 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Offline RL via Efficient and Expressive Shortcut Models
May 28, 2025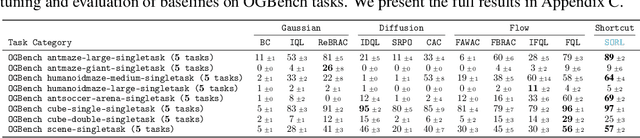
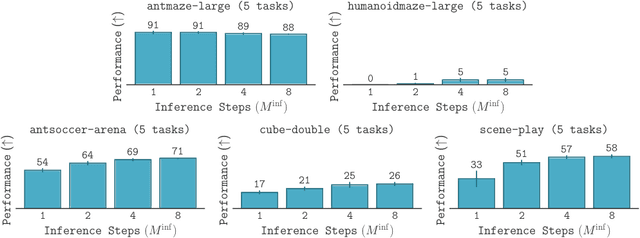
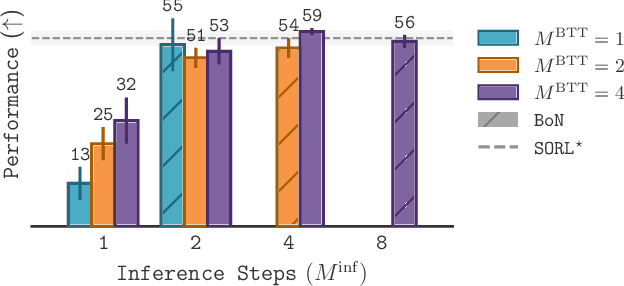
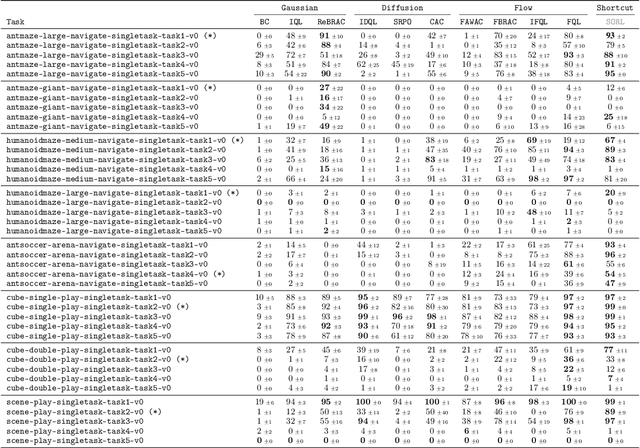
Diffusion and flow models have emerged as powerful generative approaches capable of modeling diverse and multimodal behavior. However, applying these models to offline reinforcement learning (RL) remains challenging due to the iterative nature of their noise sampling processes, making policy optimization difficult. In this paper, we introduce Scalable Offline Reinforcement Learning (SORL), a new offline RL algorithm that leverages shortcut models - a novel class of generative models - to scale both training and inference. SORL's policy can capture complex data distributions and can be trained simply and efficiently in a one-stage training procedure. At test time, SORL introduces both sequential and parallel inference scaling by using the learned Q-function as a verifier. We demonstrate that SORL achieves strong performance across a range of offline RL tasks and exhibits positive scaling behavior with increased test-time compute. We release the code at nico-espinosadice.github.io/projects/sorl.
Efficient Imitation Under Misspecification
Mar 17, 2025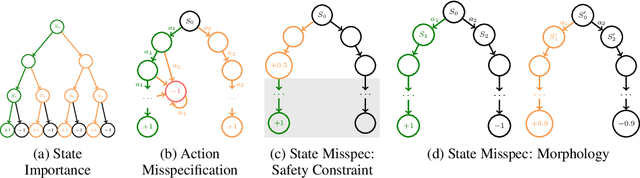
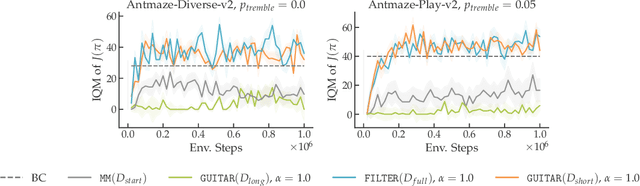

Interactive imitation learning (IL) is a powerful paradigm for learning to make sequences of decisions from an expert demonstrating how to perform a task. Prior work in efficient imitation learning has focused on the realizable setting, where the expert's policy lies within the learner's policy class (i.e. the learner can perfectly imitate the expert in all states). However, in practice, perfect imitation of the expert is often impossible due to differences in state information and action space expressiveness (e.g. morphological differences between robots and humans.) In this paper, we consider the more general misspecified setting, where no assumptions are made about the expert policy's realizability. We introduce a novel structural condition, reward-agnostic policy completeness, and prove that it is sufficient for interactive IL algorithms to efficiently avoid the quadratically compounding errors that stymie offline approaches like behavioral cloning. We address an additional practical constraint-the case of limited expert data-and propose a principled method for using additional offline data to further improve the sample-efficiency of interactive IL algorithms. Finally, we empirically investigate the optimal reset distribution in efficient IL under misspecification with a suite of continuous control tasks.