 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperparameter Optimization in Machine Learning
Oct 30, 2024



Hyperparameters are configuration variables controlling the behavior of machine learning algorithms. They are ubiquitous in machine learning and artificial intelligence and the choice of their values determine the effectiveness of systems based on these technologies. Manual hyperparameter search is often unsatisfactory and becomes unfeasible when the number of hyperparameters is large. Automating the search is an important step towards automating machine learning, freeing researchers and practitioners alike from the burden of finding a good set of hyperparameters by trial and error. In this survey, we present a unified treatment of hyperparameter optimization, providing the reader with examples and insights into the state-of-the-art. We cover the main families of techniques to automate hyperparameter search, often referred to as hyperparameter optimization or tuning, including random and quasi-random search, bandit-, model- and gradient- based approaches. We further discuss extensions, including online, constrained, and multi-objective formulations, touch upon connections with other fields such as meta-learning and neural architecture search, and conclude with open questions and future research directions.
Explaining Probabilistic Models with Distributional Values
Feb 15, 2024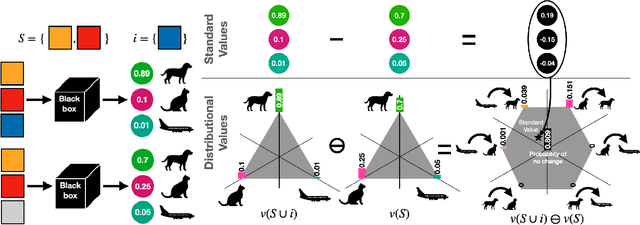

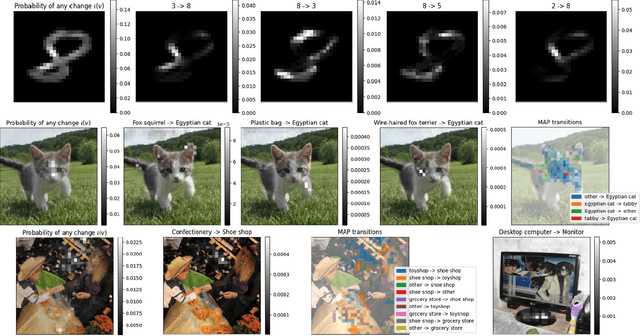
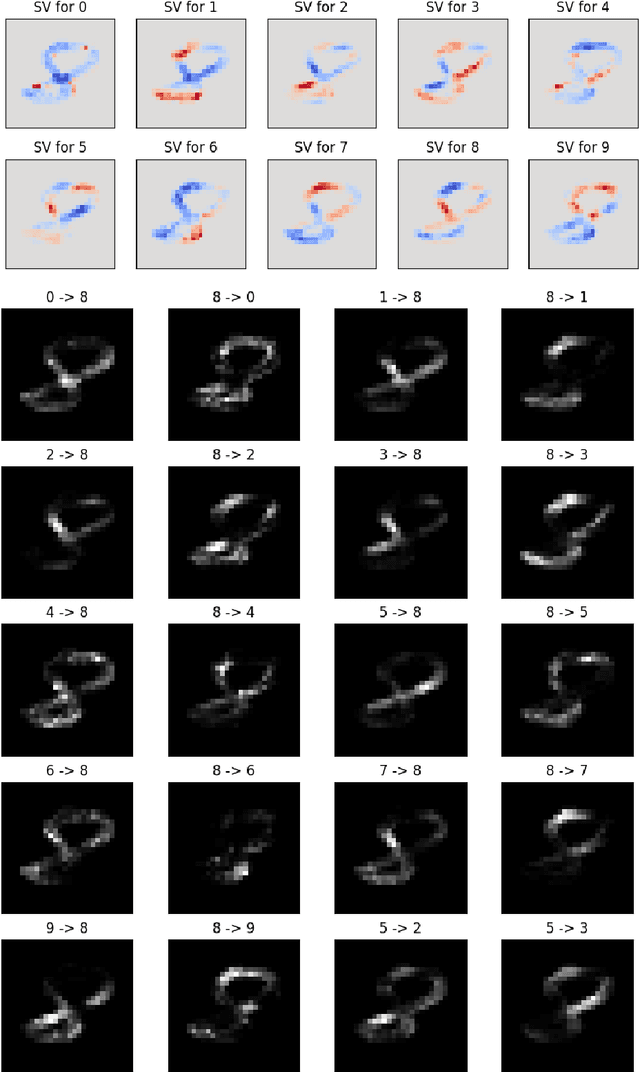
A large branch of explainable machine learning is grounded in cooperative game theory. However, research indicates that game-theoretic explanations may mislead or be hard to interpret. We argue that often there is a critical mismatch between what one wishes to explain (e.g. the output of a classifier) and what current methods such as SHAP explain (e.g. the scalar probability of a class). This paper addresses such gap for probabilistic models by generalising cooperative games and value operators. We introduce the distributional values, random variables that track changes in the model output (e.g. flipping of the predicted class) and derive their analytic expressions for games with Gaussian, Bernoulli and Categorical payoffs. We further establish several characterising properties, and show that our framework provides fine-grained and insightful explanations with case studies on vision and language models.
