 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProVox: Personalization and Proactive Planning for Situated Human-Robot Collaboration
Jun 13, 2025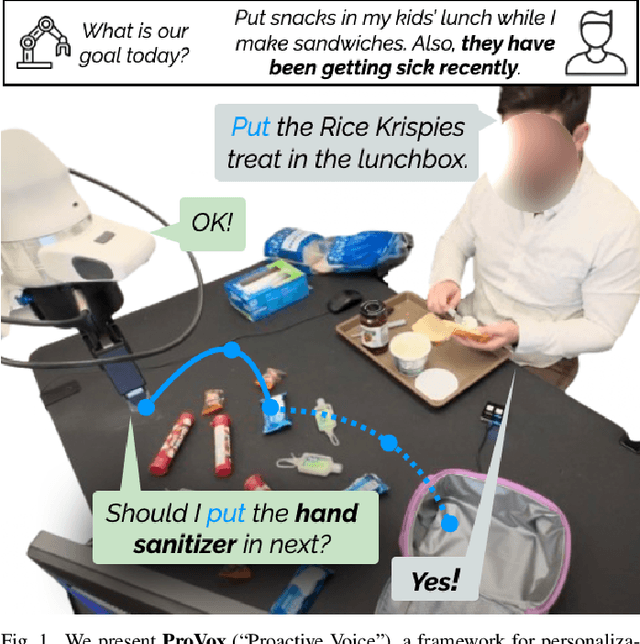

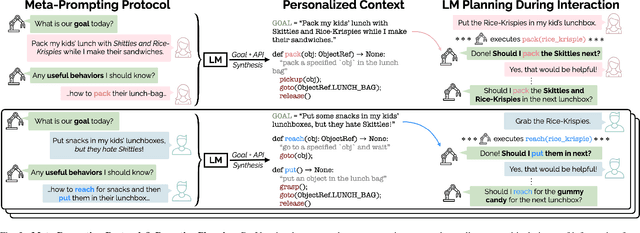

Collaborative robots must quickly adapt to their partner's intent and preferences to proactively identify helpful actions. This is especially true in situated settings where human partners can continually teach robots new high-level behaviors, visual concepts, and physical skills (e.g., through demonstration), growing the robot's capabilities as the human-robot pair work together to accomplish diverse tasks. In this work, we argue that robots should be able to infer their partner's goals from early interactions and use this information to proactively plan behaviors ahead of explicit instructions from the user. Building from the strong commonsense priors and steerability of large language models, we introduce ProVox ("Proactive Voice"), a novel framework that enables robots to efficiently personalize and adapt to individual collaborators. We design a meta-prompting protocol that empowers users to communicate their distinct preferences, intent, and expected robot behaviors ahead of starting a physical interaction. ProVox then uses the personalized prompt to condition a proactive language model task planner that anticipates a user's intent from the current interaction context and robot capabilities to suggest helpful actions; in doing so, we alleviate user burden, minimizing the amount of time partners spend explicitly instructing and supervising the robot. We evaluate ProVox through user studies grounded in household manipulation tasks (e.g., assembling lunch bags) that measure the efficiency of the collaboration, as well as features such as perceived helpfulness, ease of use, and reliability. Our analysis suggests that both meta-prompting and proactivity are critical, resulting in 38.7% faster task completion times and 31.9% less user burden relative to non-active baselines. Supplementary material, code, and videos can be found at https://provox-2025.github.io.
A Study of Perceived Safety for Soft Robotics in Caregiving Tasks
Mar 26, 2025

In this project, we focus on human-robot interaction in caregiving scenarios like bathing, where physical contact is inevitable and necessary for proper task execution because force must be applied to the skin. Using finite element analysis, we designed a 3D-printed gripper combining positive and negative pressure for secure yet compliant handling. Preliminary tests showed it exerted a lower, more uniform pressure profile than a standard rigid gripper. In a user study, participants' trust in robots significantly increased after they experienced a brief bathing demonstration performed by a robotic arm equipped with the soft gripper. These results suggest that soft robotics can enhance perceived safety and acceptance in intimate caregiving scenarios.
