 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperparameter Optimization in Machine Learning
Oct 30, 2024



Hyperparameters are configuration variables controlling the behavior of machine learning algorithms. They are ubiquitous in machine learning and artificial intelligence and the choice of their values determine the effectiveness of systems based on these technologies. Manual hyperparameter search is often unsatisfactory and becomes unfeasible when the number of hyperparameters is large. Automating the search is an important step towards automating machine learning, freeing researchers and practitioners alike from the burden of finding a good set of hyperparameters by trial and error. In this survey, we present a unified treatment of hyperparameter optimization, providing the reader with examples and insights into the state-of-the-art. We cover the main families of techniques to automate hyperparameter search, often referred to as hyperparameter optimization or tuning, including random and quasi-random search, bandit-, model- and gradient- based approaches. We further discuss extensions, including online, constrained, and multi-objective formulations, touch upon connections with other fields such as meta-learning and neural architecture search, and conclude with open questions and future research directions.
Evaluating Large Language Models with fmeval
Jul 15, 2024



fmeval is an open source library to evaluate large language models (LLMs) in a range of tasks. It helps practitioners evaluate their model for task performance and along multiple responsible AI dimensions. This paper presents the library and exposes its underlying design principles: simplicity, coverage, extensibility and performance. We then present how these were implemented in the scientific and engineering choices taken when developing fmeval. A case study demonstrates a typical use case for the library: picking a suitable model for a question answering task. We close by discussing limitations and further work in the development of the library. fmeval can be found at https://github.com/aws/fmeval.
