 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering Context in Off-Policy Evaluation
Feb 28, 2025Off-policy evaluation can leverage logged data to estimate the effectiveness of new policies in e-commerce, search engines, media streaming services, or automatic diagnostic tools in healthcare. However, the performance of baseline off-policy estimators like IPS deteriorates when the logging policy significantly differs from the evaluation policy. Recent work proposes sharing information across similar actions to mitigate this problem. In this work, we propose an alternative estimator that shares information across similar contexts using clustering. We study the theoretical properties of the proposed estimator, characterizing its bias and variance under different conditions. We also compare the performance of the proposed estimator and existing approaches in various synthetic problems, as well as a real-world recommendation dataset. Our experimental results confirm that clustering contexts improves estimation accuracy, especially in deficient information settings.
Learning Action Embeddings for Off-Policy Evaluation
May 06, 2023Off-policy evaluation (OPE) methods allow us to compute the expected reward of a policy by using the logged data collected by a different policy. OPE is a viable alternative to running expensive online A/B tests: it can speed up the development of new policies, and reduces the risk of exposing customers to suboptimal treatments. However, when the number of actions is large, or certain actions are under-explored by the logging policy, existing estimators based on inverse-propensity scoring (IPS) can have a high or even infinite variance. Saito and Joachims (arXiv:2202.06317v2 [cs.LG]) propose marginalized IPS (MIPS) that uses action embeddings instead, which reduces the variance of IPS in large action spaces. MIPS assumes that good action embeddings can be defined by the practitioner, which is difficult to do in many real-world applications. In this work, we explore learning action embeddings from logged data. In particular, we use intermediate outputs of a trained reward model to define action embeddings for MIPS. This approach extends MIPS to more applications, and in our experiments improves upon MIPS with pre-defined embeddings, as well as standard baselines, both on synthetic and real-world data. Our method does not make assumptions about the reward model class, and supports using additional action information to further improve the estimates. The proposed approach presents an appealing alternative to DR for combining the low variance of DM with the low bias of IPS.
Variational Boosted Soft Trees
