 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen LLMs get significantly worse: A statistical approach to detect model degradations
Feb 09, 2026Minimizing the inference cost and latency of foundation models has become a crucial area of research. Optimization approaches include theoretically lossless methods and others without accuracy guarantees like quantization. In all of these cases it is crucial to ensure that the model quality has not degraded. However, even at temperature zero, model generations are not necessarily robust even to theoretically lossless model optimizations due to numerical errors. We thus require statistical tools to decide whether a finite-sample accuracy deviation is an evidence of a model's degradation or whether it can be attributed to (harmless) noise in the evaluation. We propose a statistically sound hypothesis testing framework based on McNemar's test allowing to efficiently detect model degradations, while guaranteeing a controlled rate of false positives. The crucial insight is that we have to confront the model scores on each sample, rather than aggregated on the task level. Furthermore, we propose three approaches to aggregate accuracy estimates across multiple benchmarks into a single decision. We provide an implementation on top of the largely adopted open source LM Evaluation Harness and provide a case study illustrating that the method correctly flags degraded models, while not flagging model optimizations that are provably lossless. We find that with our tests even empirical accuracy degradations of 0.3% can be confidently attributed to actual degradations rather than noise.
* https://openreview.net/forum?id=cM3gsqEI4K
A Proximal Operator for Inducing 2:4-Sparsity
Jan 29, 2025



Recent hardware advancements in AI Accelerators and GPUs allow to efficiently compute sparse matrix multiplications, especially when 2 out of 4 consecutive weights are set to zero. However, this so-called 2:4 sparsity usually comes at a decreased accuracy of the model. We derive a regularizer that exploits the local correlation of features to find better sparsity masks in trained models. We minimize the regularizer jointly with a local squared loss by deriving the proximal operator for which we show that it has an efficient solution in the 2:4-sparse case. After optimizing the mask, we use maskedgradient updates to further minimize the local squared loss. We illustrate our method on toy problems and apply it to pruning entire large language models up to 70B parameters. On models up to 13B we improve over previous state of the art algorithms, whilst on 70B models we match their performance.
Inference Optimization of Foundation Models on AI Accelerators
Jul 12, 2024



Powerful foundation models, including large language models (LLMs), with Transformer architectures have ushered in a new era of Generative AI across various industries. Industry and research community have witnessed a large number of new applications, based on those foundation models. Such applications include question and answer, customer services, image and video generation, and code completions, among others. However, as the number of model parameters reaches to hundreds of billions, their deployment incurs prohibitive inference costs and high latency in real-world scenarios. As a result, the demand for cost-effective and fast inference using AI accelerators is ever more higher. To this end, our tutorial offers a comprehensive discussion on complementary inference optimization techniques using AI accelerators. Beginning with an overview of basic Transformer architectures and deep learning system frameworks, we deep dive into system optimization techniques for fast and memory-efficient attention computations and discuss how they can be implemented efficiently on AI accelerators. Next, we describe architectural elements that are key for fast transformer inference. Finally, we examine various model compression and fast decoding strategies in the same context.
Efficient fair PCA for fair representation learning
Feb 26, 2023We revisit the problem of fair principal component analysis (PCA), where the goal is to learn the best low-rank linear approximation of the data that obfuscates demographic information. We propose a conceptually simple approach that allows for an analytic solution similar to standard PCA and can be kernelized. Our methods have the same complexity as standard PCA, or kernel PCA, and run much faster than existing methods for fair PCA based on semidefinite programming or manifold optimization, while achieving similar results.
