 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen LLMs get significantly worse: A statistical approach to detect model degradations
Feb 09, 2026Minimizing the inference cost and latency of foundation models has become a crucial area of research. Optimization approaches include theoretically lossless methods and others without accuracy guarantees like quantization. In all of these cases it is crucial to ensure that the model quality has not degraded. However, even at temperature zero, model generations are not necessarily robust even to theoretically lossless model optimizations due to numerical errors. We thus require statistical tools to decide whether a finite-sample accuracy deviation is an evidence of a model's degradation or whether it can be attributed to (harmless) noise in the evaluation. We propose a statistically sound hypothesis testing framework based on McNemar's test allowing to efficiently detect model degradations, while guaranteeing a controlled rate of false positives. The crucial insight is that we have to confront the model scores on each sample, rather than aggregated on the task level. Furthermore, we propose three approaches to aggregate accuracy estimates across multiple benchmarks into a single decision. We provide an implementation on top of the largely adopted open source LM Evaluation Harness and provide a case study illustrating that the method correctly flags degraded models, while not flagging model optimizations that are provably lossless. We find that with our tests even empirical accuracy degradations of 0.3% can be confidently attributed to actual degradations rather than noise.
* https://openreview.net/forum?id=cM3gsqEI4K
A Proximal Operator for Inducing 2:4-Sparsity
Jan 29, 2025



Recent hardware advancements in AI Accelerators and GPUs allow to efficiently compute sparse matrix multiplications, especially when 2 out of 4 consecutive weights are set to zero. However, this so-called 2:4 sparsity usually comes at a decreased accuracy of the model. We derive a regularizer that exploits the local correlation of features to find better sparsity masks in trained models. We minimize the regularizer jointly with a local squared loss by deriving the proximal operator for which we show that it has an efficient solution in the 2:4-sparse case. After optimizing the mask, we use maskedgradient updates to further minimize the local squared loss. We illustrate our method on toy problems and apply it to pruning entire large language models up to 70B parameters. On models up to 13B we improve over previous state of the art algorithms, whilst on 70B models we match their performance.
LLM-Rank: A Graph Theoretical Approach to Pruning Large Language Models
Oct 17, 2024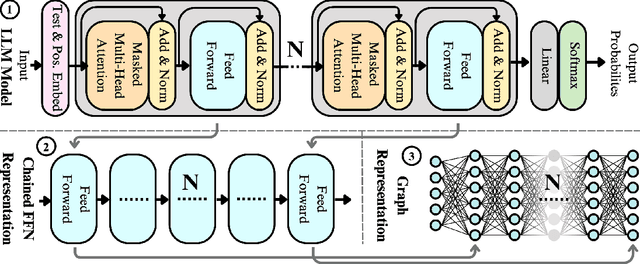

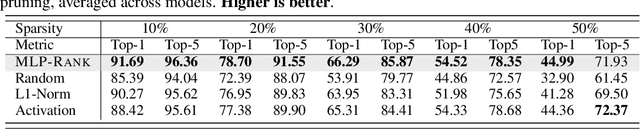
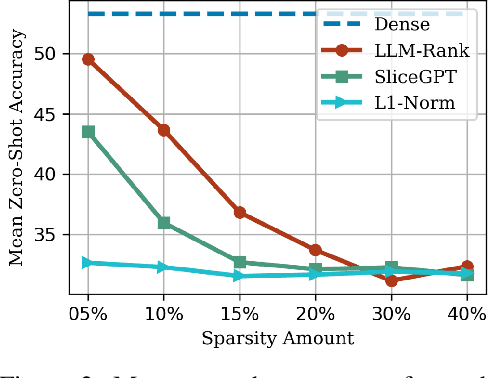
The evolving capabilities of large language models are accompanied by growing sizes and deployment costs, necessitating effective inference optimisation techniques. We propose a novel pruning method utilising centrality measures from graph theory, reducing both the computational requirements and the memory footprint of these models. Specifically, we devise a method for creating a weighted directed acyclical graph representation of multilayer perceptrons to which we apply a modified version of the weighted PageRank centrality measure to compute node importance scores. In combination with uniform pruning this leads to structured sparsity. We call this pruning method MLPRank. Furthermore we introduce an extension to decoder-only transformer models and call it LLMRank. For both variants we demonstrate a strong performance. With MLPRank on average leading to 6.09 % higher accuracy retention than three popular baselines and 13.42 % with LLMRank compared to two popular baselines.
Inference Optimization of Foundation Models on AI Accelerators
Jul 12, 2024



