 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering Context in Off-Policy Evaluation
Feb 28, 2025Off-policy evaluation can leverage logged data to estimate the effectiveness of new policies in e-commerce, search engines, media streaming services, or automatic diagnostic tools in healthcare. However, the performance of baseline off-policy estimators like IPS deteriorates when the logging policy significantly differs from the evaluation policy. Recent work proposes sharing information across similar actions to mitigate this problem. In this work, we propose an alternative estimator that shares information across similar contexts using clustering. We study the theoretical properties of the proposed estimator, characterizing its bias and variance under different conditions. We also compare the performance of the proposed estimator and existing approaches in various synthetic problems, as well as a real-world recommendation dataset. Our experimental results confirm that clustering contexts improves estimation accuracy, especially in deficient information settings.
Guiding Catalogue Enrichment with User Queries
Jun 11, 2024Techniques for knowledge graph (KGs) enrichment have been increasingly crucial for commercial applications that rely on evolving product catalogues. However, because of the huge search space of potential enrichment, predictions from KG completion (KGC) methods suffer from low precision, making them unreliable for real-world catalogues. Moreover, candidate facts for enrichment have varied relevance to users. While making correct predictions for incomplete triplets in KGs has been the main focus of KGC method, the relevance of when to apply such predictions has been neglected. Motivated by the product search use case, we address the angle of generating relevant completion for a catalogue using user search behaviour and the users property association with a product. In this paper, we present our intuition for identifying enrichable data points and use general-purpose KGs to show-case the performance benefits. In particular, we extract entity-predicate pairs from user queries, which are more likely to be correct and relevant, and use these pairs to guide the prediction of KGC methods. We assess our method on two popular encyclopedia KGs, DBPedia and YAGO 4. Our results from both automatic and human evaluations show that query guidance can significantly improve the correctness and relevance of prediction.
Learning Action Embeddings for Off-Policy Evaluation
May 06, 2023Off-policy evaluation (OPE) methods allow us to compute the expected reward of a policy by using the logged data collected by a different policy. OPE is a viable alternative to running expensive online A/B tests: it can speed up the development of new policies, and reduces the risk of exposing customers to suboptimal treatments. However, when the number of actions is large, or certain actions are under-explored by the logging policy, existing estimators based on inverse-propensity scoring (IPS) can have a high or even infinite variance. Saito and Joachims (arXiv:2202.06317v2 [cs.LG]) propose marginalized IPS (MIPS) that uses action embeddings instead, which reduces the variance of IPS in large action spaces. MIPS assumes that good action embeddings can be defined by the practitioner, which is difficult to do in many real-world applications. In this work, we explore learning action embeddings from logged data. In particular, we use intermediate outputs of a trained reward model to define action embeddings for MIPS. This approach extends MIPS to more applications, and in our experiments improves upon MIPS with pre-defined embeddings, as well as standard baselines, both on synthetic and real-world data. Our method does not make assumptions about the reward model class, and supports using additional action information to further improve the estimates. The proposed approach presents an appealing alternative to DR for combining the low variance of DM with the low bias of IPS.
Variational Boosted Soft Trees
Feb 22, 2023Gradient boosting machines (GBMs) based on decision trees consistently demonstrate state-of-the-art results on regression and classification tasks with tabular data, often outperforming deep neural networks. However, these models do not provide well-calibrated predictive uncertainties, which prevents their use for decision making in high-risk applications. The Bayesian treatment is known to improve predictive uncertainty calibration, but previously proposed Bayesian GBM methods are either computationally expensive, or resort to crude approximations. Variational inference is often used to implement Bayesian neural networks, but is difficult to apply to GBMs, because the decision trees used as weak learners are non-differentiable. In this paper, we propose to implement Bayesian GBMs using variational inference with soft decision trees, a fully differentiable alternative to standard decision trees introduced by Irsoy et al. Our experiments demonstrate that variational soft trees and variational soft GBMs provide useful uncertainty estimates, while retaining good predictive performance. The proposed models show higher test likelihoods when compared to the state-of-the-art Bayesian GBMs in 7/10 tabular regression datasets and improved out-of-distribution detection in 5/10 datasets.
