 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStateful Large Language Model Serving with Pensieve
Dec 09, 2023



Large Language Models (LLMs) have recently experienced great success, as evident in the widespread popularity of ChatGPT. Existing LLM serving systems are stateless across requests. Consequently, when LLMs are used in the common setting of multi-turn conversations, a growing log of the conversation history must be processed alongside any request by the serving system at each turn, resulting in repeated history processing. In this paper, we design $Pensieve$, a system optimized for multi-turn conversation LLM serving. $Pensieve$ maintains the conversation state across requests by caching previously processed history to avoid duplicate processing. $Pensieve$'s multi-tier caching strategy can utilize both GPU and CPU memory to efficiently store and retrieve cached data. $Pensieve$ also generalizes the recent PagedAttention kernel to support attention between multiple input tokens with a GPU cache spread over non-contiguous memory. Our evaluation shows that $Pensieve$ is able to achieve 1.51-1.95x throughput compared to vLLM and reduce latency by 60-75%.
Scalable Graph Neural Networks for Heterogeneous Graphs
Nov 19, 2020


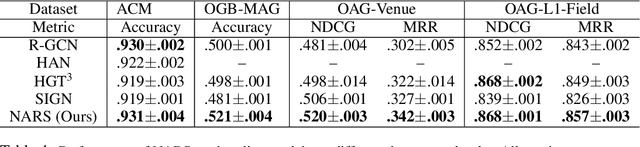
Graph neural networks (GNNs) are a popular class of parametric model for learning over graph-structured data. Recent work has argued that GNNs primarily use the graph for feature smoothing, and have shown competitive results on benchmark tasks by simply operating on graph-smoothed node features, rather than using end-to-end learned feature hierarchies that are challenging to scale to large graphs. In this work, we ask whether these results can be extended to heterogeneous graphs, which encode multiple types of relationship between different entities. We propose Neighbor Averaging over Relation Subgraphs (NARS), which trains a classifier on neighbor-averaged features for randomly-sampled subgraphs of the "metagraph" of relations. We describe optimizations to allow these sets of node features to be computed in a memory-efficient way, both at training and inference time. NARS achieves a new state of the art accuracy on several benchmark datasets, outperforming more expensive GNN-based methods
Deep Graph Library: Towards Efficient and Scalable Deep Learning on Graphs
Sep 03, 2019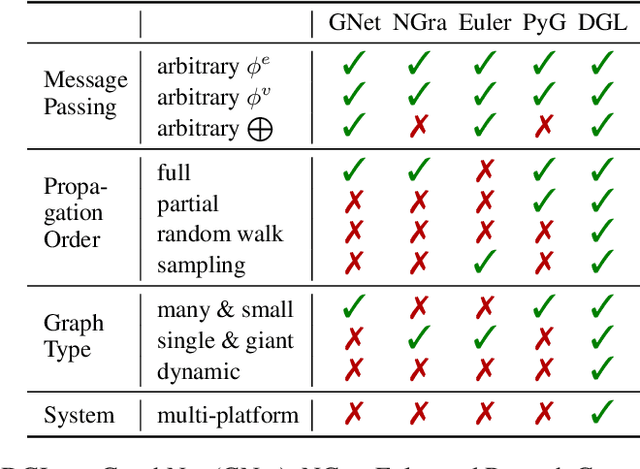
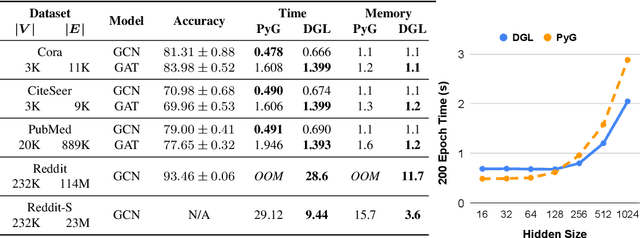
Accelerating research in the emerging field of deep graph learning requires new tools. Such systems should support graph as the core abstraction and take care to maintain both forward (i.e. supporting new research ideas) and backward (i.e. integration with existing components) compatibility. In this paper, we present Deep Graph Library (DGL). DGL enables arbitrary message handling and mutation operators, flexible propagation rules, and is framework agnostic so as to leverage high-performance tensor, autograd operations, and other feature extraction modules already available in existing frameworks. DGL carefully handles the sparse and irregular graph structure, deals with graphs big and small which may change dynamically, fuses operations, and performs auto-batching, all to take advantages of modern hardware. DGL has been tested on a variety of models, including but not limited to the popular Graph Neural Networks (GNN) and its variants, with promising speed, memory footprint and scalability.