 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOvolve: Adversarial Co-Evolution of Large-Language-Model-Generated Policies and Environments via Two-Player Zero-Sum Game
Mar 30, 2026A central challenge in building continually improving agents is that training environments are typically static or manually constructed. This restricts continual learning and generalization beyond the training distribution. We address this with COvolve, a co-evolutionary framework that leverages large language models (LLMs) to generate both environments and agent policies, expressed as executable Python code. We model the interaction between environment and policy designers as a two-player zero-sum game, ensuring adversarial co-evolution in which environments expose policy weaknesses and policies adapt in response. This process induces an automated curriculum in which environments and policies co-evolve toward increasing complexity. To guarantee robustness and prevent forgetting as the curriculum progresses, we compute the mixed-strategy Nash equilibrium (MSNE) of the zero-sum game, thereby yielding a meta-policy. This MSNE meta-policy ensures that the agent does not forget to solve previously seen environments while learning to solve previously unseen ones. Experiments in urban driving, symbolic maze-solving, and geometric navigation showcase that COvolve produces progressively more complex environments. Our results demonstrate the potential of LLM-driven co-evolution to achieve open-ended learning without predefined task distributions or manual intervention.
AIRA_2: Overcoming Bottlenecks in AI Research Agents
Mar 27, 2026Existing research has identified three structural performance bottlenecks in AI research agents: (1) synchronous single-GPU execution constrains sample throughput, limiting the benefit of search; (2) a generalization gap where validation-based selection causes performance to degrade over extended search horizons; and (3) the limited capability of fixed, single-turn LLM operators imposes a ceiling on search performance. We introduce AIRA$_2$, which addresses these bottlenecks through three architectural choices: an asynchronous multi-GPU worker pool that increases experiment throughput linearly; a Hidden Consistent Evaluation protocol that delivers a reliable evaluation signal; and ReAct agents that dynamically scope their actions and debug interactively. On MLE-bench-30, AIRA$_2$ achieves a mean Percentile Rank of 71.8% at 24 hours - surpassing the previous best of 69.9% - and steadily improves to 76.0% at 72 hours. Ablation studies reveal that each component is necessary and that the "overfitting" reported in prior work was driven by evaluation noise rather than true data memorization.
Training AI Co-Scientists Using Rubric Rewards
Dec 29, 2025AI co-scientists are emerging as a tool to assist human researchers in achieving their research goals. A crucial feature of these AI co-scientists is the ability to generate a research plan given a set of aims and constraints. The plan may be used by researchers for brainstorming, or may even be implemented after further refinement. However, language models currently struggle to generate research plans that follow all constraints and implicit requirements. In this work, we study how to leverage the vast corpus of existing research papers to train language models that generate better research plans. We build a scalable, diverse training corpus by automatically extracting research goals and goal-specific grading rubrics from papers across several domains. We then train models for research plan generation via reinforcement learning with self-grading. A frozen copy of the initial policy acts as the grader during training, with the rubrics creating a generator-verifier gap that enables improvements without external human supervision. To validate this approach, we conduct a study with human experts for machine learning research goals, spanning 225 hours. The experts prefer plans generated by our finetuned Qwen3-30B-A3B model over the initial model for 70% of research goals, and approve 84% of the automatically extracted goal-specific grading rubrics. To assess generality, we also extend our approach to research goals from medical papers, and new arXiv preprints, evaluating with a jury of frontier models. Our finetuning yields 12-22% relative improvements and significant cross-domain generalization, proving effective even in problem settings like medical research where execution feedback is infeasible. Together, these findings demonstrate the potential of a scalable, automated training recipe as a step towards improving general AI co-scientists.
What Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity
Nov 19, 2025AI research agents offer the promise to accelerate scientific progress by automating the design, implementation, and training of machine learning models. However, the field is still in its infancy, and the key factors driving the success or failure of agent trajectories are not fully understood. We examine the role that ideation diversity plays in agent performance. First, we analyse agent trajectories on MLE-bench, a well-known benchmark to evaluate AI research agents, across different models and agent scaffolds. Our analysis reveals that different models and agent scaffolds yield varying degrees of ideation diversity, and that higher-performing agents tend to have increased ideation diversity. Further, we run a controlled experiment where we modify the degree of ideation diversity, demonstrating that higher ideation diversity results in stronger performance. Finally, we strengthen our results by examining additional evaluation metrics beyond the standard medal-based scoring of MLE-bench, showing that our findings still hold across other agent performance metrics.
AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
Jul 03, 2025AI research agents are demonstrating great potential to accelerate scientific progress by automating the design, implementation, and training of machine learning models. We focus on methods for improving agents' performance on MLE-bench, a challenging benchmark where agents compete in Kaggle competitions to solve real-world machine learning problems. We formalize AI research agents as search policies that navigate a space of candidate solutions, iteratively modifying them using operators. By designing and systematically varying different operator sets and search policies (Greedy, MCTS, Evolutionary), we show that their interplay is critical for achieving high performance. Our best pairing of search strategy and operator set achieves a state-of-the-art result on MLE-bench lite, increasing the success rate of achieving a Kaggle medal from 39.6% to 47.7%. Our investigation underscores the importance of jointly considering the search strategy, operator design, and evaluation methodology in advancing automated machine learning.
Have Large Language Models Learned to Reason? A Characterization via 3-SAT Phase Transition
Apr 04, 2025Large Language Models (LLMs) have been touted as AI models possessing advanced reasoning abilities. In theory, autoregressive LLMs with Chain-of-Thought (CoT) can perform more serial computations to solve complex reasoning tasks. However, recent studies suggest that, despite this capacity, LLMs do not truly learn to reason but instead fit on statistical features. To study the reasoning capabilities in a principled fashion, we adopt a computational theory perspective and propose an experimental protocol centered on 3-SAT -- the prototypical NP-complete problem lying at the core of logical reasoning and constraint satisfaction tasks. Specifically, we examine the phase transitions in random 3-SAT and characterize the reasoning abilities of state-of-the-art LLMs by varying the inherent hardness of the problem instances. By comparing DeepSeek R1 with other LLMs, our findings reveal two key insights (1) LLM accuracy drops significantly on harder instances, suggesting all current models struggle when statistical shortcuts are unavailable (2) Unlike other LLMs, R1 shows signs of having learned the underlying reasoning. Following a principled experimental protocol, our study moves beyond the benchmark-driven evidence often found in LLM reasoning research. Our findings highlight important gaps and suggest clear directions for future research.
Evaluating Efficiency and Engagement in Scripted and LLM-Enhanced Human-Robot Interactions
Jan 21, 2025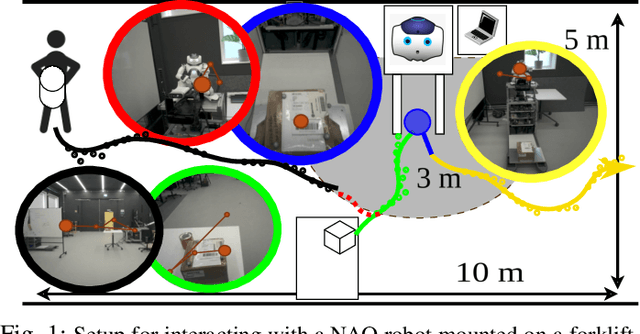
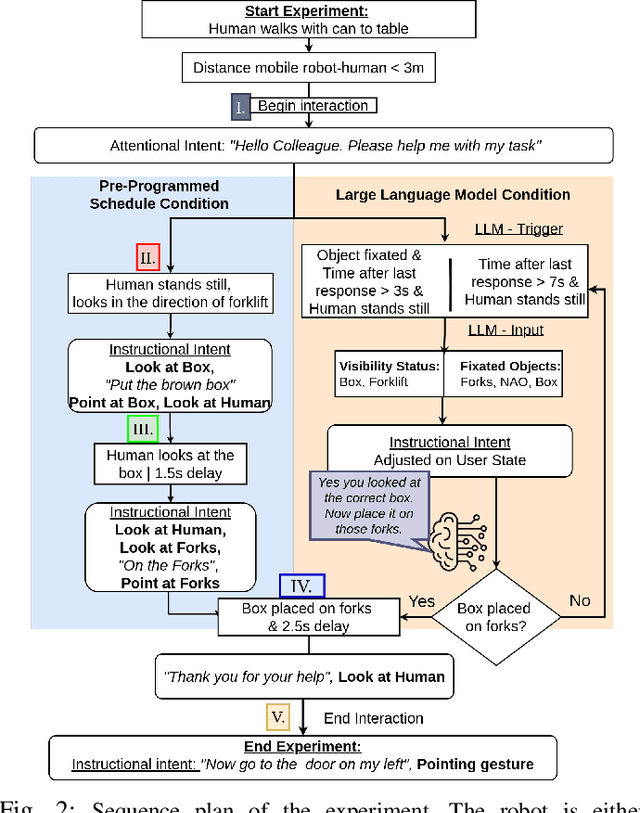

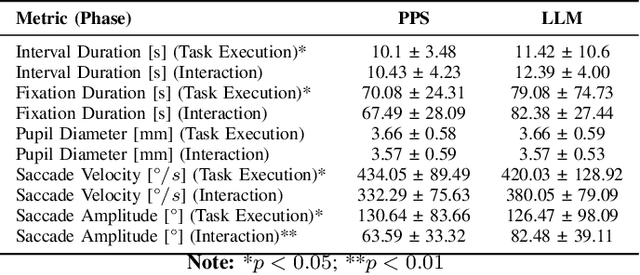
To achieve natural and intuitive interaction with people, HRI frameworks combine a wide array of methods for human perception, intention communication, human-aware navigation and collaborative action. In practice, when encountering unpredictable behavior of people or unexpected states of the environment, these frameworks may lack the ability to dynamically recognize such states, adapt and recover to resume the interaction. Large Language Models (LLMs), owing to their advanced reasoning capabilities and context retention, present a promising solution for enhancing robot adaptability. This potential, however, may not directly translate to improved interaction metrics. This paper considers a representative interaction with an industrial robot involving approach, instruction, and object manipulation, implemented in two conditions: (1) fully scripted and (2) including LLM-enhanced responses. We use gaze tracking and questionnaires to measure the participants' task efficiency, engagement, and robot perception. The results indicate higher subjective ratings for the LLM condition, but objective metrics show that the scripted condition performs comparably, particularly in efficiency and focus during simple tasks. We also note that the scripted condition may have an edge over LLM-enhanced responses in terms of response latency and energy consumption, especially for trivial and repetitive interactions.