More Than Words: Towards Better Quality Interpretations of Text Classifiers
Dec 23, 2021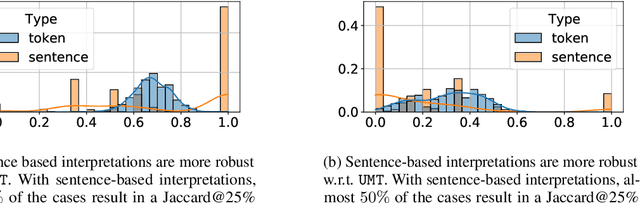



The large size and complex decision mechanisms of state-of-the-art text classifiers make it difficult for humans to understand their predictions, leading to a potential lack of trust by the users. These issues have led to the adoption of methods like SHAP and Integrated Gradients to explain classification decisions by assigning importance scores to input tokens. However, prior work, using different randomization tests, has shown that interpretations generated by these methods may not be robust. For instance, models making the same predictions on the test set may still lead to different feature importance rankings. In order to address the lack of robustness of token-based interpretability, we explore explanations at higher semantic levels like sentences. We use computational metrics and human subject studies to compare the quality of sentence-based interpretations against token-based ones. Our experiments show that higher-level feature attributions offer several advantages: 1) they are more robust as measured by the randomization tests, 2) they lead to lower variability when using approximation-based methods like SHAP, and 3) they are more intelligible to humans in situations where the linguistic coherence resides at a higher granularity level. Based on these findings, we show that token-based interpretability, while being a convenient first choice given the input interfaces of the ML models, is not the most effective one in all situations.
Quantifying Interpretability and Trust in Machine Learning Systems
Jan 20, 2019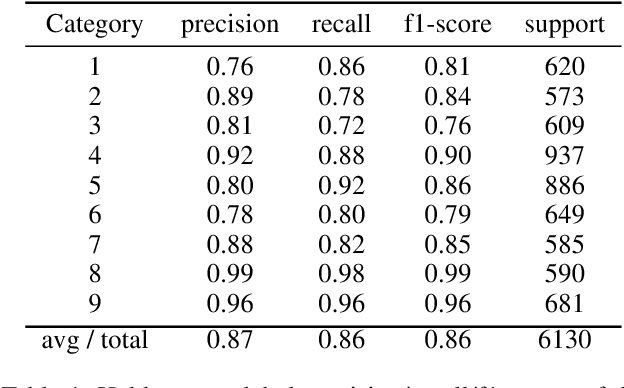

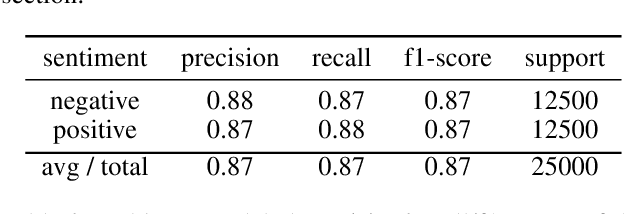
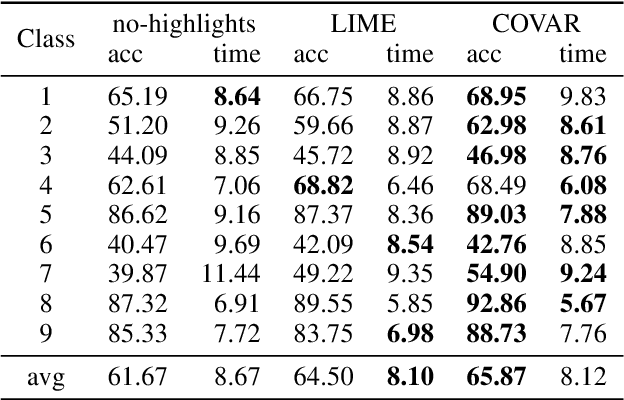
Decisions by Machine Learning (ML) models have become ubiquitous. Trusting these decisions requires understanding how algorithms take them. Hence interpretability methods for ML are an active focus of research. A central problem in this context is that both the quality of interpretability methods as well as trust in ML predictions are difficult to measure. Yet evaluations, comparisons and improvements of trust and interpretability require quantifiable measures. Here we propose a quantitative measure for the quality of interpretability methods. Based on that we derive a quantitative measure of trust in ML decisions. Building on previous work we propose to measure intuitive understanding of algorithmic decisions using the information transfer rate at which humans replicate ML model predictions. We provide empirical evidence from crowdsourcing experiments that the proposed metric robustly differentiates interpretability methods. The proposed metric also demonstrates the value of interpretability for ML assisted human decision making: in our experiments providing explanations more than doubled productivity in annotation tasks. However unbiased human judgement is critical for doctors, judges, policy makers and others. Here we derive a trust metric that identifies when human decisions are overly biased towards ML predictions. Our results complement existing qualitative work on trust and interpretability by quantifiable measures that can serve as objectives for further improving methods in this field of research.