 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Damage Building Using Real-time Crowdsourced Images and Transfer Learning
Oct 12, 2021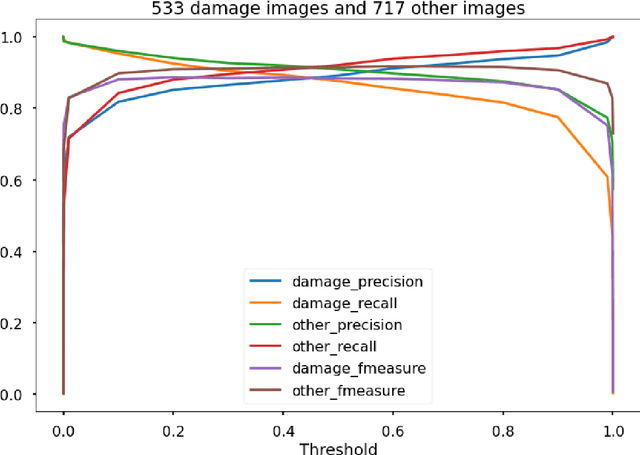


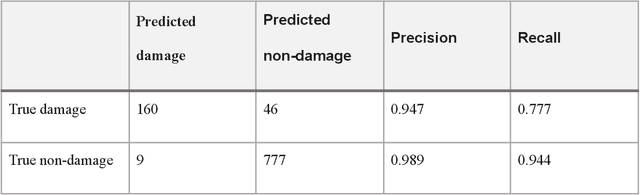
After significant earthquakes, we can see images posted on social media platforms by individuals and media agencies owing to the mass usage of smartphones these days. These images can be utilized to provide information about the shaking damage in the earthquake region both to the public and research community, and potentially to guide rescue work. This paper presents an automated way to extract the damaged building images after earthquakes from social media platforms such as Twitter and thus identify the particular user posts containing such images. Using transfer learning and ~6500 manually labelled images, we trained a deep learning model to recognize images with damaged buildings in the scene. The trained model achieved good performance when tested on newly acquired images of earthquakes at different locations and ran in near real-time on Twitter feed after the 2020 M7.0 earthquake in Turkey. Furthermore, to better understand how the model makes decisions, we also implemented the Grad-CAM method to visualize the important locations on the images that facilitate the decision.
Enhance word representation for out-of-vocabulary on Ubuntu dialogue corpus
May 07, 2018
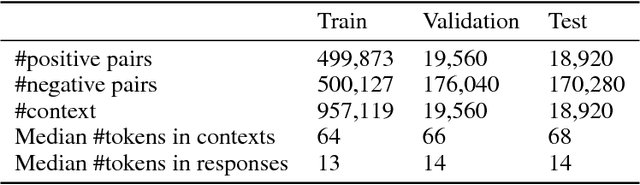
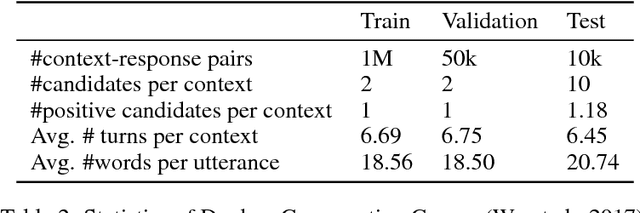
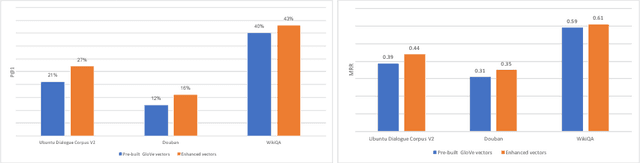
Ubuntu dialogue corpus is the largest public available dialogue corpus to make it feasible to build end-to-end deep neural network models directly from the conversation data. One challenge of Ubuntu dialogue corpus is the large number of out-of-vocabulary words. In this paper we proposed a method which combines the general pre-trained word embedding vectors with those generated on the task-specific training set to address this issue. We integrated character embedding into Chen et al's Enhanced LSTM method (ESIM) and used it to evaluate the effectiveness of our proposed method. For the task of next utterance selection, the proposed method has demonstrated a significant performance improvement against original ESIM and the new model has achieved state-of-the-art results on both Ubuntu dialogue corpus and Douban conversation corpus. In addition, we investigated the performance impact of end-of-utterance and end-of-turn token tags.
Online optimization and regret guarantees for non-additive long-term constraints
Jun 08, 2016



