 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBloom Origami Assays: Practical Group Testing
Jul 21, 2020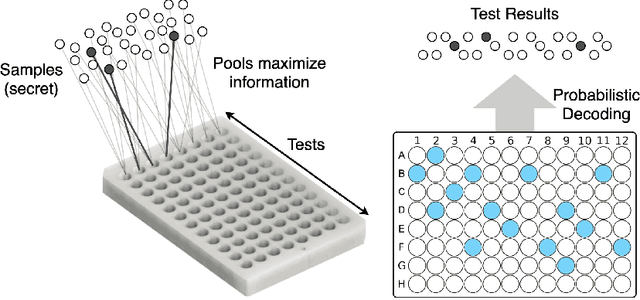
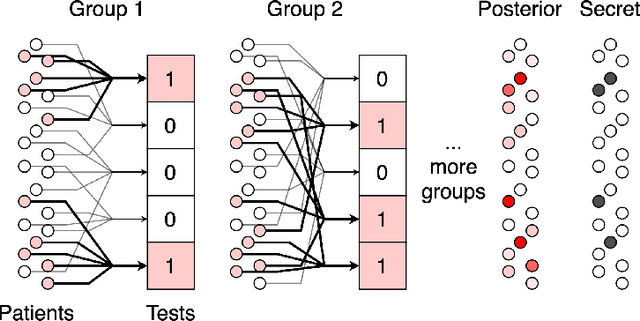
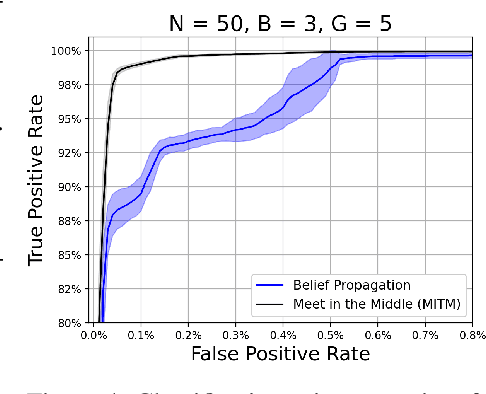
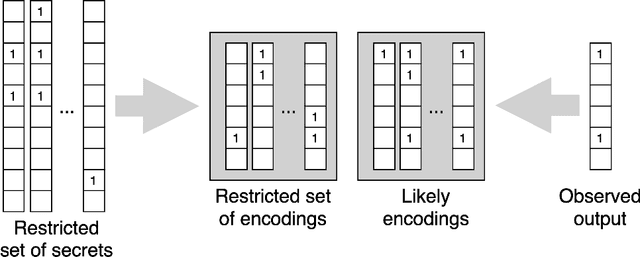
We study the problem usually referred to as group testing in the context of COVID-19. Given n samples collected from patients, how should we select and test mixtures of samples to maximize information and minimize the number of tests? Group testing is a well-studied problem with several appealing solutions, but recent biological studies impose practical constraints for COVID-19 that are incompatible with traditional methods. Furthermore, existing methods use unnecessarily restrictive solutions, which were devised for settings with more memory and compute constraints than the problem at hand. This results in poor utility. In the new setting, we obtain strong solutions for small values of n using evolutionary strategies. We then develop a new method combining Bloom filters with belief propagation to scale to larger values of n (more than 100) with good empirical results. We also present a more accurate decoding algorithm that is tailored for specific COVID-19 settings. This work demonstrates the practical gap between dedicated algorithms and well-known generic solutions. Our efforts results in a new and practical multiplex method yielding strong empirical performance without mixing more than a chosen number of patients into the same probe. Finally, we briefly discuss adaptive methods, casting them into the framework of adaptive sub-modularity.
