 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama-Nemotron: Efficient Reasoning Models
May 02, 2025



We introduce the Llama-Nemotron series of models, an open family of heterogeneous reasoning models that deliver exceptional reasoning capabilities, inference efficiency, and an open license for enterprise use. The family comes in three sizes -- Nano (8B), Super (49B), and Ultra (253B) -- and performs competitively with state-of-the-art reasoning models such as DeepSeek-R1 while offering superior inference throughput and memory efficiency. In this report, we discuss the training procedure for these models, which entails using neural architecture search from Llama 3 models for accelerated inference, knowledge distillation, and continued pretraining, followed by a reasoning-focused post-training stage consisting of two main parts: supervised fine-tuning and large scale reinforcement learning. Llama-Nemotron models are the first open-source models to support a dynamic reasoning toggle, allowing users to switch between standard chat and reasoning modes during inference. To further support open research and facilitate model development, we provide the following resources: 1. We release the Llama-Nemotron reasoning models -- LN-Nano, LN-Super, and LN-Ultra -- under the commercially permissive NVIDIA Open Model License Agreement. 2. We release the complete post-training dataset: Llama-Nemotron-Post-Training-Dataset. 3. We also release our training codebases: NeMo, NeMo-Aligner, and Megatron-LM.
Amazon SageMaker Clarify: Machine Learning Bias Detection and Explainability in the Cloud
Sep 07, 2021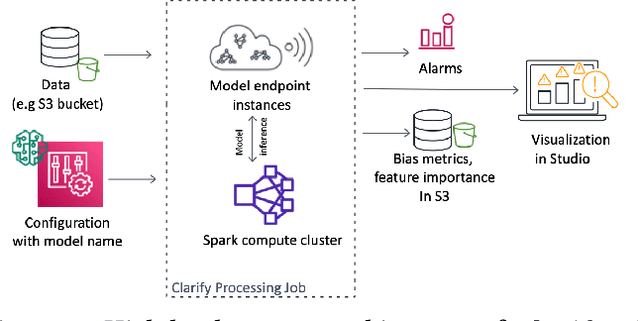
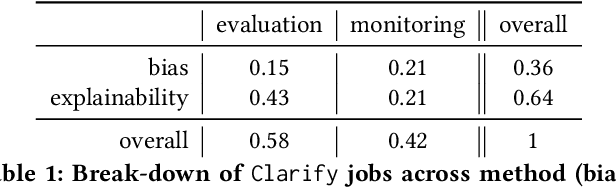
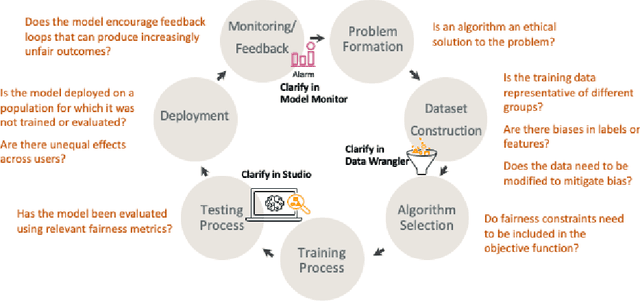
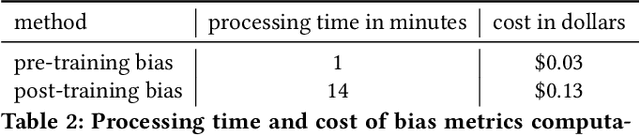
Understanding the predictions made by machine learning (ML) models and their potential biases remains a challenging and labor-intensive task that depends on the application, the dataset, and the specific model. We present Amazon SageMaker Clarify, an explainability feature for Amazon SageMaker that launched in December 2020, providing insights into data and ML models by identifying biases and explaining predictions. It is deeply integrated into Amazon SageMaker, a fully managed service that enables data scientists and developers to build, train, and deploy ML models at any scale. Clarify supports bias detection and feature importance computation across the ML lifecycle, during data preparation, model evaluation, and post-deployment monitoring. We outline the desiderata derived from customer input, the modular architecture, and the methodology for bias and explanation computations. Further, we describe the technical challenges encountered and the tradeoffs we had to make. For illustration, we discuss two customer use cases. We present our deployment results including qualitative customer feedback and a quantitative evaluation. Finally, we summarize lessons learned, and discuss best practices for the successful adoption of fairness and explanation tools in practice.
AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
Mar 13, 2020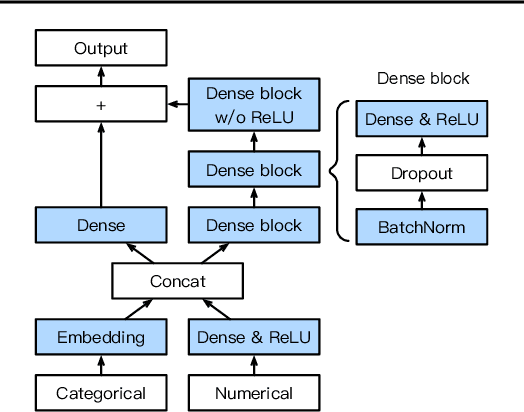

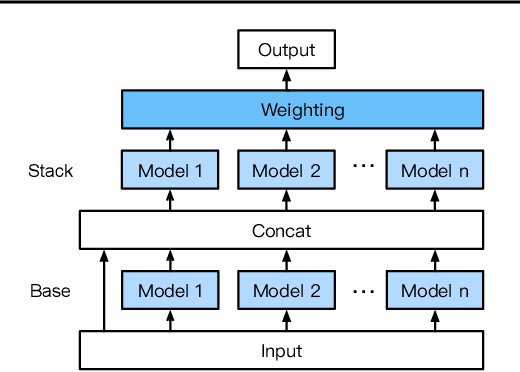

We introduce AutoGluon-Tabular, an open-source AutoML framework that requires only a single line of Python to train highly accurate machine learning models on an unprocessed tabular dataset such as a CSV file. Unlike existing AutoML frameworks that primarily focus on model/hyperparameter selection, AutoGluon-Tabular succeeds by ensembling multiple models and stacking them in multiple layers. Experiments reveal that our multi-layer combination of many models offers better use of allocated training time than seeking out the best. A second contribution is an extensive evaluation of public and commercial AutoML platforms including TPOT, H2O, AutoWEKA, auto-sklearn, AutoGluon, and Google AutoML Tables. Tests on a suite of 50 classification and regression tasks from Kaggle and the OpenML AutoML Benchmark reveal that AutoGluon is faster, more robust, and much more accurate. We find that AutoGluon often even outperforms the best-in-hindsight combination of all of its competitors. In two popular Kaggle competitions, AutoGluon beat 99% of the participating data scientists after merely 4h of training on the raw data.