We consider online optimization in the 1-lookahead setting, where the objective does not decompose additively over the rounds of the online game. The resulting formulation enables us to deal with non-stationary and/or long-term constraints , which arise, for example, in online display advertising problems. We propose an on-line primal-dual algorithm for which we obtain dynamic cumulative regret guarantees. They depend on the convexity and the smoothness of the non-additive penalty, as well as terms capturing the smoothness with which the residuals of the non-stationary and long-term constraints vary over the rounds. We conduct experiments on synthetic data to illustrate the benefits of the non-additive penalty and show vanishing regret convergence on live traffic data collected by a display advertising platform in production.
Adaptive Algorithms for Online Convex Optimization with Long-term Constraints
Dec 23, 2015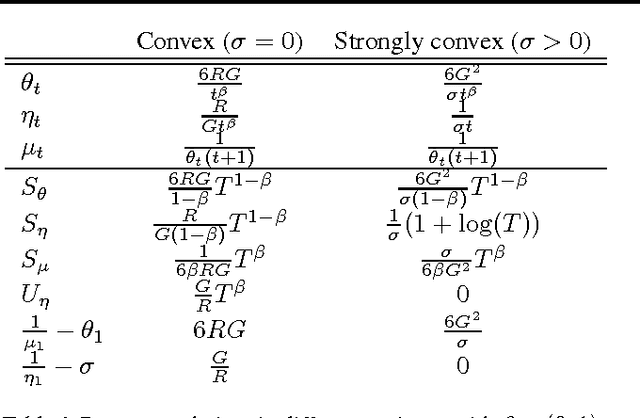
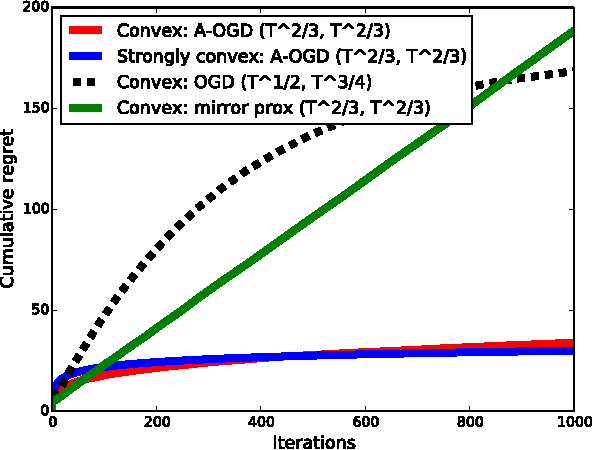
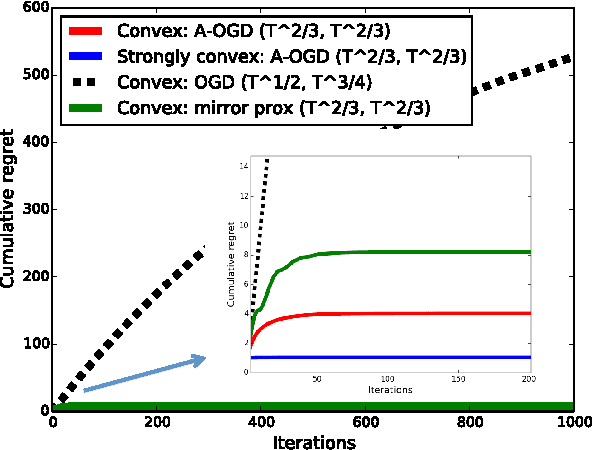
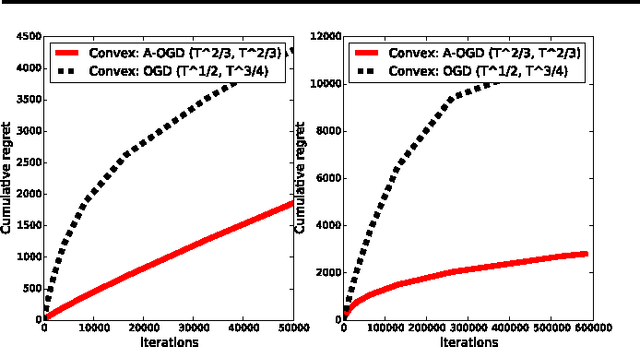
We present an adaptive online gradient descent algorithm to solve online convex optimization problems with long-term constraints , which are constraints that need to be satisfied when accumulated over a finite number of rounds T , but can be violated in intermediate rounds. For some user-defined trade-off parameter $\beta$ $\in$ (0, 1), the proposed algorithm achieves cumulative regret bounds of O(T^max{$\beta$,1--$\beta$}) and O(T^(1--$\beta$/2)) for the loss and the constraint violations respectively. Our results hold for convex losses and can handle arbitrary convex constraints without requiring knowledge of the number of rounds in advance. Our contributions improve over the best known cumulative regret bounds by Mahdavi, et al. (2012) that are respectively O(T^1/2) and O(T^3/4) for general convex domains, and respectively O(T^2/3) and O(T^2/3) when further restricting to polyhedral domains. We supplement the analysis with experiments validating the performance of our algorithm in practice.
Cumulative distribution networks and the derivative-sum-product algorithm
Jun 13, 2012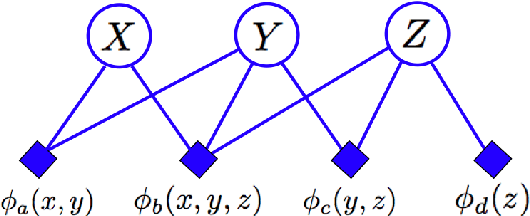

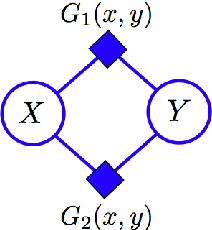

We introduce a new type of graphical model called a "cumulative distribution network" (CDN), which expresses a joint cumulative distribution as a product of local functions. Each local function can be viewed as providing evidence about possible orderings, or rankings, of variables. Interestingly, we find that the conditional independence properties of CDNs are quite different from other graphical models. We also describe a messagepassing algorithm that efficiently computes conditional cumulative distributions. Due to the unique independence properties of the CDN, these messages do not in general have a one-to-one correspondence with messages exchanged in standard algorithms, such as belief propagation. We demonstrate the application of CDNs for structured ranking learning using a previously-studied multi-player gaming dataset.