 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Two Heads the Same as One? Identifying Disparate Treatment in Fair Neural Networks
Apr 09, 2022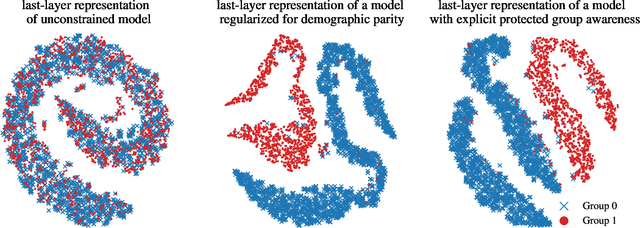
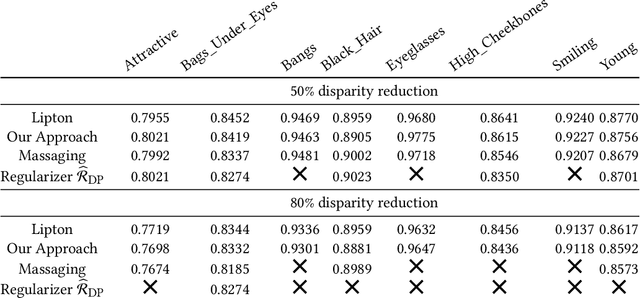
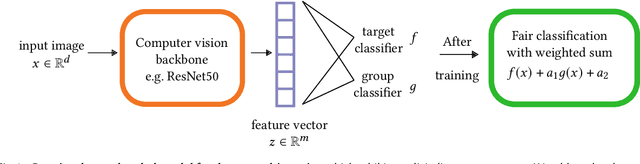
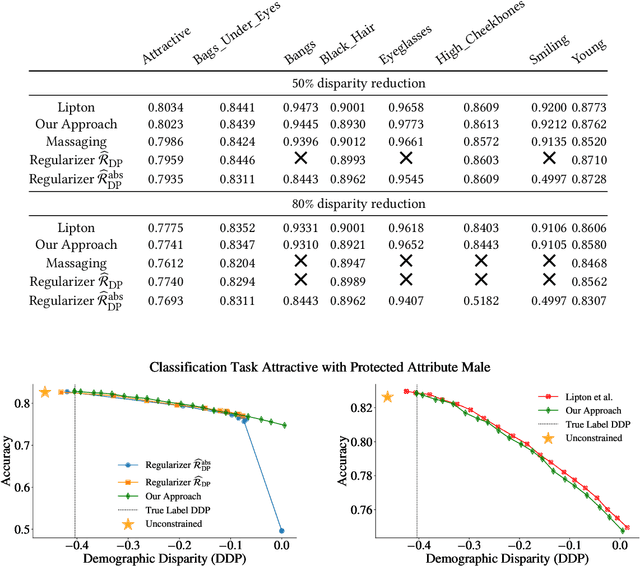
We show that deep neural networks that satisfy demographic parity do so through a form of race or gender awareness, and that the more we force a network to be fair, the more accurately we can recover race or gender from the internal state of the network. Based on this observation, we propose a simple two-stage solution for enforcing fairness. First, we train a two-headed network to predict the protected attribute (such as race or gender) alongside the original task, and second, we enforce demographic parity by taking a weighted sum of the heads. In the end, this approach creates a single-headed network with the same backbone architecture as the original network. Our approach has near identical performance compared to existing regularization-based or preprocessing methods, but has greater stability and higher accuracy where near exact demographic parity is required. To cement the relationship between these two approaches, we show that an unfair and optimally accurate classifier can be recovered by taking a weighted sum of a fair classifier and a classifier predicting the protected attribute. We use this to argue that both the fairness approaches and our explicit formulation demonstrate disparate treatment and that, consequentially, they are likely to be unlawful in a wide range of scenarios under the US law.