Improving Semantic Segmentation via Self-Training
May 06, 2020
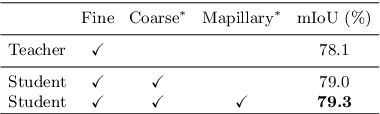
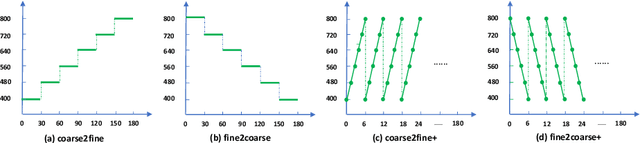
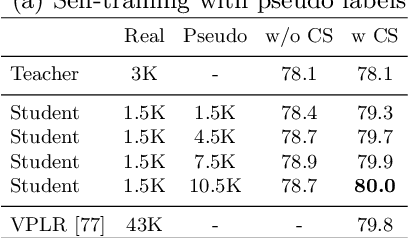
Deep learning usually achieves the best results with complete supervision. In the case of semantic segmentation, this means that large amounts of pixelwise annotations are required to learn accurate models. In this paper, we show that we can obtain state-of-the-art results using a semi-supervised approach, specifically a self-training paradigm. We first train a teacher model on labeled data, and then generate pseudo labels on a large set of unlabeled data. Our robust training framework can digest human-annotated and pseudo labels jointly and achieve top performances on Cityscapes, CamVid and KITTI datasets while requiring significantly less supervision. We also demonstrate the effectiveness of self-training on a challenging cross-domain generalization task, outperforming conventional finetuning method by a large margin. Lastly, to alleviate the computational burden caused by the large amount of pseudo labels, we propose a fast training schedule to accelerate the training of segmentation models by up to 2x without performance degradation.
ResNeSt: Split-Attention Networks
Apr 19, 2020
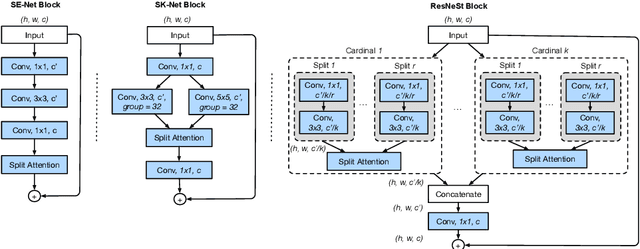
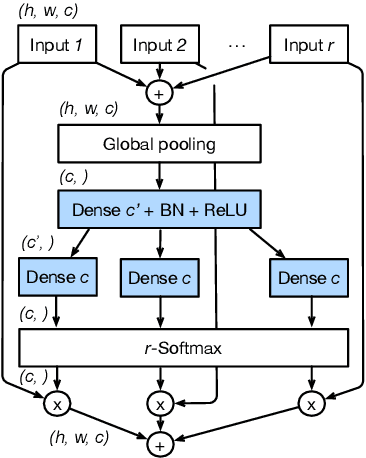
While image classification models have recently continued to advance, most downstream applications such as object detection and semantic segmentation still employ ResNet variants as the backbone network due to their simple and modular structure. We present a simple and modular Split-Attention block that enables attention across feature-map groups. By stacking these Split-Attention blocks ResNet-style, we obtain a new ResNet variant which we call ResNeSt. Our network preserves the overall ResNet structure to be used in downstream tasks straightforwardly without introducing additional computational costs. ResNeSt models outperform other networks with similar model complexities. For example, ResNeSt-50 achieves 81.13% top-1 accuracy on ImageNet using a single crop-size of 224x224, outperforming previous best ResNet variant by more than 1% accuracy. This improvement also helps downstream tasks including object detection, instance segmentation and semantic segmentation. For example, by simply replace the ResNet-50 backbone with ResNeSt-50, we improve the mAP of Faster-RCNN on MS-COCO from 39.3% to 42.3% and the mIoU for DeeplabV3 on ADE20K from 42.1% to 45.1%.
AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
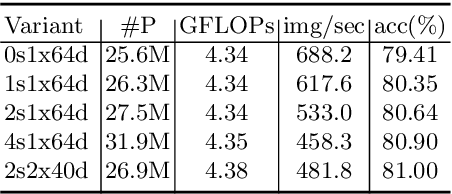
Mar 13, 2020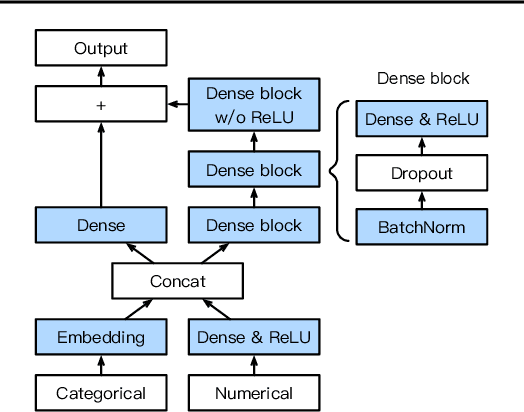

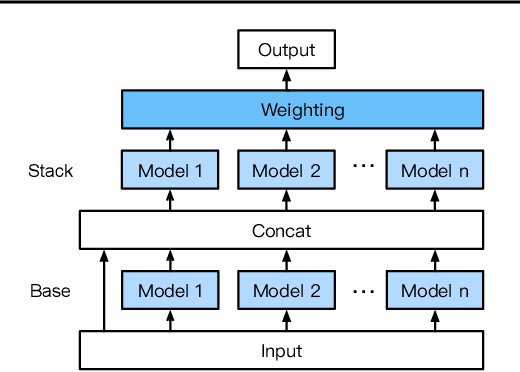

We introduce AutoGluon-Tabular, an open-source AutoML framework that requires only a single line of Python to train highly accurate machine learning models on an unprocessed tabular dataset such as a CSV file. Unlike existing AutoML frameworks that primarily focus on model/hyperparameter selection, AutoGluon-Tabular succeeds by ensembling multiple models and stacking them in multiple layers. Experiments reveal that our multi-layer combination of many models offers better use of allocated training time than seeking out the best. A second contribution is an extensive evaluation of public and commercial AutoML platforms including TPOT, H2O, AutoWEKA, auto-sklearn, AutoGluon, and Google AutoML Tables. Tests on a suite of 50 classification and regression tasks from Kaggle and the OpenML AutoML Benchmark reveal that AutoGluon is faster, more robust, and much more accurate. We find that AutoGluon often even outperforms the best-in-hindsight combination of all of its competitors. In two popular Kaggle competitions, AutoGluon beat 99% of the participating data scientists after merely 4h of training on the raw data.
Deep Graph Library: Towards Efficient and Scalable Deep Learning on Graphs
Sep 03, 2019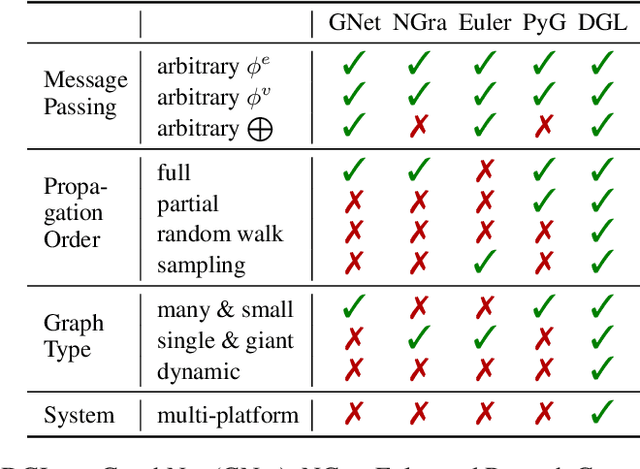
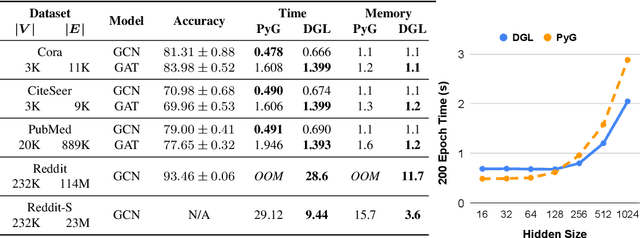
Accelerating research in the emerging field of deep graph learning requires new tools. Such systems should support graph as the core abstraction and take care to maintain both forward (i.e. supporting new research ideas) and backward (i.e. integration with existing components) compatibility. In this paper, we present Deep Graph Library (DGL). DGL enables arbitrary message handling and mutation operators, flexible propagation rules, and is framework agnostic so as to leverage high-performance tensor, autograd operations, and other feature extraction modules already available in existing frameworks. DGL carefully handles the sparse and irregular graph structure, deals with graphs big and small which may change dynamically, fuses operations, and performs auto-batching, all to take advantages of modern hardware. DGL has been tested on a variety of models, including but not limited to the popular Graph Neural Networks (GNN) and its variants, with promising speed, memory footprint and scalability.
