 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPIRE: Conditional Personalization for Federated Diffusion Generative Models
Jun 14, 2025Recent advances in diffusion models have revolutionized generative AI, but their sheer size makes on device personalization, and thus effective federated learning (FL), infeasible. We propose Shared Backbone Personal Identity Representation Embeddings (SPIRE), a framework that casts per client diffusion based generation as conditional generation in FL. SPIRE factorizes the network into (i) a high capacity global backbone that learns a population level score function and (ii) lightweight, learnable client embeddings that encode local data statistics. This separation enables parameter efficient finetuning that touches $\leq 0.01\%$ of weights. We provide the first theoretical bridge between conditional diffusion training and maximum likelihood estimation in Gaussian mixture models. For a two component mixture we prove that gradient descent on the DDPM with respect to mixing weights loss recovers the optimal mixing weights and enjoys dimension free error bounds. Our analysis also hints at how client embeddings act as biases that steer a shared score network toward personalized distributions. Empirically, SPIRE matches or surpasses strong baselines during collaborative pretraining, and vastly outperforms them when adapting to unseen clients, reducing Kernel Inception Distance while updating only hundreds of parameters. SPIRE further mitigates catastrophic forgetting and remains robust across finetuning learning rate and epoch choices.
Stochastic Rounding for LLM Training: Theory and Practice
Feb 27, 2025



As the parameters of Large Language Models (LLMs) have scaled to hundreds of billions, the demand for efficient training methods -- balancing faster computation and reduced memory usage without sacrificing accuracy -- has become more critical than ever. In recent years, various mixed precision strategies, which involve different precision levels for optimization components, have been proposed to increase training speed with minimal accuracy degradation. However, these strategies often require manual adjustments and lack theoretical justification. In this work, we leverage stochastic rounding (SR) to address numerical errors of training with low-precision representation. We provide theoretical analyses of implicit regularization and convergence under the Adam optimizer when SR is utilized. With the insights from these analyses, we extend previous BF16 + SR strategy to be used in distributed settings, enhancing the stability and performance for large scale training. Empirical results from pre-training models with up to 6.7B parameters, for the first time, demonstrate that our BF16 with SR strategy outperforms (BF16, FP32) mixed precision strategies, achieving better validation perplexity, up to $1.54\times$ higher throughput, and $30\%$ less memory usage.
Hierarchical Bayes Approach to Personalized Federated Unsupervised Learning
Feb 25, 2024Statistical heterogeneity of clients' local data is an important characteristic in federated learning, motivating personalized algorithms tailored to the local data statistics. Though there has been a plethora of algorithms proposed for personalized supervised learning, discovering the structure of local data through personalized unsupervised learning is less explored. We initiate a systematic study of such personalized unsupervised learning by developing algorithms based on optimization criteria inspired by a hierarchical Bayesian statistical framework. We develop adaptive algorithms that discover the balance between using limited local data and collaborative information. We do this in the context of two unsupervised learning tasks: personalized dimensionality reduction and personalized diffusion models. We develop convergence analyses for our adaptive algorithms which illustrate the dependence on problem parameters (e.g., heterogeneity, local sample size). We also develop a theoretical framework for personalized diffusion models, which shows the benefits of collaboration even under heterogeneity. We finally evaluate our proposed algorithms using synthetic and real data, demonstrating the effective sample amplification for personalized tasks, induced through collaboration, despite data heterogeneity.
MADA: Meta-Adaptive Optimizers through hyper-gradient Descent
Jan 17, 2024



Since Adam was introduced, several novel adaptive optimizers for deep learning have been proposed. These optimizers typically excel in some tasks but may not outperform Adam uniformly across all tasks. In this work, we introduce Meta-Adaptive Optimizers (MADA), a unified optimizer framework that can generalize several known optimizers and dynamically learn the most suitable one during training. The key idea in MADA is to parameterize the space of optimizers and search through it using hyper-gradient descent. Numerical results suggest that MADA is robust against sub-optimally tuned hyper-parameters, and outperforms Adam, Lion, and Adan with their default hyper-parameters, often even with optimized hyper-parameters. We also propose AVGrad, a variant of AMSGrad where the maximum operator is replaced with averaging, and observe that it performs better within MADA. Finally, we provide a convergence analysis to show that interpolation of optimizers (specifically, AVGrad and Adam) can improve their error bounds (up to constants), hinting at an advantage for meta-optimizers.