Explaining Probabilistic Models with Distributional Values
Feb 15, 2024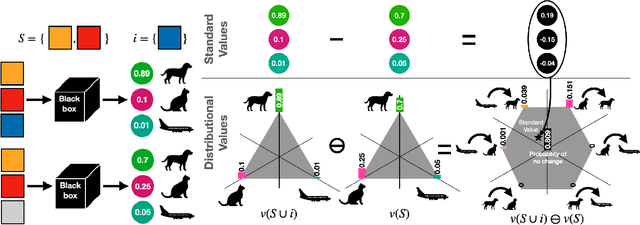

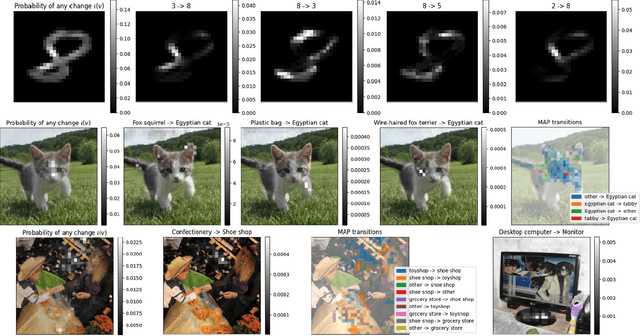
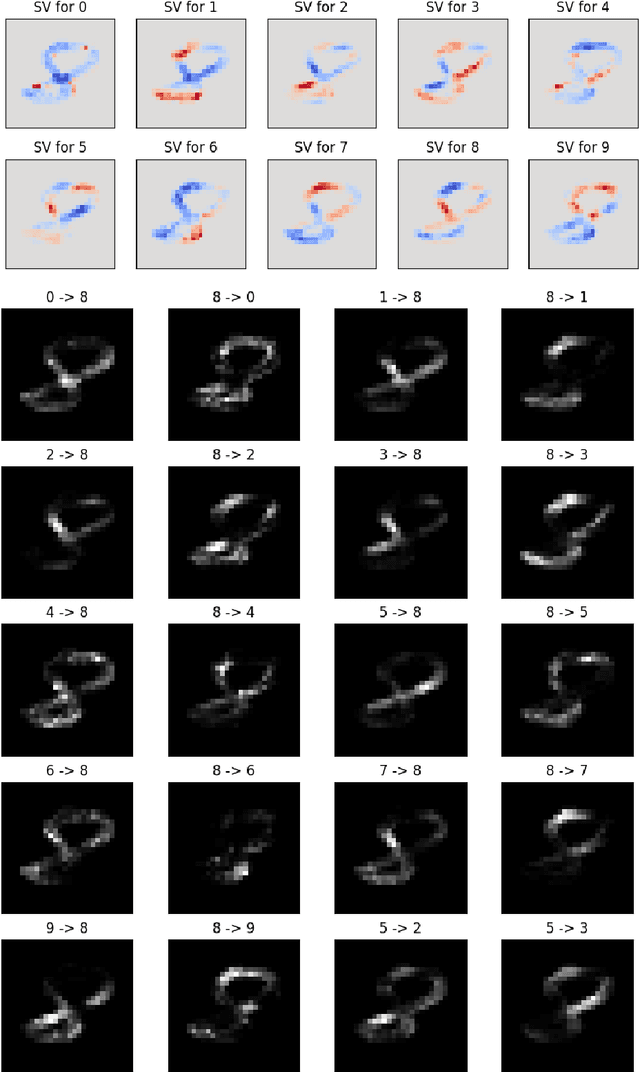
A large branch of explainable machine learning is grounded in cooperative game theory. However, research indicates that game-theoretic explanations may mislead or be hard to interpret. We argue that often there is a critical mismatch between what one wishes to explain (e.g. the output of a classifier) and what current methods such as SHAP explain (e.g. the scalar probability of a class). This paper addresses such gap for probabilistic models by generalising cooperative games and value operators. We introduce the distributional values, random variables that track changes in the model output (e.g. flipping of the predicted class) and derive their analytic expressions for games with Gaussian, Bernoulli and Categorical payoffs. We further establish several characterising properties, and show that our framework provides fine-grained and insightful explanations with case studies on vision and language models.
Geographical Erasure in Language Generation
Oct 23, 2023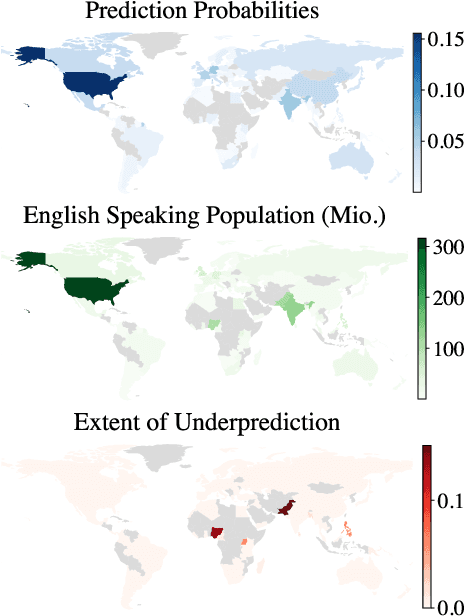

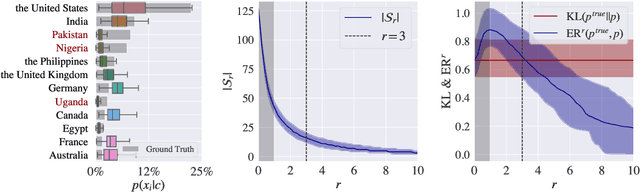
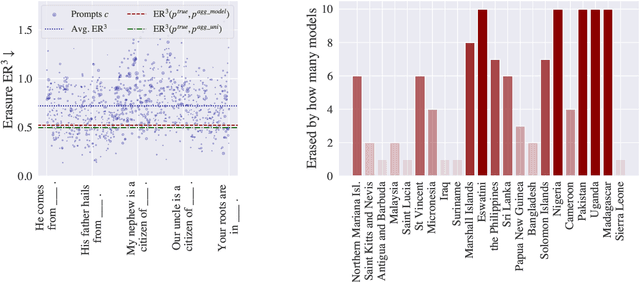
Large language models (LLMs) encode vast amounts of world knowledge. However, since these models are trained on large swaths of internet data, they are at risk of inordinately capturing information about dominant groups. This imbalance can propagate into generated language. In this work, we study and operationalise a form of geographical erasure, wherein language models underpredict certain countries. We demonstrate consistent instances of erasure across a range of LLMs. We discover that erasure strongly correlates with low frequencies of country mentions in the training corpus. Lastly, we mitigate erasure by finetuning using a custom objective.