Individual Preference Stability for Clustering
Jul 07, 2022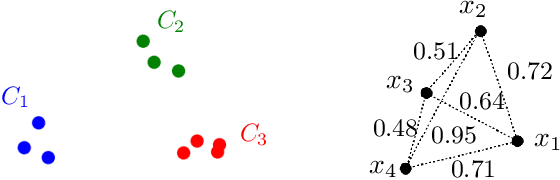
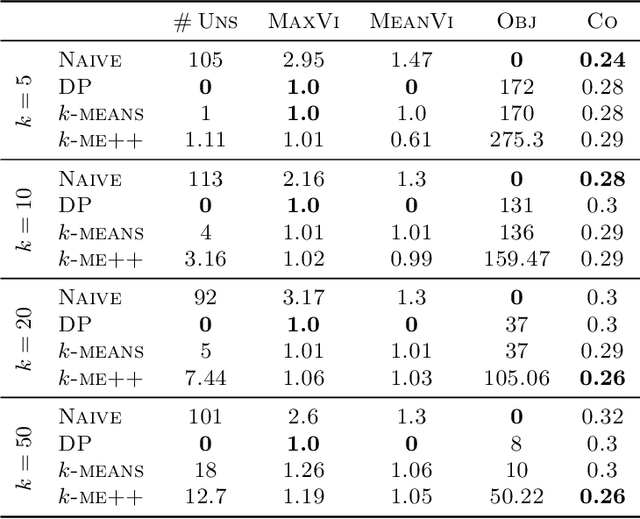
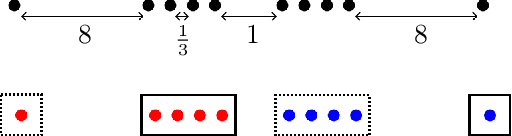
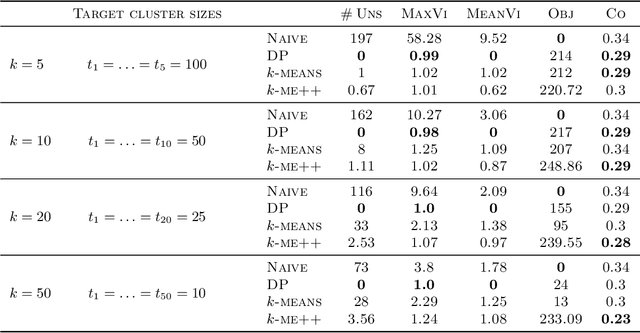
In this paper, we propose a natural notion of individual preference (IP) stability for clustering, which asks that every data point, on average, is closer to the points in its own cluster than to the points in any other cluster. Our notion can be motivated from several perspectives, including game theory and algorithmic fairness. We study several questions related to our proposed notion. We first show that deciding whether a given data set allows for an IP-stable clustering in general is NP-hard. As a result, we explore the design of efficient algorithms for finding IP-stable clusterings in some restricted metric spaces. We present a polytime algorithm to find a clustering satisfying exact IP-stability on the real line, and an efficient algorithm to find an IP-stable 2-clustering for a tree metric. We also consider relaxing the stability constraint, i.e., every data point should not be too far from its own cluster compared to any other cluster. For this case, we provide polytime algorithms with different guarantees. We evaluate some of our algorithms and several standard clustering approaches on real data sets.
Are Two Heads the Same as One? Identifying Disparate Treatment in Fair Neural Networks
Apr 09, 2022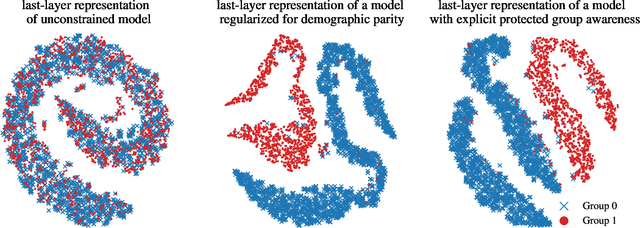
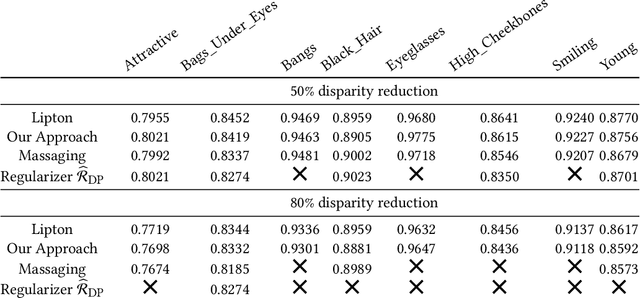
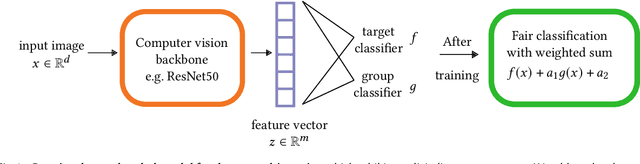
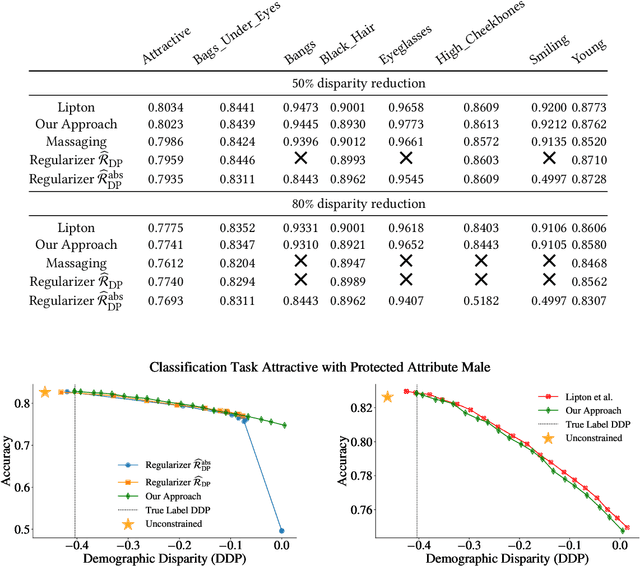
We show that deep neural networks that satisfy demographic parity do so through a form of race or gender awareness, and that the more we force a network to be fair, the more accurately we can recover race or gender from the internal state of the network. Based on this observation, we propose a simple two-stage solution for enforcing fairness. First, we train a two-headed network to predict the protected attribute (such as race or gender) alongside the original task, and second, we enforce demographic parity by taking a