A Generative Framework for Personalized Learning and Estimation: Theory, Algorithms, and Privacy
Jul 05, 2022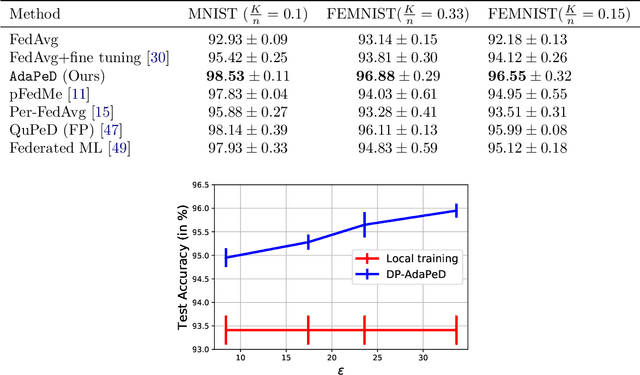
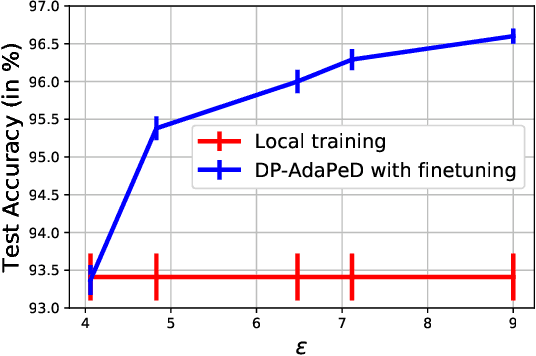
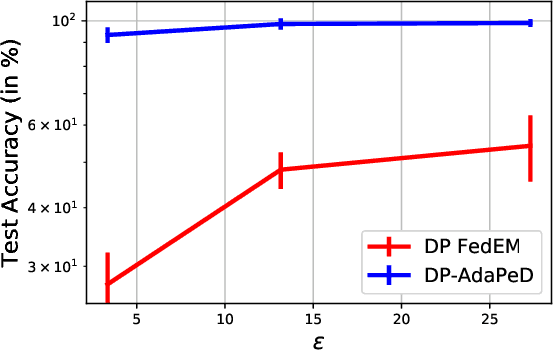
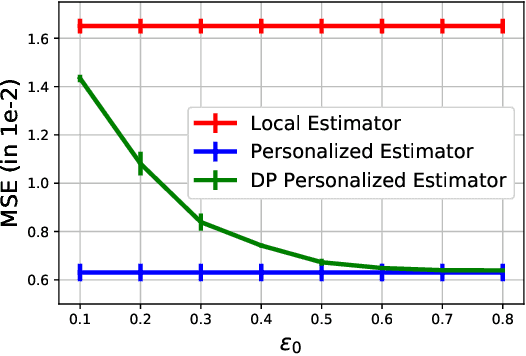
A distinguishing characteristic of federated learning is that the (local) client data could have statistical heterogeneity. This heterogeneity has motivated the design of personalized learning, where individual (personalized) models are trained, through collaboration. There have been various personalization methods proposed in literature, with seemingly very different forms and methods ranging from use of a single global model for local regularization and model interpolation, to use of multiple global models for personalized clustering, etc. In this work, we begin with a generative framework that could potentially unify several different algorithms as well as suggest new algorithms. We apply our generative framework to personalized estimation, and connect it to the classical empirical Bayes' methodology. We develop private personalized estimation under this framework. We then use our generative framework for learning, which unifies several known personalized FL algorithms and also suggests new ones; we propose and study a new algorithm AdaPeD based on a Knowledge Distillation, which numerically outperforms several known algorithms. We also develop privacy for personalized learning methods with guarantees for user-level privacy and composition. We numerically evaluate the performance as well as the privacy for both the estimation and learning problems, demonstrating the advantages of our proposed methods.