Efficient fair PCA for fair representation learning
Feb 26, 2023We revisit the problem of fair principal component analysis (PCA), where the goal is to learn the best low-rank linear approximation of the data that obfuscates demographic information. We propose a conceptually simple approach that allows for an analytic solution similar to standard PCA and can be kernelized. Our methods have the same complexity as standard PCA, or kernel PCA, and run much faster than existing methods for fair PCA based on semidefinite programming or manifold optimization, while achieving similar results.
Fortuna: A Library for Uncertainty Quantification in Deep Learning
Feb 08, 2023We present Fortuna, an open-source library for uncertainty quantification in deep learning. Fortuna supports a range of calibration techniques, such as conformal prediction that can be applied to any trained neural network to generate reliable uncertainty estimates, and scalable Bayesian inference methods that can be applied to Flax-based deep neural networks trained from scratch for improved uncertainty quantification and accuracy. By providing a coherent framework for advanced uncertainty quantification methods, Fortuna simplifies the process of benchmarking and helps practitioners build robust AI systems.
Diverse Counterfactual Explanations for Anomaly Detection in Time Series
Mar 21, 2022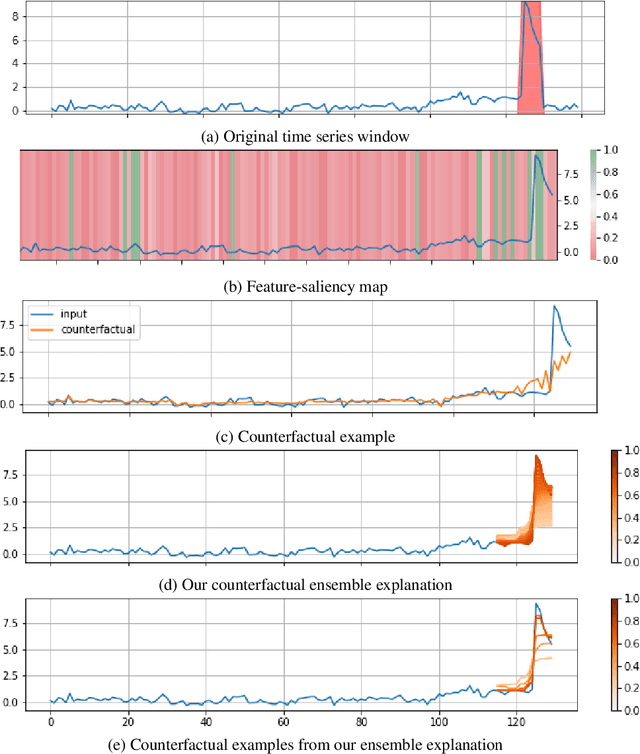

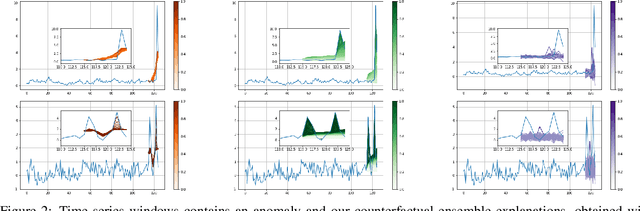
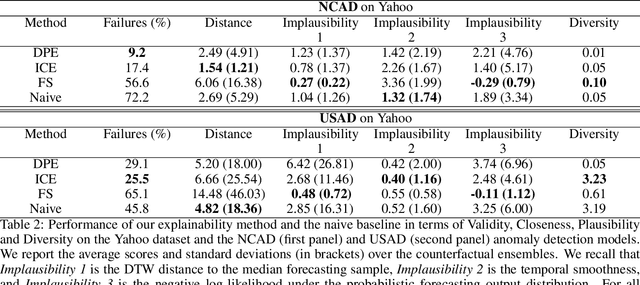
Data-driven methods that detect anomalies in times series data are ubiquitous in practice, but they are in general unable to provide helpful explanations for the predictions they make. In this work we propose a model-agnostic algorithm that generates counterfactual ensemble explanations for time series anomaly detection models. Our method generates a set of diverse counterfactual examples, i.e, multiple perturbed versions of the original time series that are not considered anomalous by the detection model. Since the magnitude of the perturbations is limited, these counterfactuals represent an ensemble of inputs similar to the original time series that the model would deem normal. Our algorithm is applicable to any differentiable anomaly detection model. We investigate the value of our method on univariate and multivariate real-world datasets and two deep-learning-based anomaly detection models, under several explainability criteria previously proposed in other data domains such as Validity, Plausibility, Closeness and Diversity. We show that our algorithm can produce ensembles of counterfactual examples that satisfy these criteria and thanks to a novel type of visualisation, can convey a richer interpretation of a model's internal mechanism than existing methods. Moreover, we design a sparse variant of our method to improve the interpretability of counterfactual explanations for high-dimensional time series anomalies. In this setting, our explanation is localised on only a few dimensions and can therefore be communicated more efficiently to the model's user.