Geographical Erasure in Language Generation
Oct 23, 2023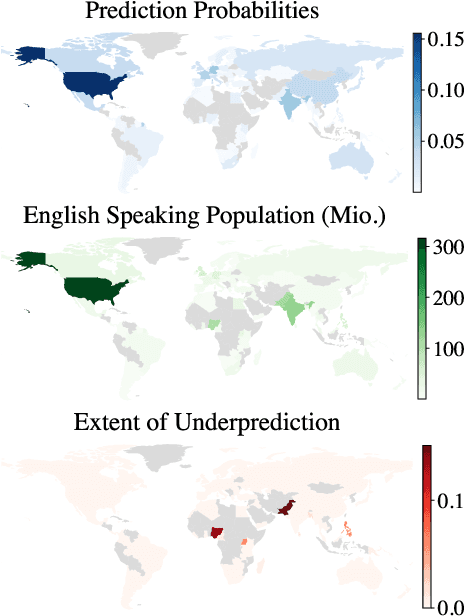

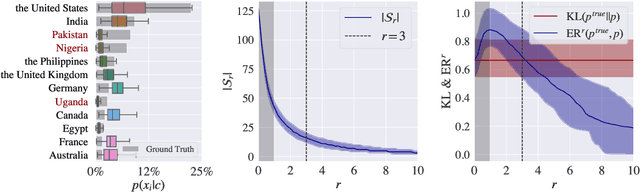
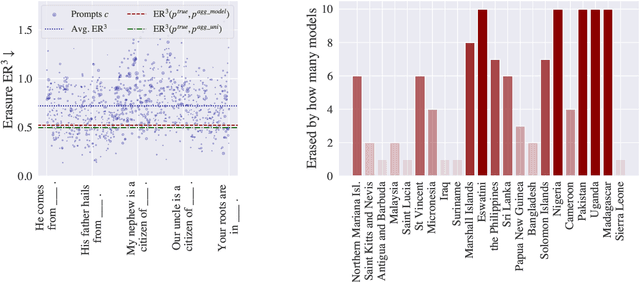
Large language models (LLMs) encode vast amounts of world knowledge. However, since these models are trained on large swaths of internet data, they are at risk of inordinately capturing information about dominant groups. This imbalance can propagate into generated language. In this work, we study and operationalise a form of geographical erasure, wherein language models underpredict certain countries. We demonstrate consistent instances of erasure across a range of LLMs. We discover that erasure strongly correlates with low frequencies of country mentions in the training corpus. Lastly, we mitigate erasure by finetuning using a custom objective.