weighted sum of the heads. In the end, this approach creates a single-headed network with the same backbone architecture as the original network. Our approach has near identical performance compared to existing regularization-based or preprocessing methods, but has greater stability and higher accuracy where near exact demographic parity is required. To cement the relationship between these two approaches, we show that an unfair and optimally accurate classifier can be recovered by taking a weighted sum of a fair classifier and a classifier predicting the protected attribute. We use this to argue that both the fairness approaches and our explicit formulation demonstrate disparate treatment and that, consequentially, they are likely to be unlawful in a wide range of scenarios under the US law.
Leveling Down in Computer Vision: Pareto Inefficiencies in Fair Deep Classifiers
Mar 31, 2022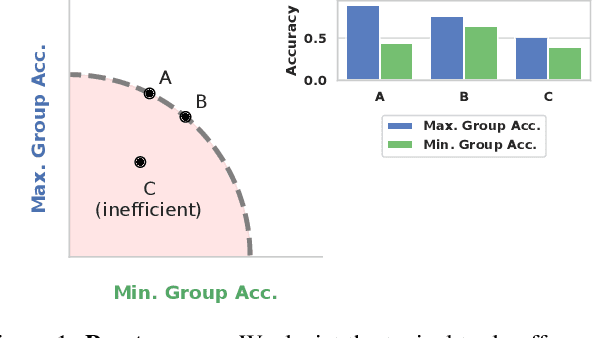
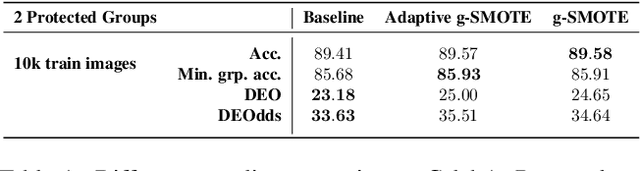
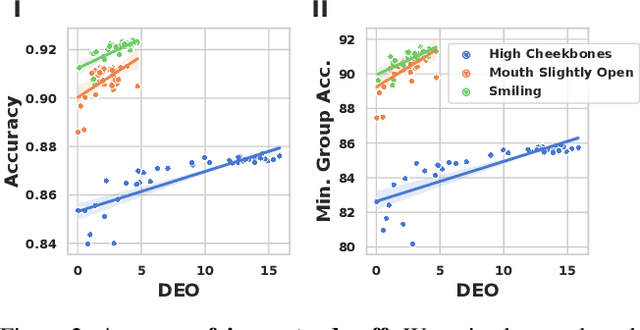
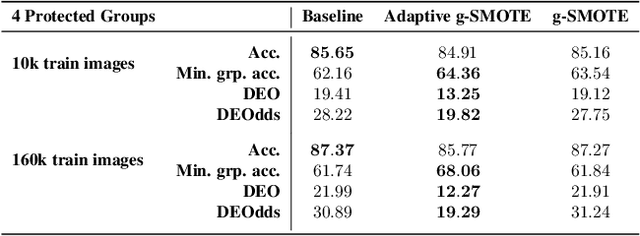
Algorithmic fairness is frequently motivated in terms of a trade-off in which overall performance is decreased so as to improve performance on disadvantaged groups where the algorithm would otherwise be less accurate. Contrary to this, we find that applying existing fairness approaches to computer vision improve fairness by degrading the performance of classifiers across all groups (with increased degradation on the best performing groups). Extending the bias-variance decomposition for classification to fairness, we theoretically explain why the majority of fairness classifiers designed for low capacity models should not be used in settings involving high-capacity models, a scenario common to computer vision. We corroborate this analysis with extensive experimental support that shows that many of the fairness heuristics used in computer vision also degrade performance on the most disadvantaged groups. Building on these insights, we propose an adaptive augmentation strategy that, uniquely, of all methods tested, improves performance for the disadvantaged groups.