Deep Sets
Apr 14, 2018
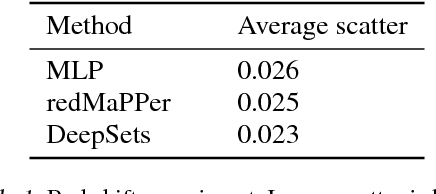
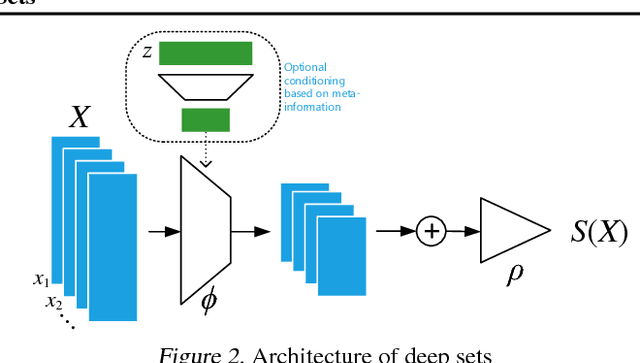
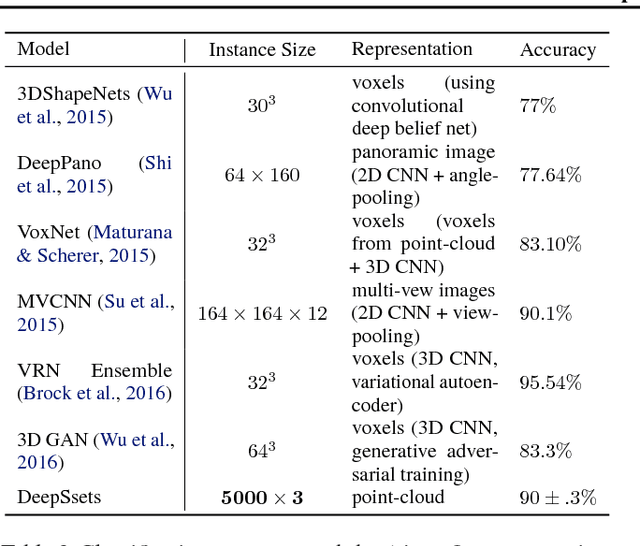
We study the problem of designing models for machine learning tasks defined on \emph{sets}. In contrast to traditional approach of operating on fixed dimensional vectors, we consider objective functions defined on sets that are invariant to permutations. Such problems are widespread, ranging from estimation of population statistics \cite{poczos13aistats}, to anomaly detection in piezometer data of embankment dams \cite{Jung15Exploration}, to cosmology \cite{Ntampaka16Dynamical,Ravanbakhsh16ICML1}. Our main theorem characterizes the permutation invariant functions and provides a family of functions to which any permutation invariant objective function must belong. This family of functions has a special structure which enables us to design a deep network architecture that can operate on sets and which can be deployed on a variety of scenarios including both unsupervised and supervised learning tasks. We also derive the necessary and sufficient conditions for permutation equivariance in deep models. We demonstrate the applicability of our method on population statistic estimation, point cloud classification, set expansion, and outlier detection.
Fast and Guaranteed Tensor Decomposition via Sketching
Oct 20, 2015
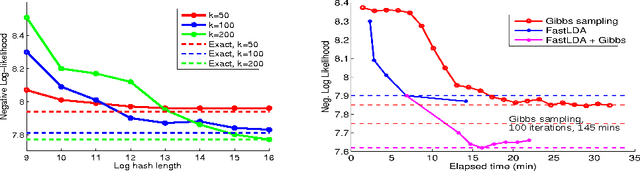

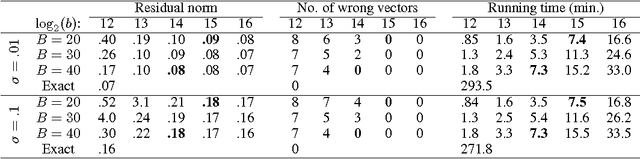
Tensor CANDECOMP/PARAFAC (CP) decomposition has wide applications in statistical learning of latent variable models and in data mining. In this paper, we propose fast and randomized tensor CP decomposition algorithms based on sketching. We build on the idea of count sketches, but introduce many novel ideas which are unique to tensors. We develop novel methods for randomized computation of tensor contractions via FFTs, without explicitly forming the tensors. Such tensor contractions are encountered in decomposition methods such as tensor power iterations and alternating least squares. We also design novel colliding hashes for symmetric tensors to further save time in computing the sketches. We then combine these sketching ideas with existing whitening and tensor power iterative techniques to obtain the fastest algorithm on both sparse and dense tensors. The quality of approximation under our method does not depend on properties such as sparsity, uniformity of elements, etc. We apply the method for topic modeling and obtain competitive results.