PASHA: Efficient HPO with Progressive Resource Allocation
Jul 14, 2022
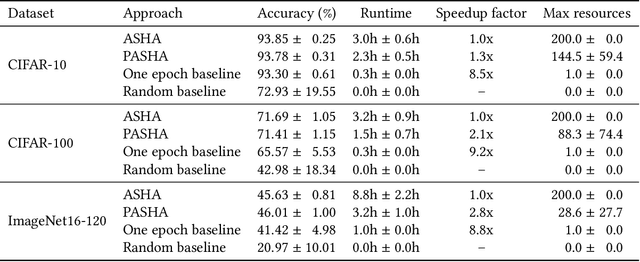
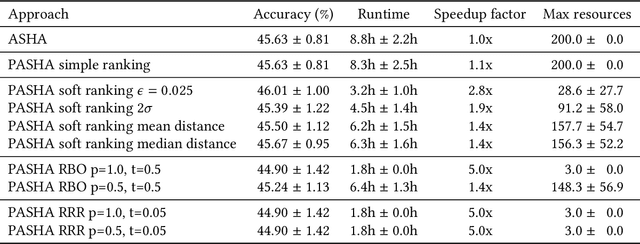
Hyperparameter optimization (HPO) and neural architecture search (NAS) are methods of choice to obtain the best-in-class machine learning models, but in practice they can be costly to run. When models are trained on large datasets, tuning them with HPO or NAS rapidly becomes prohibitively expensive for practitioners, even when efficient multi-fidelity methods are employed. We propose an approach to tackle the challenge of tuning machine learning models trained on large datasets with limited computational resources. Our approach, named PASHA, is able to dynamically allocate maximum resources for the tuning procedure depending on the need. The experimental comparison shows that PASHA identifies well-performing hyperparameter configurations and architectures while consuming significantly fewer computational resources than solutions like ASHA.
Gradient-Matching Coresets for Rehearsal-Based Continual Learning
Mar 28, 2022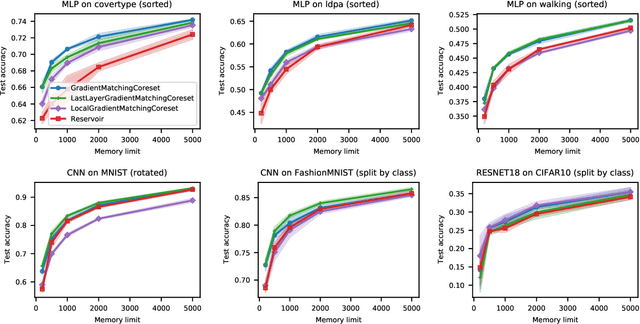
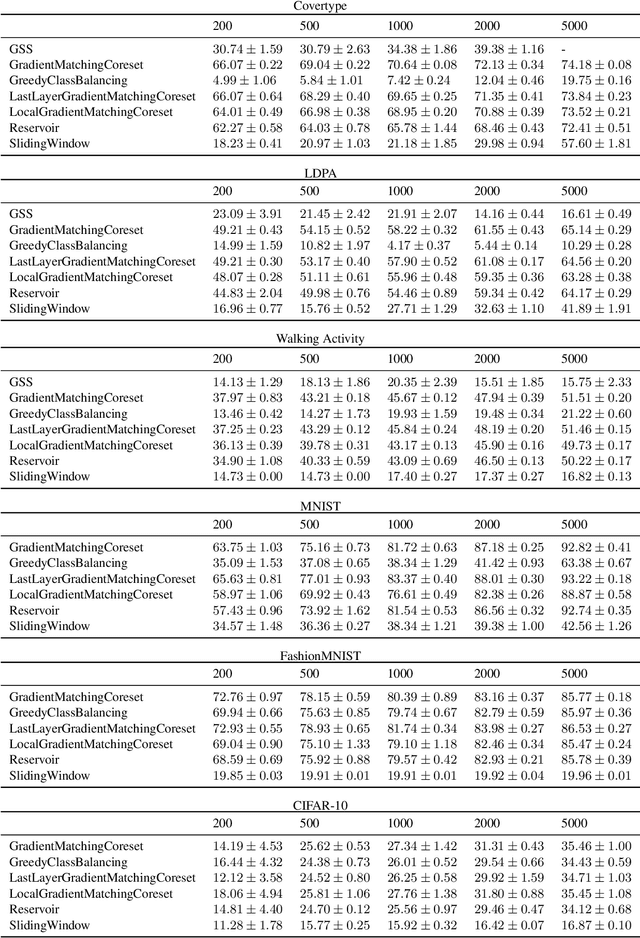
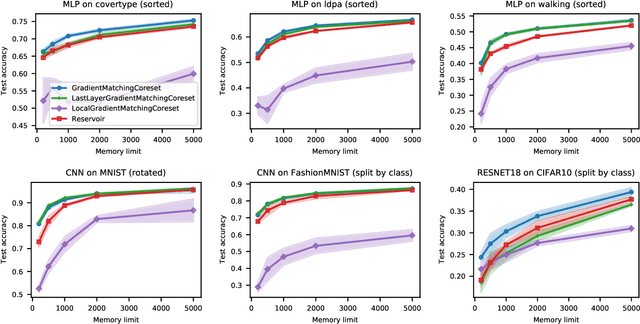
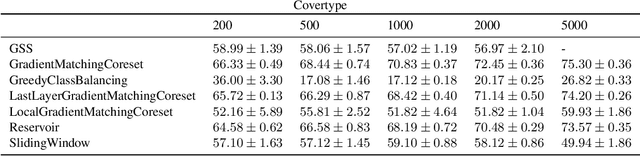
The goal of continual learning (CL) is to efficiently update a machine learning model with new data without forgetting previously-learned knowledge. Most widely-used CL methods rely on a rehearsal memory of data points to be reused while training on new data. Curating such a rehearsal memory to maintain a small, informative subset of all the data seen so far is crucial to the success of these methods. We devise a coreset selection method for rehearsal-based continual learning. Our method is based on the idea of gradient matching: The gradients induced by the coreset should match, as closely as possible, those induced by the original training dataset. Inspired by the neural tangent kernel theory, we perform this