Bidirectional Intent Communication: A Role for Large Foundation Models
Aug 20, 2024Integrating multimodal foundation models has significantly enhanced autonomous agents' language comprehension, perception, and planning capabilities. However, while existing works adopt a \emph{task-centric} approach with minimal human interaction, applying these models to developing assistive \emph{user-centric} robots that can interact and cooperate with humans remains underexplored. This paper introduces ``Bident'', a framework designed to integrate robots seamlessly into shared spaces with humans. Bident enhances the interactive experience by incorporating multimodal inputs like speech and user gaze dynamics. Furthermore, Bident supports verbal utterances and physical actions like gestures, making it versatile for bidirectional human-robot interactions. Potential applications include personalized education, where robots can adapt to individual learning styles and paces, and healthcare, where robots can offer personalized support, companionship, and everyday assistance in the home and workplace environments.
Can Large Language Models Reason? A Characterization via 3-SAT
Aug 13, 2024Large Language Models (LLMs) are said to possess advanced reasoning abilities. However, some skepticism exists as recent works show how LLMs often bypass true reasoning using shortcuts. Current methods for assessing the reasoning abilities of LLMs typically rely on open-source benchmarks that may be overrepresented in LLM training data, potentially skewing performance. We instead provide a computational theory perspective of reasoning, using 3-SAT -- the prototypical NP-complete problem that lies at the core of logical reasoning and constraint satisfaction tasks. By examining the phase transitions in 3-SAT, we empirically characterize the reasoning abilities of LLMs and show how they vary with the inherent hardness of the problems. Our experimental evidence shows that LLMs cannot perform true reasoning, as is required for solving 3-SAT problems.
REvolve: Reward Evolution with Large Language Models for Autonomous Driving
Jun 03, 2024Designing effective reward functions is crucial to training reinforcement learning (RL) algorithms. However, this design is non-trivial, even for domain experts, due to the subjective nature of certain tasks that are hard to quantify explicitly. In recent works, large language models (LLMs) have been used for reward generation from natural language task descriptions, leveraging their extensive instruction tuning and commonsense understanding of human behavior. In this work, we hypothesize that LLMs, guided by human feedback, can be used to formulate human-aligned reward functions. Specifically, we study this in the challenging setting of autonomous driving (AD), wherein notions of "good" driving are tacit and hard to quantify. To this end, we introduce REvolve, an evolutionary framework that uses LLMs for reward design in AD. REvolve creates and refines reward functions by utilizing human feedback to guide the evolution process, effectively translating implicit human knowledge into explicit reward functions for training (deep) RL agents. We demonstrate that agents trained on REvolve-designed rewards align closely with human driving standards, thereby outperforming other state-of-the-art baselines.