Leveling Down in Computer Vision: Pareto Inefficiencies in Fair Deep Classifiers
Mar 31, 2022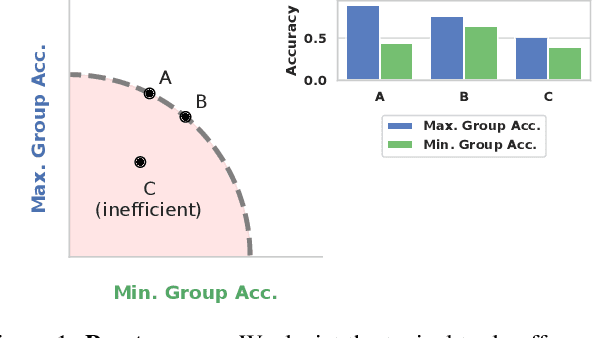
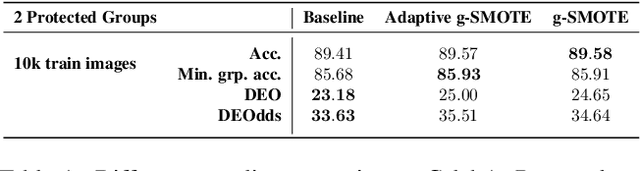
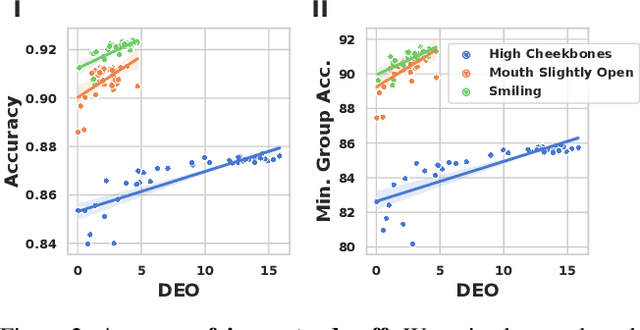
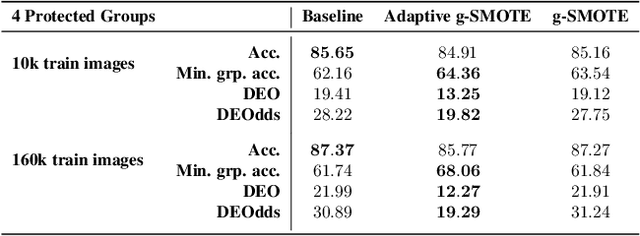
Algorithmic fairness is frequently motivated in terms of a trade-off in which overall performance is decreased so as to improve performance on disadvantaged groups where the algorithm would otherwise be less accurate. Contrary to this, we find that applying existing fairness approaches to computer vision improve fairness by degrading the performance of classifiers across all groups (with increased degradation on the best performing groups). Extending the bias-variance decomposition for classification to fairness, we theoretically explain why the majority of fairness classifiers designed for low capacity models should not be used in settings involving high-capacity models, a scenario common to computer vision. We corroborate this analysis with extensive experimental support that shows that many of the fairness heuristics used in computer vision also degrade performance on the most disadvantaged groups. Building on these insights, we propose an adaptive augmentation strategy that, uniquely, of all methods tested, improves performance for the disadvantaged groups.
Uncertainty Estimates for Ordinal Embeddings
Jun 27, 2019

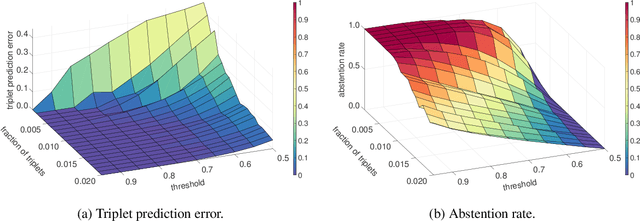
To investigate objects without a describable notion of distance, one can gather ordinal information by asking triplet comparisons of the form "Is object $x$ closer to $y$ or is $x$ closer to $z$?" In order to learn from such data, the objects are typically embedded in a Euclidean space while satisfying as many triplet comparisons as possible. In this paper, we introduce empirical uncertainty estimates for standard embedding algorithms when few noisy triplets are available, using a bootstrap and a Bayesian approach. In particular, simulations show that these estimates are well calibrated and can serve to select embedding parameters or to quantify uncertainty in scientific applications.