gradient matching across the model's initialization distribution, allowing us to extract a coreset without having to train the model first. We evaluate the method on a wide range of continual learning scenarios and demonstrate that it improves the performance of rehearsal-based CL methods compared to competing memory management strategies such as reservoir sampling.
More Than Words: Towards Better Quality Interpretations of Text Classifiers
Dec 23, 2021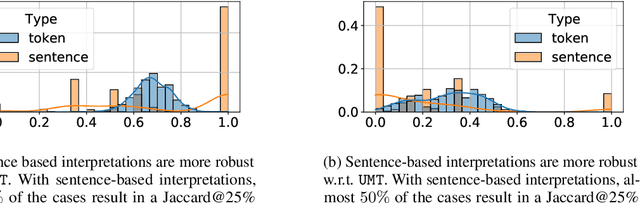



The large size and complex decision mechanisms of state-of-the-art text classifiers make it difficult for humans to understand their predictions, leading to a potential lack of trust by the users. These issues have led to the adoption of methods like SHAP and Integrated Gradients to explain classification decisions by assigning importance scores to input tokens. However, prior work, using different randomization tests, has shown that interpretations generated by these methods may not be robust. For instance, models making the same predictions on the test set may still lead to different feature importance rankings. In order to address the lack of robustness of token-based interpretability, we explore explanations at higher semantic levels like sentences. We use computational metrics and human subject studies to compare the quality of sentence-based interpretations against token-based ones. Our experiments show that higher-level feature attributions offer several advantages: 1) they are more robust as measured by the randomization tests, 2) they lead to lower variability when using approximation-based methods like SHAP, and 3) they are more intelligible to humans in situations where the linguistic coherence resides at a higher granularity level. Based on these findings, we show that token-based interpretability, while being a convenient first choice given the input interfaces of the ML models, is not the most effective one in all situations.
