 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisplacement-Resistant Extensions of DPO with Nonconvex $f$-Divergences
Feb 06, 2026DPO and related algorithms align language models by directly optimizing the RLHF objective: find a policy that maximizes the Bradley-Terry reward while staying close to a reference policy through a KL divergence penalty. Previous work showed that this approach could be further generalized: the original problem remains tractable even if the KL divergence is replaced by a family of $f$-divergence with a convex generating function $f$. Our first contribution is to show that convexity of $f$ is not essential. Instead, we identify a more general condition, referred to as DPO-inducing, that precisely characterizes when the RLHF problem remains tractable. Our next contribution is to establish a second condition on $f$ that is necessary to prevent probability displacement, a known empirical phenomenon in which the probabilities of the winner and the loser responses approach zero. We refer to any $f$ that satisfies this condition as displacement-resistant. We finally focus on a specific DPO-inducing and displacement-resistant $f$, leading to our novel SquaredPO loss. Compared to DPO, this new loss offers stronger theoretical guarantees while performing competitively in practice.
Direct Preference Optimization with Rating Information: Practical Algorithms and Provable Gains
Jan 31, 2026The class of direct preference optimization (DPO) algorithms has emerged as a promising approach for solving the alignment problem in foundation models. These algorithms work with very limited feedback in the form of pairwise preferences and fine-tune models to align with these preferences without explicitly learning a reward model. While the form of feedback used by these algorithms makes the data collection process easy and relatively more accurate, its ambiguity in terms of the quality of responses could have negative implications. For example, it is not clear if a decrease (increase) in the likelihood of preferred (dispreferred) responses during the execution of these algorithms could be interpreted as a positive or negative phenomenon. In this paper, we study how to design algorithms that can leverage additional information in the form of rating gap, which informs the learner how much the chosen response is better than the rejected one. We present new algorithms that can achieve faster statistical rates than DPO in presence of accurate rating gap information. Moreover, we theoretically prove and empirically show that the performance of our algorithms is robust to inaccuracy in rating gaps. Finally, we demonstrate the solid performance of our methods in comparison to a number of DPO-style algorithms across a wide range of LLMs and evaluation benchmarks.
FisherSFT: Data-Efficient Supervised Fine-Tuning of Language Models Using Information Gain
May 20, 2025Supervised fine-tuning (SFT) is a standard approach to adapting large language models (LLMs) to new domains. In this work, we improve the statistical efficiency of SFT by selecting an informative subset of training examples. Specifically, for a fixed budget of training examples, which determines the computational cost of fine-tuning, we determine the most informative ones. The key idea in our method is to select examples that maximize information gain, measured by the Hessian of the log-likelihood of the LLM. We approximate it efficiently by linearizing the LLM at the last layer using multinomial logistic regression models. Our approach is computationally efficient, analyzable, and performs well empirically. We demonstrate this on several problems, and back our claims with both quantitative results and an LLM evaluation.
C-3DPO: Constrained Controlled Classification for Direct Preference Optimization
Feb 22, 2025Direct preference optimization (DPO)-style algorithms have emerged as a promising approach for solving the alignment problem in AI. We present a novel perspective that formulates these algorithms as implicit classification algorithms. This classification framework enables us to recover many variants of DPO-style algorithms by choosing appropriate classification labels and loss functions. We then leverage this classification framework to demonstrate that the underlying problem solved in these algorithms is under-specified, making them susceptible to probability collapse of the winner-loser responses. We address this by proposing a set of constraints designed to control the movement of probability mass between the winner and loser in the reference and target policies. Our resulting algorithm, which we call Constrained Controlled Classification DPO (\texttt{C-3DPO}), has a meaningful RLHF interpretation. By hedging against probability collapse, \texttt{C-3DPO} provides practical improvements over vanilla \texttt{DPO} when aligning several large language models using standard preference datasets.
A Proximal Operator for Inducing 2:4-Sparsity
Jan 29, 2025