Feb 22, 2023Gradient boosting machines (GBMs) based on decision trees consistently demonstrate state-of-the-art results on regression and classification tasks with tabular data, often outperforming deep neural networks. However, these models do not provide well-calibrated predictive uncertainties, which prevents their use for decision making in high-risk applications. The Bayesian treatment is known to improve predictive uncertainty calibration, but previously proposed Bayesian GBM methods are either computationally expensive, or resort to crude approximations. Variational inference is often used to implement Bayesian neural networks, but is difficult to apply to GBMs, because the decision trees used as weak learners are non-differentiable. In this paper, we propose to implement Bayesian GBMs using variational inference with soft decision trees, a fully differentiable alternative to standard decision trees introduced by Irsoy et al. Our experiments demonstrate that variational soft trees and variational soft GBMs provide useful uncertainty estimates, while retaining good predictive performance. The proposed models show higher test likelihoods when compared to the state-of-the-art Bayesian GBMs in 7/10 tabular regression datasets and improved out-of-distribution detection in 5/10 datasets.
Ordering Dimensions with Nested Dropout Normalizing Flows
Jun 15, 2020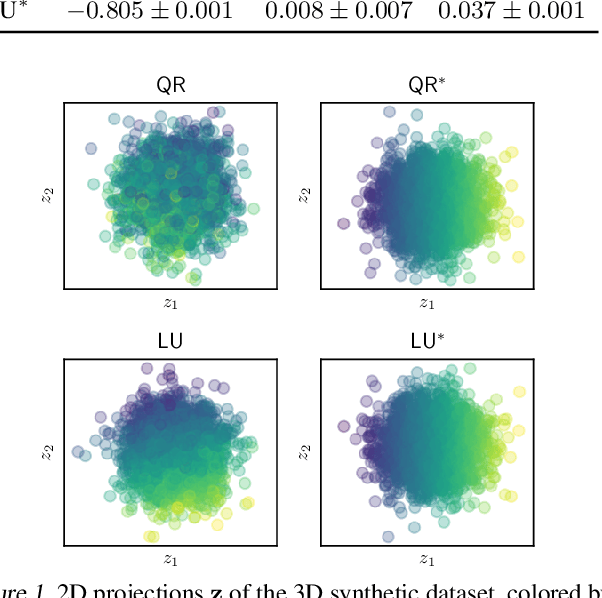
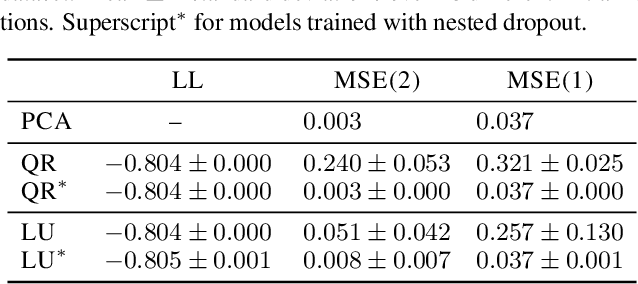

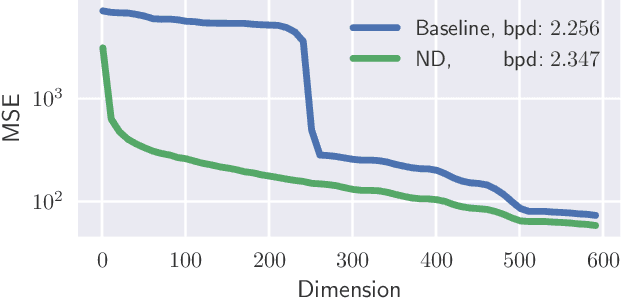
The latent space of normalizing flows must be of the same dimensionality as their output space. This constraint presents a problem if we want to learn low-dimensional, semantically meaningful representations. Recent work has provided compact representations by fitting flows constrained to manifolds, but hasn't defined a density off that manifold. In this work we consider flows with full support in data space, but with ordered latent variables. Like in PCA, the leading latent dimensions define a sequence of manifolds that lie close to the data. We note a trade-off between the flow likelihood and the quality of the ordering, depending on the parameterization of the flow.
Neural Spline Flows
Jun 10, 2019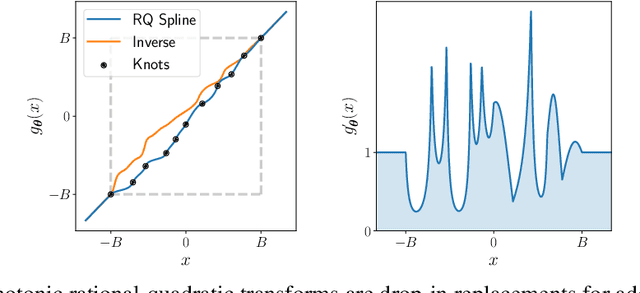
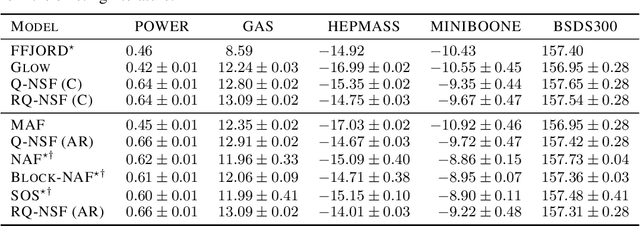
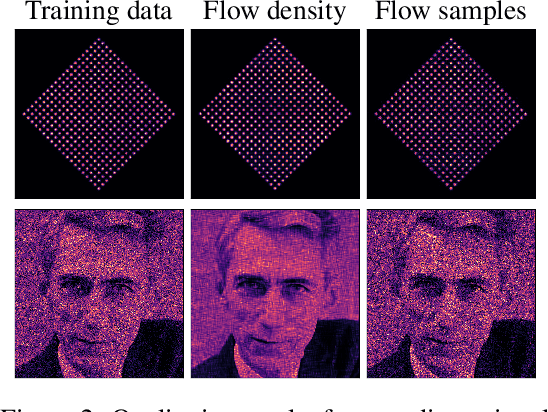
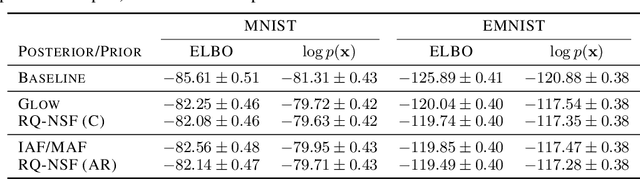
A normalizing flow models a complex probability density as an invertible transformation of a simple base density. Flows based on either coupling or autoregressive transforms both offer exact density evaluation and sampling, but rely on the parameterization of an easily invertible elementwise transformation, whose choice determines the flexibility of these models. Building upon recent work, we propose a fully-differentiable module based on monotonic rational-quadratic splines, which enhances the flexibility of both coupling and autoregressive transforms while retaining analytic invertibility. We demonstrate that neural spline flows improve density estimation, variational inference, and generative modeling of images.