Gradient-matching coresets for continual learning
Dec 09, 2021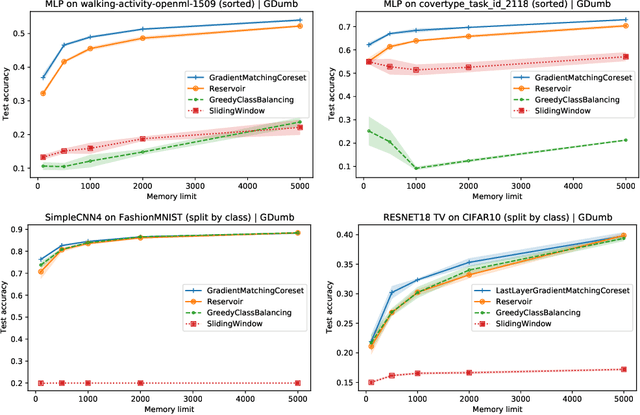
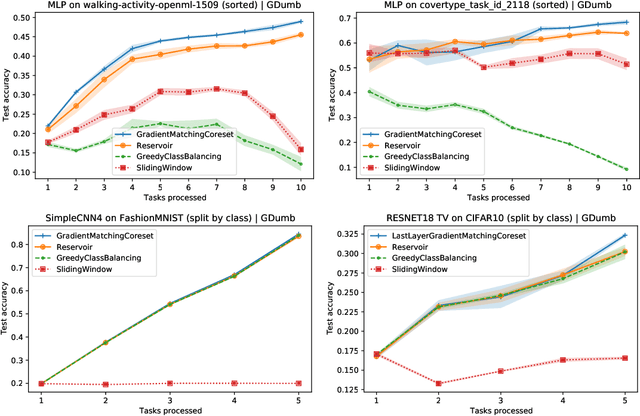
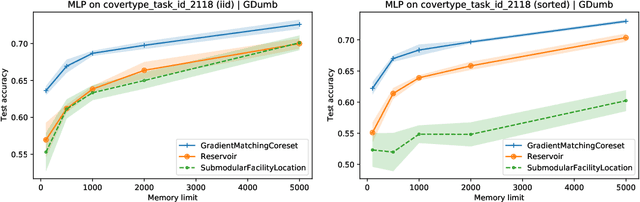
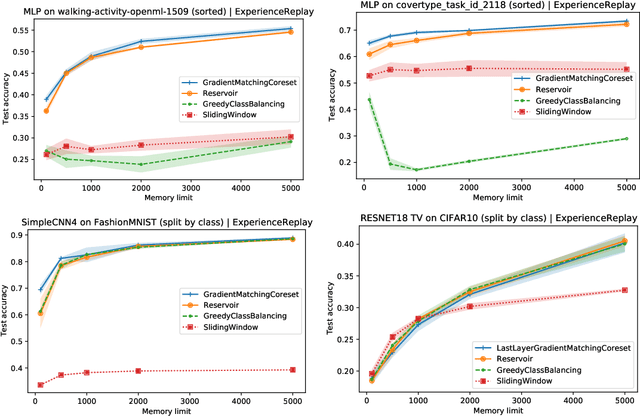
We devise a coreset selection method based on the idea of gradient matching: The gradients induced by the coreset should match, as closely as possible, those induced by the original training dataset. We evaluate the method in the context of continual learning, where it can be used to curate a rehearsal memory. Our method performs strong competitors such as reservoir sampling across a range of memory sizes.
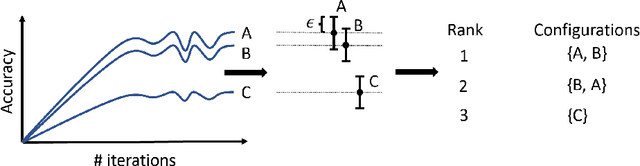
Multi-objective Asynchronous Successive Halving
Jun 23, 2021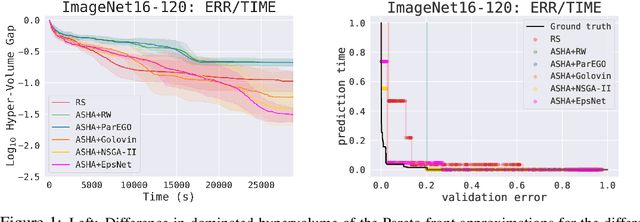

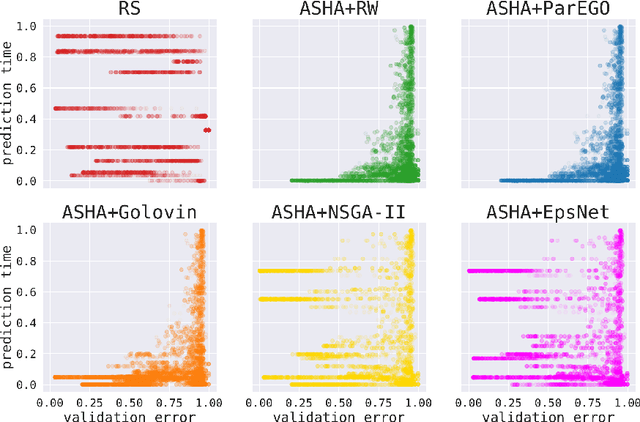

Hyperparameter optimization (HPO) is increasingly used to automatically tune the predictive performance (e.g., accuracy) of machine learning models. However, in a plethora of real-world applications, accuracy is only one of the multiple -- often conflicting -- performance criteria, necessitating the adoption of a multi-objective (MO) perspective. While the literature on MO optimization is rich, few prior studies have focused on HPO. In this paper, we propose algorithms that extend asynchronous successive halving (ASHA) to the MO setting. Considering multiple evaluation metrics, we assess the performance of these methods on three real world tasks: (i) Neural architecture search, (ii) algorithmic fairness and (iii) language model optimization. Our empirical analysis shows that MO ASHA enables to perform MO HPO at scale. Further, we observe that that taking the entire Pareto front into account for candidate selection consistently outperforms multi-fidelity HPO based on MO scalarization in terms of wall-clock time. Our algorithms (to be open-sourced) establish new baselines for future research in the area.