Vocal Sandbox: Continual Learning and Adaptation for Situated Human-Robot Collaboration
Nov 04, 2024


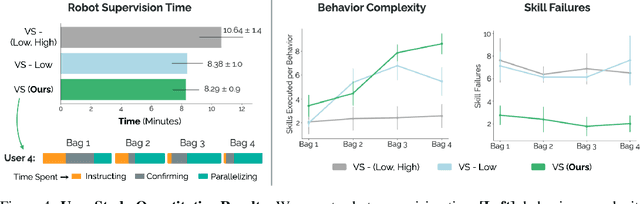
We introduce Vocal Sandbox, a framework for enabling seamless human-robot collaboration in situated environments. Systems in our framework are characterized by their ability to adapt and continually learn at multiple levels of abstraction from diverse teaching modalities such as spoken dialogue, object keypoints, and kinesthetic demonstrations. To enable such adaptation, we design lightweight and interpretable learning algorithms that allow users to build an understanding and co-adapt to a robot's capabilities in real-time, as they teach new behaviors. For example, after demonstrating a new low-level skill for "tracking around" an object, users are provided with trajectory visualizations of the robot's intended motion when asked to track a new object. Similarly, users teach high-level planning behaviors through spoken dialogue, using pretrained language models to synthesize behaviors such as "packing an object away" as compositions of low-level skills $-$ concepts that can be reused and built upon. We evaluate Vocal Sandbox in two settings: collaborative gift bag assembly and LEGO stop-motion animation. In the first setting, we run systematic ablations and user studies with 8 non-expert participants, highlighting the impact of multi-level teaching. Across 23 hours of total robot interaction time, users teach 17 new high-level behaviors with an average of 16 novel low-level skills, requiring 22.1% less active supervision compared to baselines and yielding more complex autonomous performance (+19.7%) with fewer failures (-67.1%). Qualitatively, users strongly prefer Vocal Sandbox systems due to their ease of use (+20.6%) and overall performance (+13.9%). Finally, we pair an experienced system-user with a robot to film a stop-motion animation; over two hours of continuous collaboration, the user teaches progressively more complex motion skills to shoot a 52 second (232 frame) movie.
Stabilize to Act: Learning to Coordinate for Bimanual Manipulation
Sep 03, 2023Key to rich, dexterous manipulation in the real world is the ability to coordinate control across two hands. However, while the promise afforded by bimanual robotic systems is immense, constructing control policies for dual arm autonomous systems brings inherent difficulties. One such difficulty is the high-dimensionality of the bimanual action space, which adds complexity to both model-based and data-driven methods. We counteract this challenge by drawing inspiration from humans to propose a novel role assignment framework: a stabilizing arm holds an object in place to simplify the environment while an acting arm executes the task. We instantiate this framework with BimanUal Dexterity from Stabilization (BUDS), which uses a learned restabilizing classifier to alternate between updating a learned stabilization position to keep the environment unchanged, and accomplishing the task with an acting policy learned from demonstrations. We evaluate BUDS on four bimanual tasks of varying complexities on real-world robots, such as zipping jackets and cutting vegetables. Given only 20 demonstrations, BUDS achieves 76.9% task success across our task suite, and generalizes to out-of-distribution objects within a class with a 52.7% success rate. BUDS is 56.0% more successful than an unstructured baseline that instead learns a BC stabilizing policy due to the precision required of these complex tasks. Supplementary material and videos can be found at https://sites.google.com/view/stabilizetoact .
Learning Bimanual Scooping Policies for Food Acquisition
Nov 26, 2022A robotic feeding system must be able to acquire a variety of foods. Prior bite acquisition works consider single-arm spoon scooping or fork skewering, which do not generalize to foods with complex geometries and deformabilities. For example, when acquiring a group of peas, skewering could smoosh the peas while scooping without a barrier could result in chasing the peas on the plate. In order to acquire foods with such diverse properties, we propose stabilizing food items during scooping using a second arm, for example, by pushing peas against the spoon with a flat surface to prevent dispersion. The added stabilizing arm can lead to new challenges. Critically, this arm should stabilize the food scene without interfering with the acquisition motion, which is especially difficult for easily breakable high-risk food items like tofu. These high-risk foods can break between the pusher and spoon during scooping, which can lead to food waste falling out of the spoon. We propose a general bimanual scooping primitive and an adaptive stabilization strategy that enables successful acquisition of a diverse set of food geometries and physical properties. Our approach, CARBS: Coordinated Acquisition with Reactive Bimanual Scooping, learns to stabilize without impeding task progress by identifying high-risk foods and robustly scooping them using closed-loop visual feedback. We find that CARBS is able to generalize across food shape, size, and deformability and is additionally able to manipulate multiple food items simultaneously. CARBS achieves 87.0% success on scooping rigid foods, which is 25.8% more successful than a single-arm baseline, and reduces food breakage by 16.2% compared to an analytical baseline. Videos can be found at https://sites.google.com/view/bimanualscoop-corl22/home .