QuPeD: Quantized Personalization via Distillation with Applications to Federated Learning
Jul 29, 2021
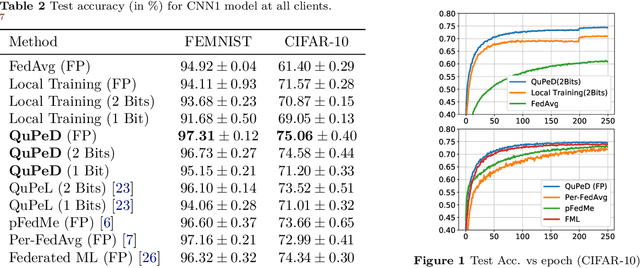

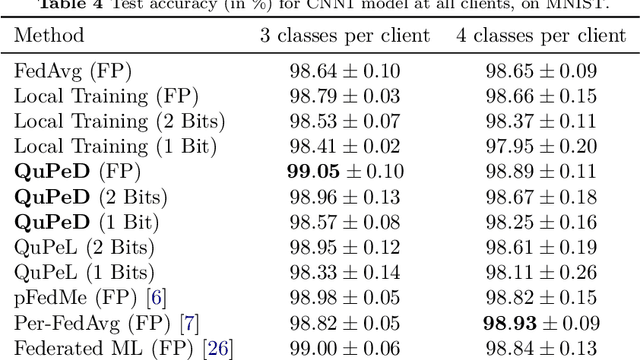
Traditionally, federated learning (FL) aims to train a single global model while collaboratively using multiple clients and a server. Two natural challenges that FL algorithms face are heterogeneity in data across clients and collaboration of clients with {\em diverse resources}. In this work, we introduce a \textit{quantized} and \textit{personalized} FL algorithm QuPeD that facilitates collective (personalized model compression) training via \textit{knowledge distillation} (KD) among clients who have access to heterogeneous data and resources. For personalization, we allow clients to learn \textit{compressed personalized models} with different quantization parameters and model dimensions/structures. Towards this, first we propose an algorithm for learning quantized models through a relaxed optimization problem, where quantization values are also optimized over. When each client participating in the (federated) learning process has different requirements for the compressed model (both in model dimension and precision), we formulate a compressed personalization framework by introducing knowledge distillation loss for local client objectives collaborating through a global model. We develop an alternating proximal gradient update for solving this compressed personalization problem, and analyze its convergence properties. Numerically, we validate that QuPeD outperforms competing personalized FL methods, FedAvg, and local training of clients in various heterogeneous settings.
QuPeL: Quantized Personalization with Applications to Federated Learning
Feb 23, 2021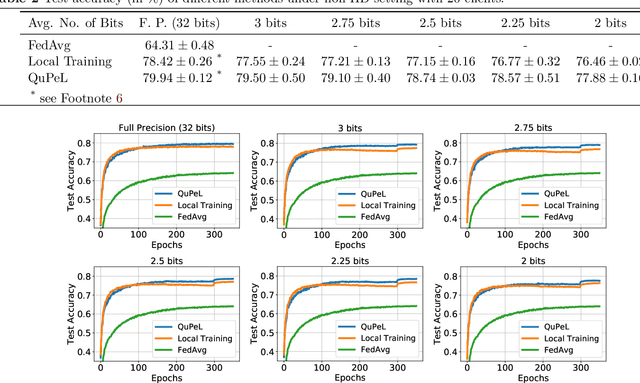
Traditionally, federated learning (FL) aims to train a single global model while collaboratively using multiple clients and a server. Two natural challenges that FL algorithms face are heterogeneity in data across clients and collaboration of clients with {\em diverse resources}. In this work, we introduce a \textit{quantized} and \textit{personalized} FL algorithm QuPeL that facilitates collective training with heterogeneous clients while respecting resource diversity. For personalization, we allow clients to learn \textit{compressed personalized models} with different quantization parameters depending on their resources. Towards this, first we propose an algorithm for learning quantized models through a relaxed optimization problem, where quantization values are also optimized over. When each client participating in the (federated) learning process has different requirements of the quantized model (both in value and precision), we formulate a quantized personalization framework by introducing a penalty term for local client objectives against a globally trained model to encourage collaboration. We develop an alternating proximal gradient update for solving this quantized personalization problem, and we analyze its convergence properties. Numerically, we show that optimizing over the quantization levels increases the performance and we validate that QuPeL outperforms both FedAvg and local training of clients in a heterogeneous setting.