More Than Words: Towards Better Quality Interpretations of Text Classifiers
Dec 23, 2021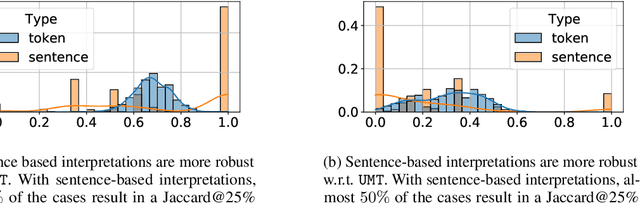



The large size and complex decision mechanisms of state-of-the-art text classifiers make it difficult for humans to understand their predictions, leading to a potential lack of trust by the users. These issues have led to the adoption of methods like SHAP and Integrated Gradients to explain classification decisions by assigning importance scores to input tokens. However, prior work, using different randomization tests, has shown that interpretations generated by these methods may not be robust. For instance, models making the same predictions on the test set may still lead to different feature importance rankings. In order to address the lack of robustness of token-based interpretability, we explore explanations at higher semantic levels like sentences. We use computational metrics and human subject studies to compare the quality of sentence-based interpretations against token-based ones. Our experiments show that higher-level feature attributions offer several advantages: 1) they are more robust as measured by the randomization tests, 2) they lead to lower variability when using approximation-based methods like SHAP, and 3) they are more intelligible to humans in situations where the linguistic coherence resides at a higher granularity level. Based on these findings, we show that token-based interpretability, while being a convenient first choice given the input interfaces of the ML models, is not the most effective one in all situations.
Amazon SageMaker Model Monitor: A System for Real-Time Insights into Deployed Machine Learning Models
Dec 13, 2021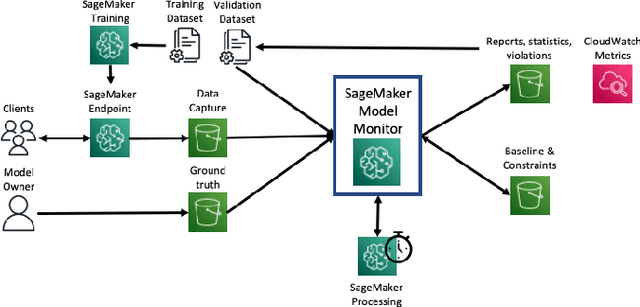
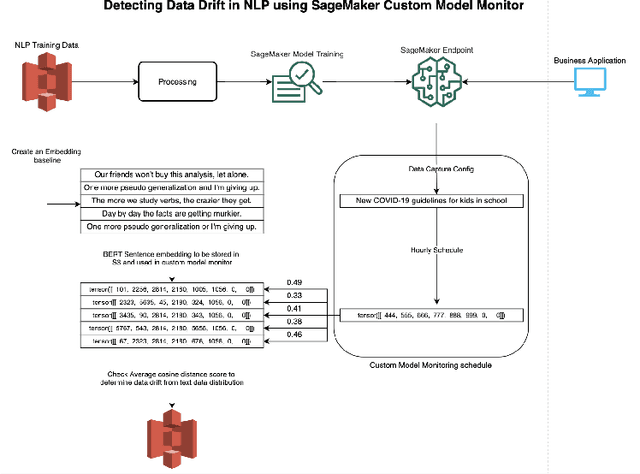
With the increasing adoption of machine learning (ML) models and systems in high-stakes settings across different industries, guaranteeing a model's performance after deployment has become crucial. Monitoring models in production is a critical aspect of ensuring their continued performance and reliability. We present Amazon SageMaker Model Monitor, a fully managed service that continuously monitors the quality of machine learning models hosted on Amazon SageMaker. Our system automatically detects data, concept, bias, and feature attribution drift in models in real-time and provides alerts so that model owners can take corrective actions and thereby maintain high quality models. We describe the key requirements obtained from customers, system design and architecture, and methodology for detecting different types of drift. Further, we provide quantitative evaluations followed by use cases, insights, and lessons learned from more than 1.5 years of production deployment.