Score matching enables causal discovery of nonlinear additive noise models
Mar 08, 2022
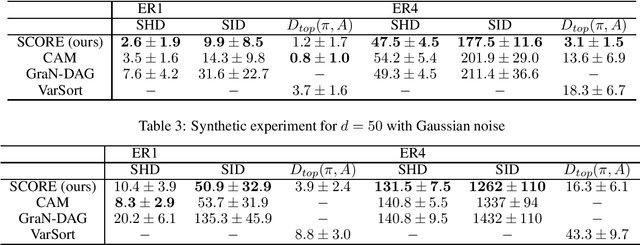
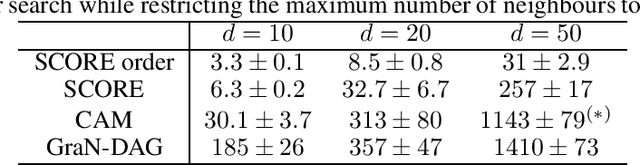
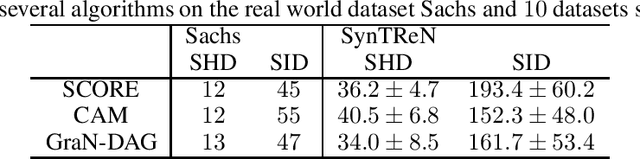
This paper demonstrates how to recover causal graphs from the score of the data distribution in non-linear additive (Gaussian) noise models. Using score matching algorithms as a building block, we show how to design a new generation of scalable causal discovery methods. To showcase our approach, we also propose a new efficient method for approximating the score's Jacobian, enabling to recover the causal graph. Empirically, we find that the new algorithm, called SCORE, is competitive with state-of-the-art causal discovery methods while being significantly faster.
Backward-Compatible Prediction Updates: A Probabilistic Approach
Jul 02, 2021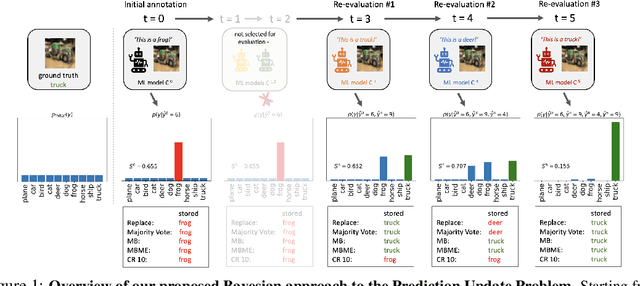
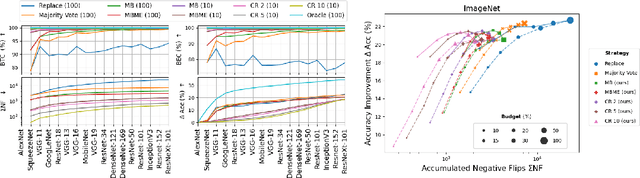
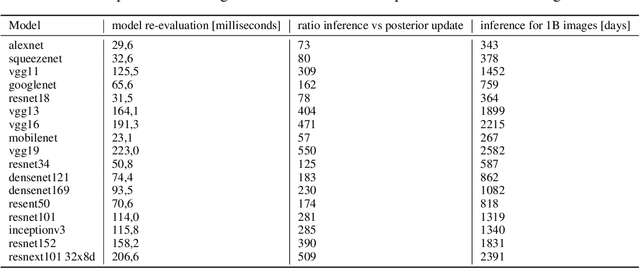
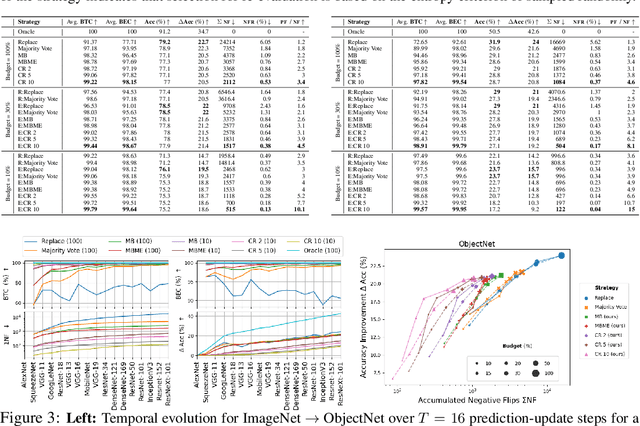
When machine learning systems meet real world applications, accuracy is only one of several requirements. In this paper, we assay a complementary perspective originating from the increasing availability of pre-trained and regularly improving state-of-the-art models. While new improved models develop at a fast pace, downstream tasks vary more slowly or stay constant. Assume that we have a large unlabelled data set for which we want to maintain accurate predictions. Whenever a new and presumably better ML models becomes available, we encounter two problems: (i) given a limited budget, which data points should be re-evaluated using the new model?; and (ii) if the new predictions differ from the current ones, should we update? Problem (i) is about compute cost, which matters for very large data sets and models. Problem (ii) is about maintaining consistency of the predictions, which can be highly relevant for downstream applications; our demand is to avoid negative flips, i.e., changing correct to incorrect predictions. In this paper, we formalize the Prediction Update Problem and present an efficient probabilistic approach as answer to the above questions. In extensive experiments on standard classification benchmark data sets, we show that our method outperforms alternative strategies along key metrics for backward-compatible prediction updates.