On the Lack of Robust Interpretability of Neural Text Classifiers
Jun 08, 2021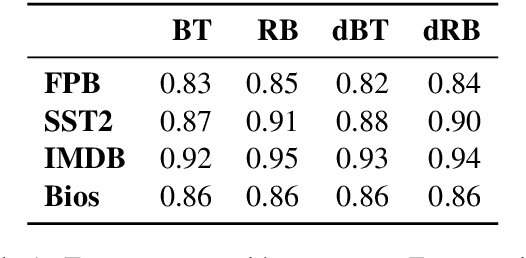
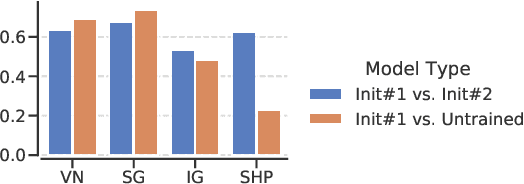


With the ever-increasing complexity of neural language models, practitioners have turned to methods for understanding the predictions of these models. One of the most well-adopted approaches for model interpretability is feature-based interpretability, i.e., ranking the features in terms of their impact on model predictions. Several prior studies have focused on assessing the fidelity of feature-based interpretability methods, i.e., measuring the impact of dropping the top-ranked features on the model output. However, relatively little work has been conducted on quantifying the robustness of interpretations. In this work, we assess the robustness of interpretations of neural text classifiers, specifically, those based on pretrained Transformer encoders, using two randomization tests. The first compares the interpretations of two models that are identical except for their initializations. The second measures whether the interpretations differ between a model with trained parameters and a model with random parameters. Both tests show surprising deviations from expected behavior, raising questions about the extent of insights that practitioners may draw from interpretations.
A resource-efficient method for repeated HPO and NAS problems
Mar 30, 2021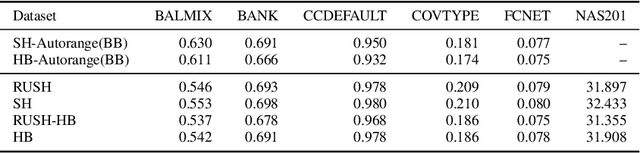
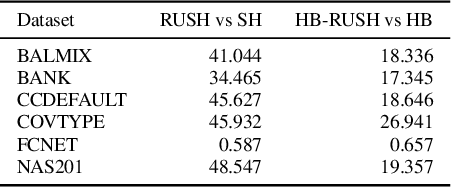
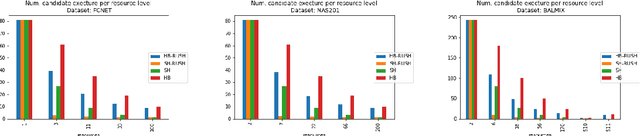
In this work we consider the problem of repeated hyperparameter and neural architecture search (HNAS). We propose an extension of Successive Halving that is able to leverage information gained in previous HNAS problems with the goal of saving computational resources. We empirically demonstrate that our solution is able to drastically decrease costs while maintaining accuracy and being robust to negative transfer. Our method is significantly simpler than competing transfer learning approaches, setting a new baseline for transfer learning in HNAS.