 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Than Words: Towards Better Quality Interpretations of Text Classifiers
Paper and Code
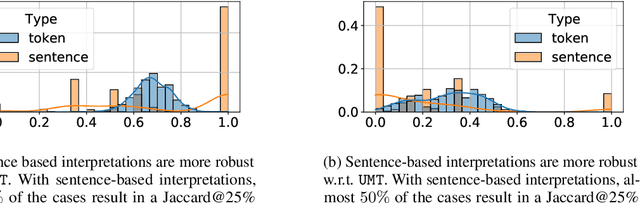



The large size and complex decision mechanisms of state-of-the-art text classifiers make it difficult for humans to understand their predictions, leading to a potential lack of trust by the users. These issues have led to the adoption of methods like SHAP and Integrated Gradients to explain classification decisions by assigning importance scores to input tokens. However, prior work, using different randomization tests, has shown that interpretations generated by these methods may not be robust. For instance, models making the same predictions on the test set may still lead to different feature importance rankings. In order to address the lack of robustness of token-based interpretability, we explore explanations at higher semantic levels like sentences. We use computational metrics and human subject studies to compare the quality of sentence-based interpretations against token-based ones. Our experiments show that higher-level feature attributions offer several advantages: 1) they are more robust as measured by the randomization tests, 2) they lead to lower variability when using approximation-based methods like SHAP, and 3) they are more intelligible to humans in situations where the linguistic coherence resides at a higher granularity level. Based on these findings, we show that token-based interpretability, while being a convenient first choice given the input interfaces of the ML models, is not the most effective one in all situations.