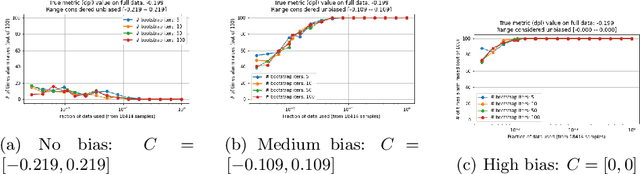
Amazon SageMaker Clarify: Machine Learning Bias Detection and Explainability in the Cloud
Sep 07, 2021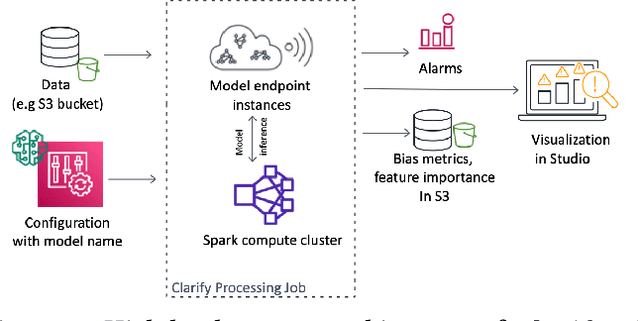
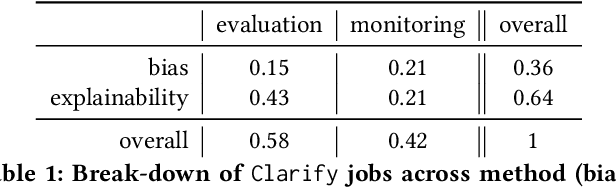
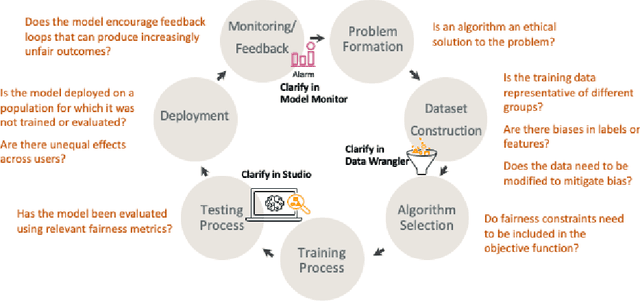
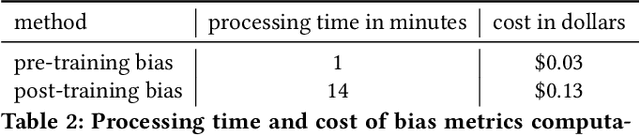
Understanding the predictions made by machine learning (ML) models and their potential biases remains a challenging and labor-intensive task that depends on the application, the dataset, and the specific model. We present Amazon SageMaker Clarify, an explainability feature for Amazon SageMaker that launched in December 2020, providing insights into data and ML models by identifying biases and explaining predictions. It is deeply integrated into Amazon SageMaker, a fully managed service that enables data scientists and developers to build, train, and deploy ML models at any scale. Clarify supports bias detection and feature importance computation across the ML lifecycle, during data preparation, model evaluation, and post-deployment monitoring. We outline the desiderata derived from customer input, the modular architecture, and the methodology for bias and explanation computations. Further, we describe the technical challenges encountered and the tradeoffs we had to make. For illustration, we discuss two customer use cases. We present our deployment results including qualitative customer feedback and a quantitative evaluation. Finally, we summarize lessons learned, and discuss best practices for the successful adoption of fairness and explanation tools in practice.