In-Mouth Robotic Bite Transfer with Visual and Haptic Sensing
Nov 23, 2022



Assistance during eating is essential for those with severe mobility issues or eating risks. However, dependence on traditional human caregivers is linked to malnutrition, weight loss, and low self-esteem. For those who require eating assistance, a semi-autonomous robotic platform can provide independence and a healthier lifestyle. We demonstrate an essential capability of this platform: safe, comfortable, and effective transfer of a bite-sized food item from a utensil directly to the inside of a person's mouth. Our system uses a force-reactive controller to safely accommodate the user's motions throughout the transfer, allowing full reactivity until bite detection then reducing reactivity in the direction of exit. Additionally, we introduce a novel dexterous wrist-like end effector capable of small, unimposing movements to reduce user discomfort. We conduct a user study with 11 participants covering 8 diverse food categories to evaluate our system end-to-end, and we find that users strongly prefer our method to a wide range of baselines. Appendices and videos are available at our website: https://tinyurl.com/btICRA.
Detecting Damage Building Using Real-time Crowdsourced Images and Transfer Learning
Oct 12, 2021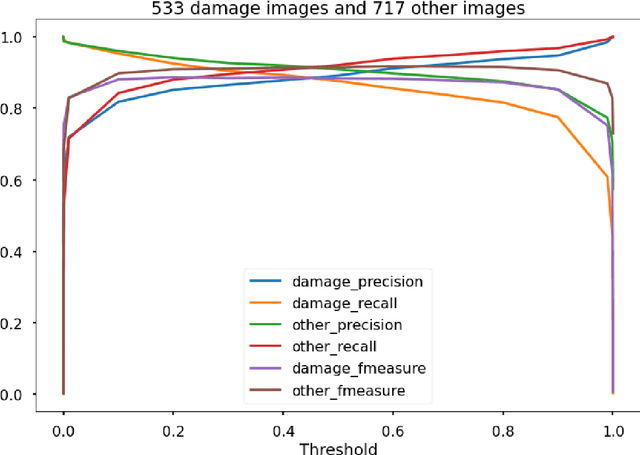


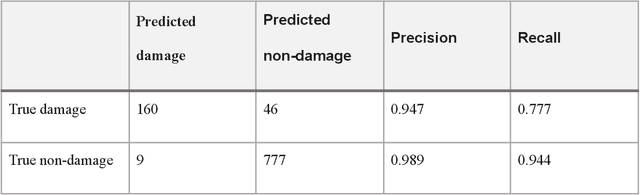
After significant earthquakes, we can see images posted on social media platforms by individuals and media agencies owing to the mass usage of smartphones these days. These images can be utilized to provide information about the shaking damage in the earthquake region both to the public and research community, and potentially to guide rescue work. This paper presents an automated way to extract the damaged building images after earthquakes from social media platforms such as Twitter and thus identify the particular user posts containing such images. Using transfer learning and ~6500 manually labelled images, we trained a deep learning model to recognize images with damaged buildings in the scene. The trained model achieved good performance when tested on newly acquired images of earthquakes at different locations and ran in near real-time on Twitter feed after the 2020 M7.0 earthquake in Turkey. Furthermore, to better understand how the model makes decisions, we also implemented the Grad-CAM method to visualize the important locations on the images that facilitate the decision.