Recent hardware advancements in AI Accelerators and GPUs allow to efficiently compute sparse matrix multiplications, especially when 2 out of 4 consecutive weights are set to zero. However, this so-called 2:4 sparsity usually comes at a decreased accuracy of the model. We derive a regularizer that exploits the local correlation of features to find better sparsity masks in trained models. We minimize the regularizer jointly with a local squared loss by deriving the proximal operator for which we show that it has an efficient solution in the 2:4-sparse case. After optimizing the mask, we use maskedgradient updates to further minimize the local squared loss. We illustrate our method on toy problems and apply it to pruning entire large language models up to 70B parameters. On models up to 13B we improve over previous state of the art algorithms, whilst on 70B models we match their performance.
Comparing Few to Rank Many: Active Human Preference Learning using Randomized Frank-Wolfe
Dec 27, 2024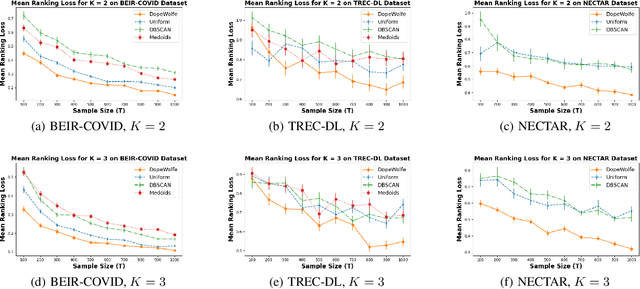

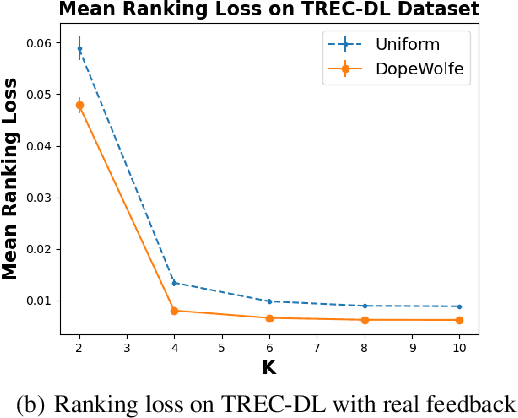
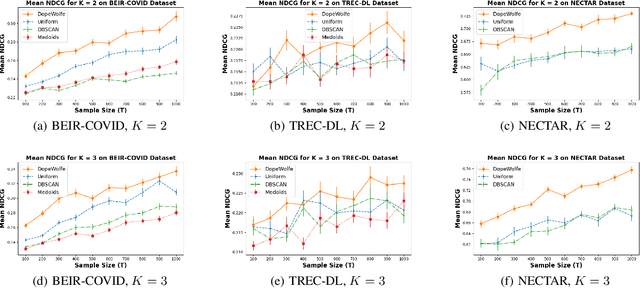
We study learning of human preferences from a limited comparison feedback. This task is ubiquitous in machine learning. Its applications such as reinforcement learning from human feedback, have been transformational. We formulate this problem as learning a Plackett-Luce model over a universe of $N$ choices from $K$-way comparison feedback, where typically $K \ll N$. Our solution is the D-optimal design for the Plackett-Luce objective. The design defines a data logging policy that elicits comparison feedback for a small collection of optimally chosen points from all ${N \choose K}$ feasible subsets. The main algorithmic challenge in this work is that even fast methods for solving D-optimal designs would have $O({N \choose K})$ time complexity. To address this issue, we propose a randomized Frank-Wolfe (FW) algorithm that solves the linear maximization sub-problems in the FW method on randomly chosen variables. We analyze the algorithm, and evaluate it empirically on synthetic and open-source NLP datasets.
Learning the Target Network in Function Space
Jun 03, 2024