Slow Learners are Fast
Nov 03, 2009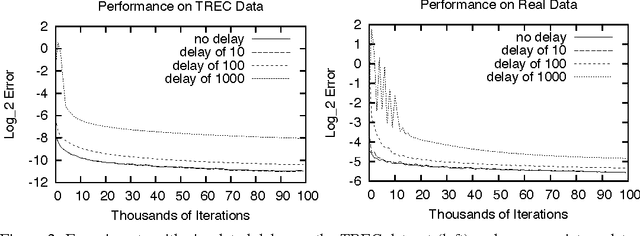

Online learning algorithms have impressive convergence properties when it comes to risk minimization and convex games on very large problems. However, they are inherently sequential in their design which prevents them from taking advantage of modern multi-core architectures. In this paper we prove that online learning with delayed updates converges well, thereby facilitating parallel online learning.
Direct Optimization of Ranking Measures
Apr 25, 2007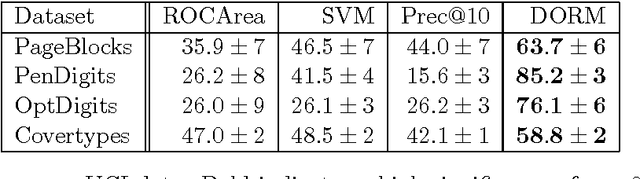
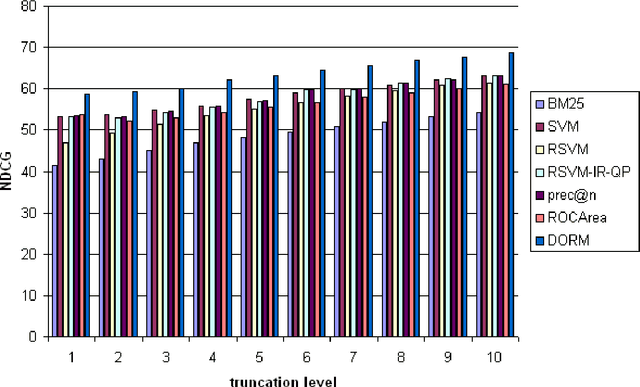
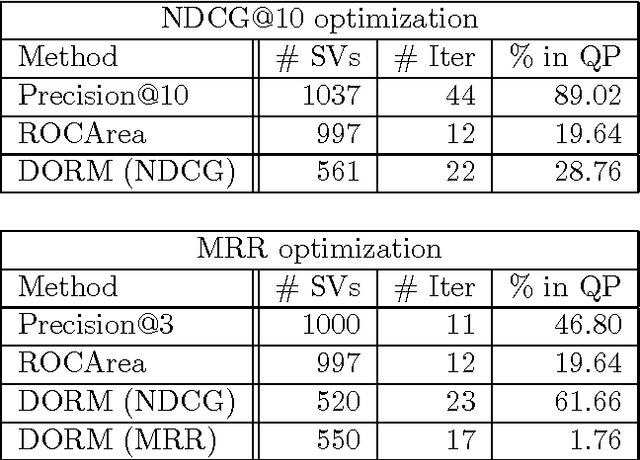
Web page ranking and collaborative filtering require the optimization of sophisticated performance measures. Current Support Vector approaches are unable to optimize them directly and focus on pairwise comparisons instead. We present a new approach which allows direct optimization of the relevant loss functions. This is achieved via structured estimation in Hilbert spaces. It is most related to Max-Margin-Markov networks optimization of multivariate performance measures. Key to our approach is that during training the ranking problem can be viewed as a linear assignment problem, which can be solved by the Hungarian Marriage algorithm. At test time, a sort operation is sufficient, as our algorithm assigns a relevance score to every (document, query) pair. Experiments show that the our algorithm is fast and that it works very well.