Untangling Dense Non-Planar Knots by Learning Manipulation Features and Recovery Policies
Jun 29, 2021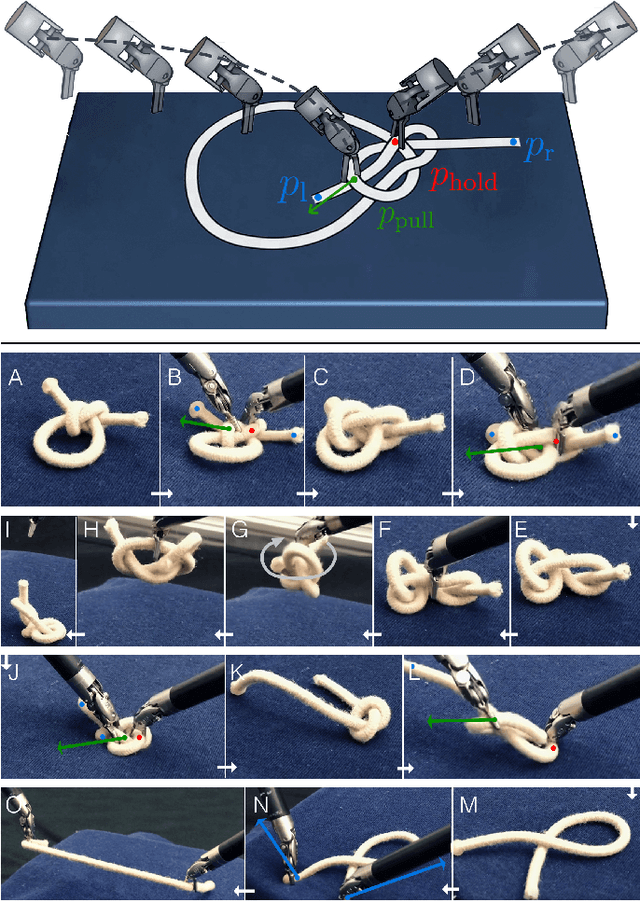
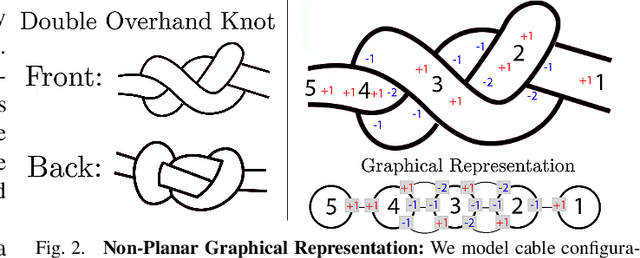
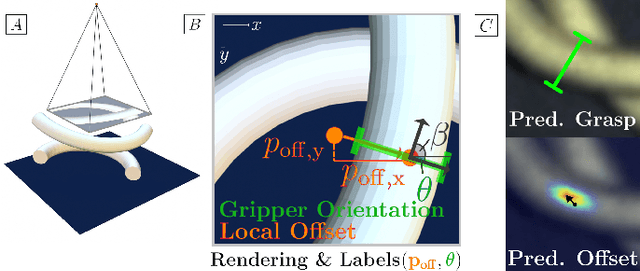
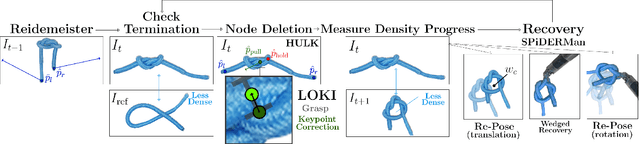
Robot manipulation for untangling 1D deformable structures such as ropes, cables, and wires is challenging due to their infinite dimensional configuration space, complex dynamics, and tendency to self-occlude. Analytical controllers often fail in the presence of dense configurations, due to the difficulty of grasping between adjacent cable segments. We present two algorithms that enhance robust cable untangling, LOKI and SPiDERMan, which operate alongside HULK, a high-level planner from prior work. LOKI uses a learned model of manipulation features to refine a coarse grasp keypoint prediction to a precise, optimized location and orientation, while SPiDERMan uses a learned model to sense task progress and apply recovery actions. We evaluate these algorithms in physical cable untangling experiments with 336 knots and over 1500 actions on real cables using the da Vinci surgical robot. We find that the combination of HULK, LOKI, and SPiDERMan is able to untangle dense overhand, figure-eight, double-overhand, square, bowline, granny, stevedore, and triple-overhand knots. The composition of these methods successfully untangles a cable from a dense initial configuration in 68.3% of 60 physical experiments and achieves 50% higher success rates than baselines from prior work. Supplementary material, code, and videos can be found at https://tinyurl.com/rssuntangling.
Disentangling Dense Multi-Cable Knots
Jun 04, 2021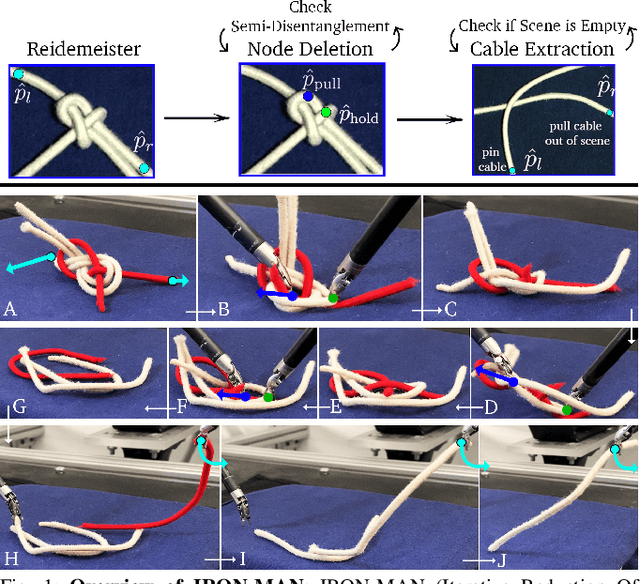
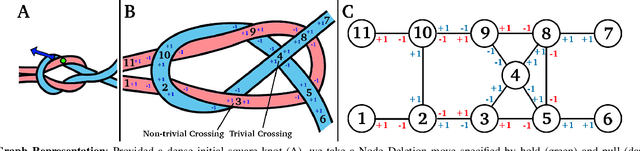
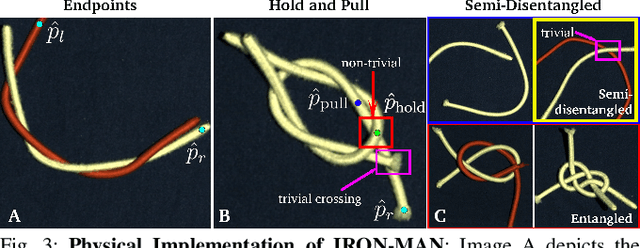

Disentangling two or more cables requires many steps to remove crossings between and within cables. We formalize the problem of disentangling multiple cables and present an algorithm, Iterative Reduction Of Non-planar Multiple cAble kNots (IRON-MAN), that outputs robot actions to remove crossings from multi-cable knotted structures. We instantiate this algorithm with a learned perception system, inspired by prior work in single-cable untying that given an image input, can disentangle two-cable twists, three-cable braids, and knots of two or three cables, such as overhand, square, carrick bend, sheet