We focus on the task of learning the value function in the reinforcement learning (RL) setting. This task is often solved by updating a pair of online and target networks while ensuring that the parameters of these two networks are equivalent. We propose Lookahead-Replicate (LR), a new value-function approximation algorithm that is agnostic to this parameter-space equivalence. Instead, the LR algorithm is designed to maintain an equivalence between the two networks in the function space. This value-based equivalence is obtained by employing a new target-network update. We show that LR leads to a convergent behavior in learning the value function. We also present empirical results demonstrating that LR-based target-network updates significantly improve deep RL on the Atari benchmark.
MADA: Meta-Adaptive Optimizers through hyper-gradient Descent
Jan 17, 2024



Since Adam was introduced, several novel adaptive optimizers for deep learning have been proposed. These optimizers typically excel in some tasks but may not outperform Adam uniformly across all tasks. In this work, we introduce Meta-Adaptive Optimizers (MADA), a unified optimizer framework that can generalize several known optimizers and dynamically learn the most suitable one during training. The key idea in MADA is to parameterize the space of optimizers and search through it using hyper-gradient descent. Numerical results suggest that MADA is robust against sub-optimally tuned hyper-parameters, and outperforms Adam, Lion, and Adan with their default hyper-parameters, often even with optimized hyper-parameters. We also propose AVGrad, a variant of AMSGrad where the maximum operator is replaced with averaging, and observe that it performs better within MADA. Finally, we provide a convergence analysis to show that interpolation of optimizers (specifically, AVGrad and Adam) can improve their error bounds (up to constants), hinting at an advantage for meta-optimizers.
Krylov Cubic Regularized Newton: A Subspace Second-Order Method with Dimension-Free Convergence Rate
Jan 05, 2024


Second-order optimization methods, such as cubic regularized Newton methods, are known for their rapid convergence rates; nevertheless, they become impractical in high-dimensional problems due to their substantial memory requirements and computational costs. One promising approach is to execute second-order updates within a lower-dimensional subspace, giving rise to subspace second-order methods. However, the majority of existing subspace second-order methods randomly select subspaces, consequently resulting in slower convergence rates depending on the problem's dimension $d$. In this paper, we introduce a novel subspace cubic regularized Newton method that achieves a dimension-independent global convergence rate of ${O}\left(\frac{1}{mk}+\frac{1}{k^2}\right)$ for solving convex optimization problems. Here, $m$ represents the subspace dimension, which can be significantly smaller than $d$. Instead of adopting a random subspace, our primary innovation involves performing the cubic regularized Newton update within the Krylov subspace associated with the Hessian and the gradient of the objective function. This result marks the first instance of a dimension-independent convergence rate for a subspace second-order method. Furthermore, when specific spectral conditions of the Hessian are met, our method recovers the convergence rate of a full-dimensional cubic regularized Newton method. Numerical experiments show our method converges faster than existing random subspace methods, especially for high-dimensional problems.
TAIL: Task-specific Adapters for Imitation Learning with Large Pretrained Models
Oct 09, 2023



The full potential of large pretrained models remains largely untapped in control domains like robotics. This is mainly because of the scarcity of data and the computational challenges associated with training or fine-tuning these large models for such applications. Prior work mainly emphasizes effective pretraining of large models for decision-making, with little exploration into how to perform data-efficient continual adaptation of these models for new tasks. Recognizing these constraints, we introduce TAIL (Task-specific Adapters for Imitation Learning), a framework for efficient adaptation to new control tasks. Inspired by recent advancements in parameter-efficient fine-tuning in language domains, we explore efficient fine-tuning techniques -- e.g., Bottleneck Adapters, P-Tuning, and Low-Rank Adaptation (LoRA) -- in TAIL to adapt large pretrained models for new tasks with limited demonstration data. Our extensive experiments in large-scale language-conditioned manipulation tasks comparing prevalent parameter-efficient fine-tuning techniques and adaptation baselines suggest that TAIL with LoRA can achieve the best post-adaptation performance with only 1\% of the trainable parameters of full fine-tuning, while avoiding catastrophic forgetting and preserving adaptation plasticity in continual learning settings.