environments, learning causally consistent representations at different resolutions, and linking interventions across multiple SCMs. In this work, we propose COTA, the first method to learn abstraction maps from observational and interventional data without assuming complete knowledge of the underlying SCMs. In particular, we introduce a multi-marginal Optimal Transport (OT) formulation that enforces do-calculus causal constraints, together with a cost function that relies on interventional information. We extensively evaluate COTA on synthetic and real world problems, and showcase its advantages over non-causal, independent and aggregated COTA formulations. Finally, we demonstrate the efficiency of our method as a data augmentation tool by comparing it against the state-of-the-art CA learning framework, which assumes fully specified SCMs, on a real-world downstream task.
Quantifying Consistency and Information Loss for Causal Abstraction Learning
May 07, 2023



Structural causal models provide a formalism to express causal relations between variables of interest. Models and variables can represent a system at different levels of abstraction, whereby relations may be coarsened and refined according to the need of a modeller. However, switching between different levels of abstraction requires evaluating a trade-off between the consistency and the information loss among different models. In this paper we introduce a family of interventional measures that an agent may use to evaluate such a trade-off. We consider four measures suited for different tasks, analyze their properties, and propose algorithms to evaluate and learn causal abstractions. Finally, we illustrate the flexibility of our setup by empirically showing how different measures and algorithmic choices may lead to different abstractions.
Jointly Learning Consistent Causal Abstractions Over Multiple Interventional Distributions
Jan 14, 2023An abstraction can be used to relate two structural causal models representing the same system at different levels of resolution. Learning abstractions which guarantee consistency with respect to interventional distributions would allow one to jointly reason about evidence across multiple levels of granularity while respecting the underlying cause-effect relationships. In this paper, we introduce a first framework for causal abstraction learning between SCMs based on the formalization of abstraction recently proposed by Rischel (2020). Based on that, we propose a differentiable programming solution that jointly solves a number of combinatorial sub-problems, and we study its performance and benefits against independent and sequential approaches on synthetic settings and on a challenging real-world problem related to electric vehicle battery manufacturing.
Towards Computing an Optimal Abstraction for Structural Causal Models
Aug 01, 2022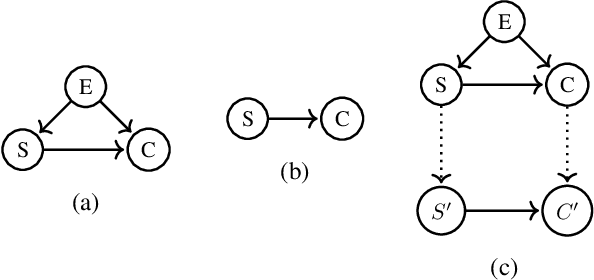
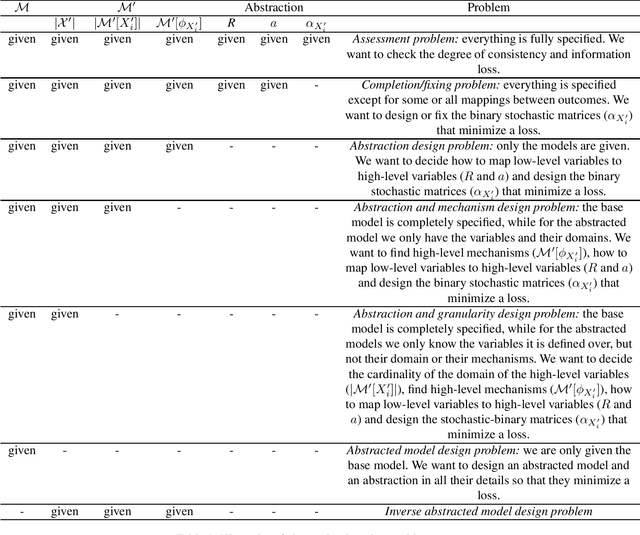
Working with causal models at different levels of abstraction is an important feature of science. Existing work has already considered the problem of expressing formally the relation of abstraction between causal models. In this paper, we focus on the problem of learning abstractions. We start by defining the learning problem formally in terms of the optimization of a standard measure of consistency. We then point out the limitation of this approach, and we suggest extending the objective function with a term accounting for information loss. We suggest a concrete measure of information loss, and we illustrate its contribution to learning new abstractions.