bend, crown, and fisherman's knots. IRON-MAN keeps track of task-relevant keypoints corresponding to target cable endpoints and crossings and iteratively disentangles the cables by identifying and undoing crossings that are critical to knot structure. Using a da Vinci surgical robot, we experimentally evaluate the effectiveness of IRON-MAN on untangling multi-cable knots of types that appear in the training data, as well as generalizing to novel classes of multi-cable knots. Results suggest that IRON-MAN is effective in disentangling knots involving up to three cables with 80.5% success and generalizing to knot types that are not present during training, with cables of both distinct or identical colors.
Untangling Dense Knots by Learning Task-Relevant Keypoints
Nov 10, 2020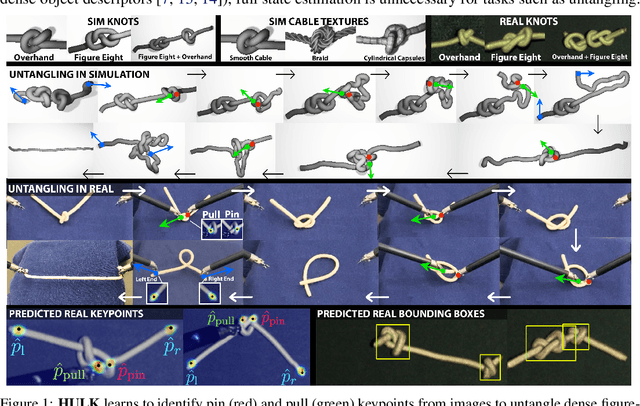
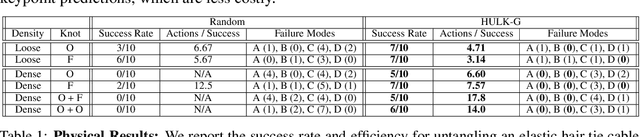
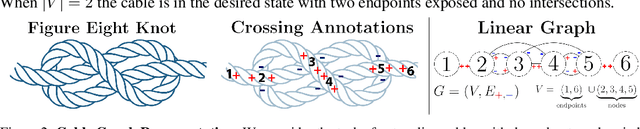

Untangling ropes, wires, and cables is a challenging task for robots due to the high-dimensional configuration space, visual homogeneity, self-occlusions, and complex dynamics. We consider dense (tight) knots that lack space between self-intersections and present an iterative approach that uses learned geometric structure in configurations. We instantiate this into an algorithm, HULK: Hierarchical Untangling from Learned Keypoints, which combines learning-based perception with a geometric planner into a policy that guides a bilateral robot to untangle knots. To evaluate the policy, we perform experiments both in a novel simulation environment modelling cables with varied knot types and textures and in a physical system using the da Vinci surgical robot. We find that HULK is able to untangle cables with dense figure-eight and overhand knots and generalize to varied textures and appearances. We compare two variants of HULK to three baselines and observe that HULK achieves 43.3% higher success rates on a physical system compared to the next best baseline. HULK successfully untangles a cable from a dense initial configuration containing up to two overhand and figure-eight knots in 97.9% of 378 simulation experiments with an average of 12.1 actions per trial. In physical experiments, HULK achieves 61.7% untangling success, averaging 8.48 actions per trial. Supplementary material, code, and videos can be found at https://tinyurl.com/y3a88ycu.
* Conference on Robot Learning (CoRL) 2020 Oral. First two authors contributed equally