 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline optimization and regret guarantees for non-additive long-term constraints
Jun 08, 2016



We consider online optimization in the 1-lookahead setting, where the objective does not decompose additively over the rounds of the online game. The resulting formulation enables us to deal with non-stationary and/or long-term constraints , which arise, for example, in online display advertising problems. We propose an on-line primal-dual algorithm for which we obtain dynamic cumulative regret guarantees. They depend on the convexity and the smoothness of the non-additive penalty, as well as terms capturing the smoothness with which the residuals of the non-stationary and long-term constraints vary over the rounds. We conduct experiments on synthetic data to illustrate the benefits of the non-additive penalty and show vanishing regret convergence on live traffic data collected by a display advertising platform in production.
Importance Sampling for Minibatches
Feb 06, 2016

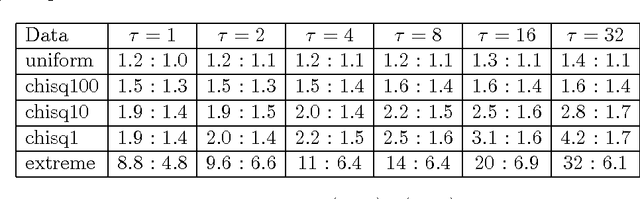

Minibatching is a very well studied and highly popular technique in supervised learning, used by practitioners due to its ability to accelerate training through better utilization of parallel processing power and reduction of stochastic variance. Another popular technique is importance sampling -- a strategy for preferential sampling of more important examples also capable of accelerating the training process. However, despite considerable effort by the community in these areas, and due to the inherent technical difficulty of the problem, there is no existing work combining the power of importance sampling with the strength of minibatching. In this paper we propose the first {\em importance sampling for minibatches} and give simple and rigorous complexity analysis of its performance. We illustrate on synthetic problems that for training data of certain properties, our sampling can lead to several orders of magnitude improvement in training time. We then test the new sampling on several popular datasets, and show that the improvement can reach an order of magnitude.
Primal Method for ERM with Flexible Mini-batching Schemes and Non-convex Losses
Jun 07, 2015


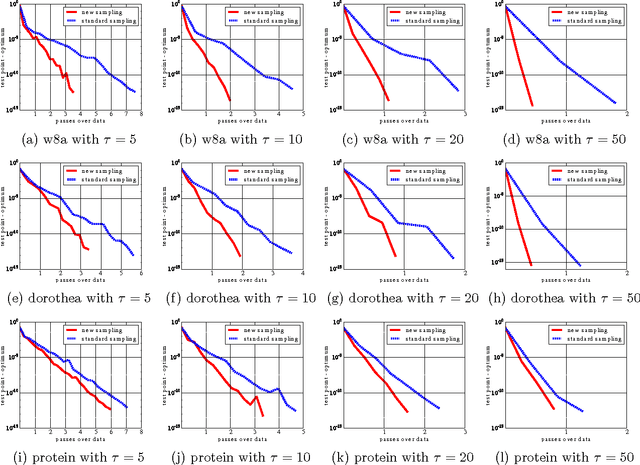
In this work we develop a new algorithm for regularized empirical risk minimization. Our method extends recent techniques of Shalev-Shwartz [02/2015], which enable a dual-free analysis of SDCA, to arbitrary mini-batching schemes. Moreover, our method is able to better utilize the information in the data defining the ERM problem. For convex loss functions, our complexity results match those of QUARTZ, which is a primal-dual method also allowing for arbitrary mini-batching schemes. The advantage of a dual-free analysis comes from the fact that it guarantees convergence even for non-convex loss functions, as long as the average loss is convex. We illustrate through experiments the utility of being able to design arbitrary mini-batching schemes.
Stochastic Dual Coordinate Ascent with Adaptive Probabilities
Feb 27, 2015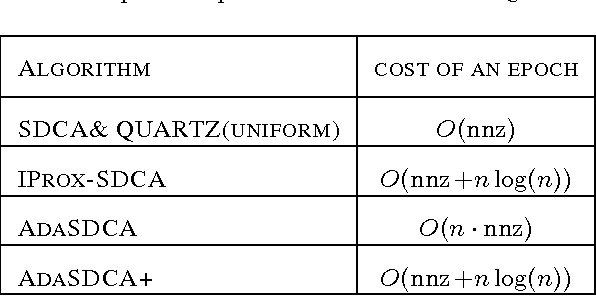
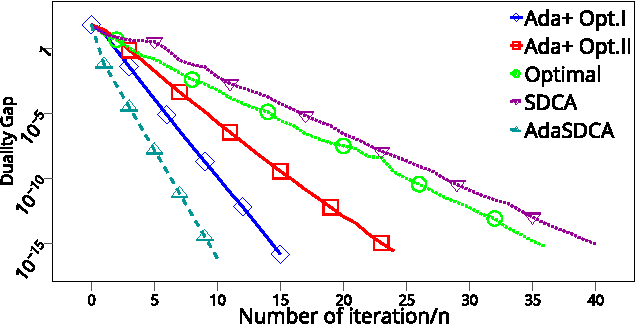
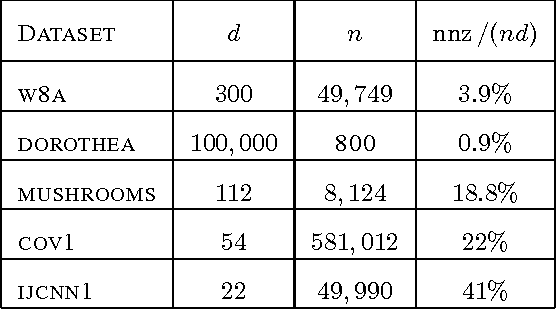
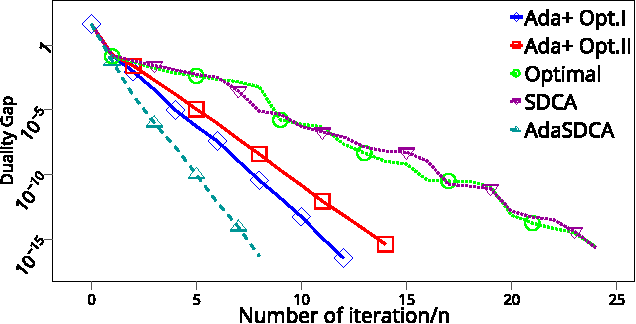
This paper introduces AdaSDCA: an adaptive variant of stochastic dual coordinate ascent (SDCA) for solving the regularized empirical risk minimization problems. Our modification consists in allowing the method adaptively change the probability distribution over the dual variables throughout the iterative process. AdaSDCA achieves provably better complexity bound than SDCA with the best fixed probability distribution, known as importance sampling. However, it is of a theoretical character as it is expensive to implement. We also propose AdaSDCA+: a practical variant which in our experiments outperforms existing non-adaptive methods.