Cubic-Spline Flows
Jun 05, 2019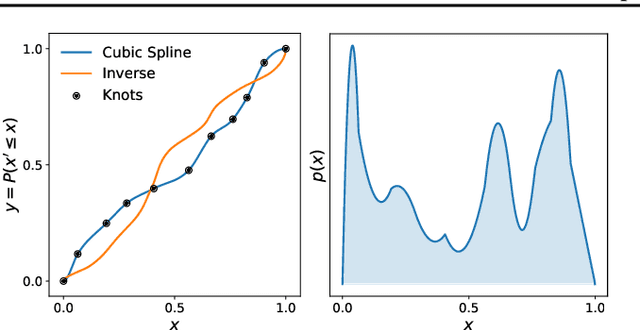

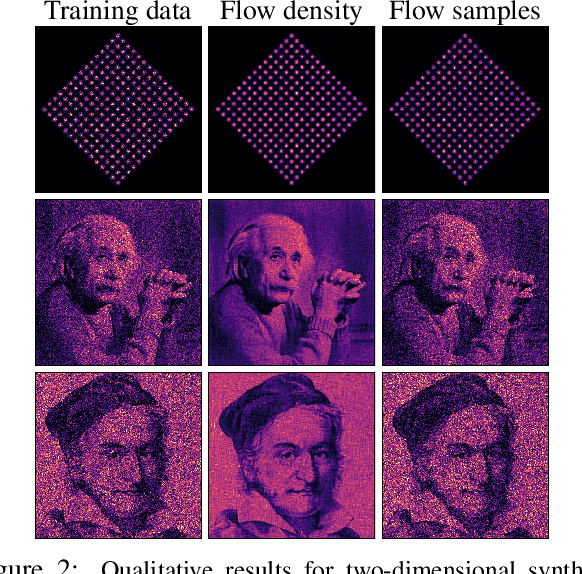

A normalizing flow models a complex probability density as an invertible transformation of a simple density. The invertibility means that we can evaluate densities and generate samples from a flow. In practice, autoregressive flow-based models are slow to invert, making either density estimation or sample generation slow. Flows based on coupling transforms are fast for both tasks, but have previously performed less well at density estimation than autoregressive flows. We stack a new coupling transform, based on monotonic cubic splines, with LU-decomposed linear layers. The resulting cubic-spline flow retains an exact one-pass inverse, can be used to generate high-quality images, and closes the gap with autoregressive flows on a suite of density-estimation tasks.
Bayesian Adversarial Spheres: Bayesian Inference and Adversarial Examples in a Noiseless Setting
Nov 29, 2018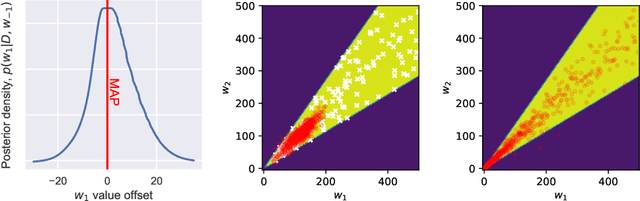
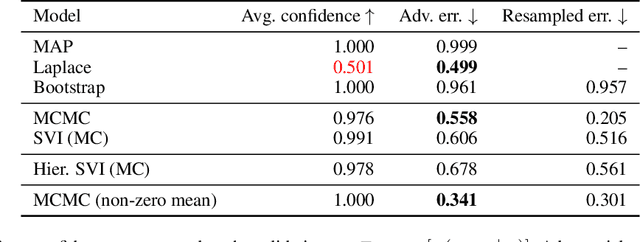
Modern deep neural network models suffer from adversarial examples, i.e. confidently misclassified points in the input space. It has been shown that Bayesian neural networks are a promising approach for detecting adversarial points, but careful analysis is problematic due to the complexity of these models. Recently Gilmer et al. (2018) introduced adversarial spheres, a toy set-up that simplifies both practical and theoretical analysis of the problem. In this work, we use the adversarial sphere set-up to understand the properties of approximate Bayesian inference methods for a linear model in a noiseless setting. We compare predictions of Bayesian and non-Bayesian methods, showcasing the advantages of the former, although revealing open challenges for deep learning applications.