Pairwise Fairness for Ordinal Regression
May 07, 2021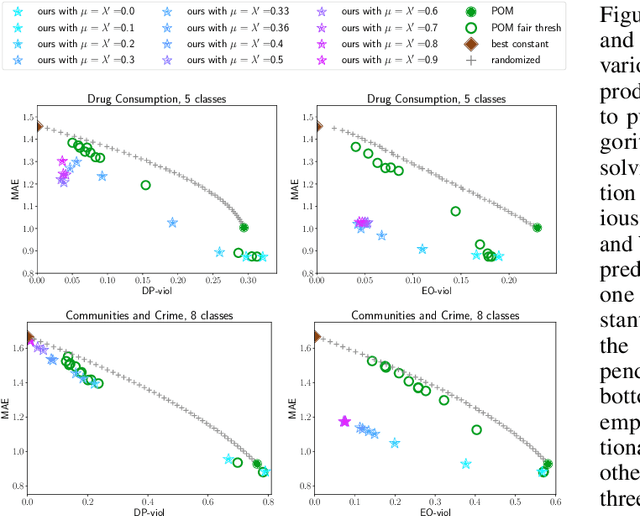
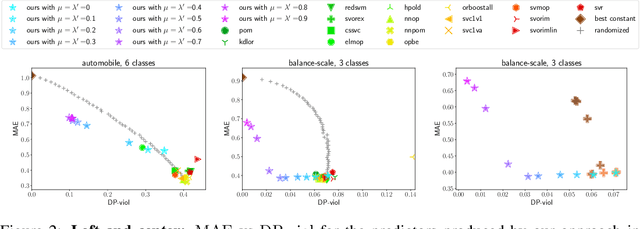
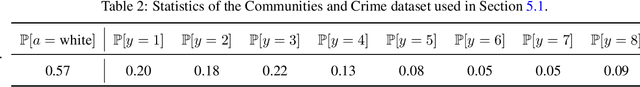
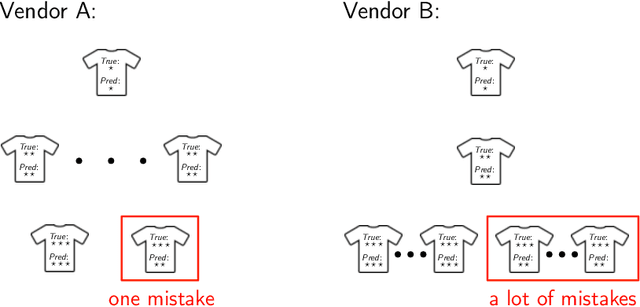
We initiate the study of fairness for ordinal regression, or ordinal classification. We adapt two fairness notions previously considered in fair ranking and propose a strategy for training a predictor that is approximately fair according to either notion. Our predictor consists of a threshold model, composed of a scoring function and a set of thresholds, and our strategy is based on a reduction to fair binary classification for learning the scoring function and local search for choosing the thresholds. We can control the extent to which we care about the accuracy vs the fairness of the predictor via a parameter. In extensive experiments we show that our strategy allows us to effectively explore the accuracy-vs-fairness trade-off and that it often compares favorably to "unfair" state-of-the-art methods for ordinal regression in that it yields predictors that are only slightly less accurate, but significantly more fair.