 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvIL: Evolution Strategies for Generalisable Imitation Learning
Paper and Code
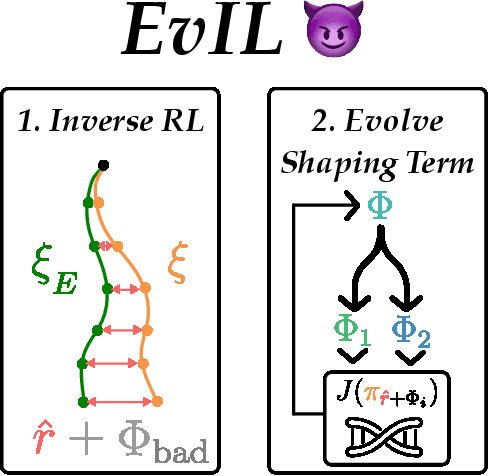
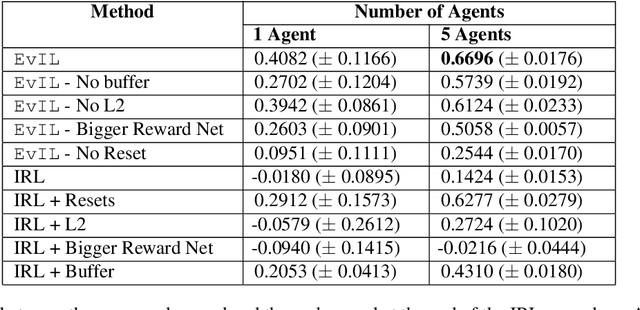


Often times in imitation learning (IL), the environment we collect expert demonstrations in and the environment we want to deploy our learned policy in aren't exactly the same (e.g. demonstrations collected in simulation but deployment in the real world). Compared to policy-centric approaches to IL like behavioural cloning, reward-centric approaches like inverse reinforcement learning (IRL) often better replicate expert behaviour in new environments. This transfer is usually performed by optimising the recovered reward under the dynamics of the target environment. However, (a) we find that modern deep IL algorithms frequently recover rewards which induce policies far weaker than the expert, even in the same environment the demonstrations were collected in. Furthermore, (b) these rewards are often quite poorly shaped, necessitating extensive environment interaction to optimise effectively. We provide simple and scalable fixes to both of these concerns. For (a), we find that reward model ensembles combined with a slightly different training objective significantly improves re-training and transfer performance. For (b), we propose a novel evolution-strategies based method EvIL to optimise for a reward-shaping term that speeds up re-training in the target environment, closing a gap left open by the classical theory of IRL. On a suite of continuous control tasks, we are able to re-train policies in target (and source) environments more interaction-efficiently than prior work.