Powerful foundation models, including large language models (LLMs), with Transformer architectures have ushered in a new era of Generative AI across various industries. Industry and research community have witnessed a large number of new applications, based on those foundation models. Such applications include question and answer, customer services, image and video generation, and code completions, among others. However, as the number of model parameters reaches to hundreds of billions, their deployment incurs prohibitive inference costs and high latency in real-world scenarios. As a result, the demand for cost-effective and fast inference using AI accelerators is ever more higher. To this end, our tutorial offers a comprehensive discussion on complementary inference optimization techniques using AI accelerators. Beginning with an overview of basic Transformer architectures and deep learning system frameworks, we deep dive into system optimization techniques for fast and memory-efficient attention computations and discuss how they can be implemented efficiently on AI accelerators. Next, we describe architectural elements that are key for fast transformer inference. Finally, we examine various model compression and fast decoding strategies in the same context.
Evaluating the Fairness of Discriminative Foundation Models in Computer Vision
Oct 18, 2023We propose a novel taxonomy for bias evaluation of discriminative foundation models, such as Contrastive Language-Pretraining (CLIP), that are used for labeling tasks. We then systematically evaluate existing methods for mitigating bias in these models with respect to our taxonomy. Specifically, we evaluate OpenAI's CLIP and OpenCLIP models for key applications, such as zero-shot classification, image retrieval and image captioning. We categorize desired behaviors based around three axes: (i) if the task concerns humans; (ii) how subjective the task is (i.e., how likely it is that people from a diverse range of backgrounds would agree on a labeling); and (iii) the intended purpose of the task and if fairness is better served by impartiality (i.e., making decisions independent of the protected attributes) or representation (i.e., making decisions to maximize diversity). Finally, we provide quantitative fairness evaluations for both binary-valued and multi-valued protected attributes over ten diverse datasets. We find that fair PCA, a post-processing method for fair representations, works very well for debiasing in most of the aforementioned tasks while incurring only minor loss of performance. However, different debiasing approaches vary in their effectiveness depending on the task. Hence, one should choose the debiasing approach depending on the specific use case.
Meaningful Causal Aggregation and Paradoxical Confounding
Apr 23, 2023In aggregated variables the impact of interventions is typically ill-defined because different micro-realizations of the same macro-intervention can result in different changes of downstream macro-variables. We show that this ill-definedness of causality on aggregated variables can turn unconfounded causal relations into confounded ones and vice versa, depending on the respective micro-realization. We argue that it is practically infeasible to only use aggregated causal systems when we are free from this ill-definedness. Instead, we need to accept that macro causal relations are typically defined only with reference to the micro states. On the positive side, we show that cause-effect relations can be aggregated when the macro interventions are such that the distribution of micro states is the same as in the observational distribution and also discuss generalizations of this observation.
Explaining the root causes of unit-level changes
Jun 26, 2022


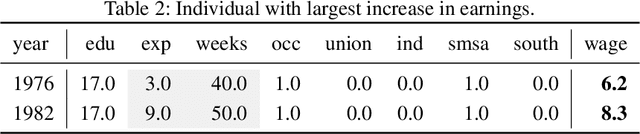
Existing methods of explainable AI and interpretable ML cannot explain change in the values of an output variable for a statistical unit in terms of the change in the input values and the change in the "mechanism" (the function transforming input to output). We propose two methods based on counterfactuals for explaining unit-level changes at various input granularities using the concept of Shapley values from game theory. These methods satisfy two key axioms desirable for any unit-level change attribution method. Through simulations, we study the reliability and the scalability of the proposed methods. We get sensible results from a case study on identifying the drivers of the change in the earnings for individuals in the US.
DoWhy-GCM: An extension of DoWhy for causal inference in graphical causal models
Jun 14, 2022
We introduce DoWhy-GCM, an extension of the DoWhy Python library, that leverages graphical causal models. Unlike existing causality libraries, which mainly focus on effect estimation questions, with DoWhy-GCM, users can ask a wide range of additional causal questions, such as identifying the root causes of outliers and distributional changes, causal structure learning, attributing causal influences, and diagnosis of causal structures. To this end, DoWhy-GCM users first model cause-effect relations between variables in a system under study through a graphical causal model, fit the causal mechanisms of variables next, and then ask the causal question. All these steps take only a few lines of code in DoWhy-GCM. The library is available at https://github.com/py-why/dowhy.
Why did the distribution change?
Feb 26, 2021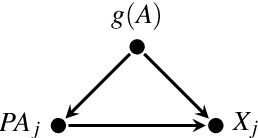
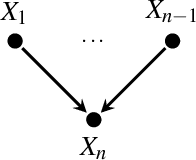
We describe a formal approach based on graphical causal models to identify the "root causes" of the change in the probability distribution of variables. After factorizing the joint distribution into conditional distributions of each variable, given its parents (the "causal mechanisms"), we attribute the change to changes of these causal mechanisms. This attribution analysis accounts for the fact that mechanisms often change independently and sometimes only some of them change. Through simulations, we study the performance of our distribution change attribution method. We then present a real-world case study identifying the drivers of the difference in the income distribution between men and women.
Discovering Reliable Causal Rules
Sep 08, 2020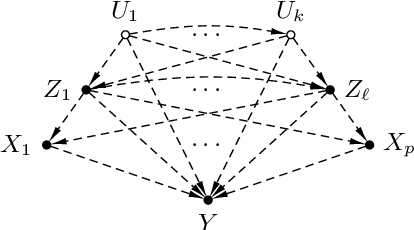
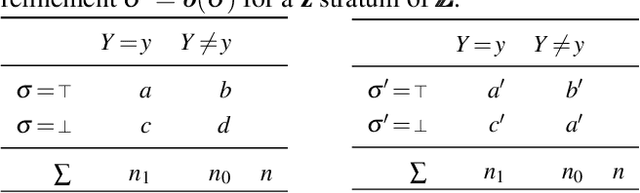
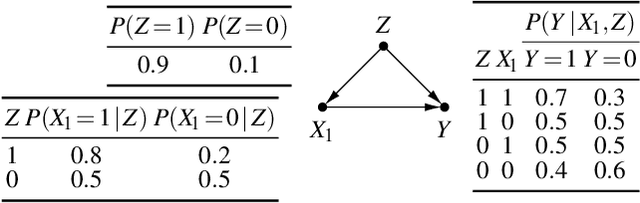
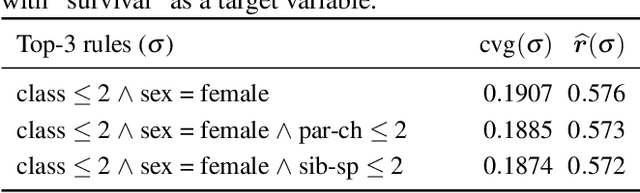
We study the problem of deriving policies, or rules, that when enacted on a complex system, cause a desired outcome. Absent the ability to perform controlled experiments, such rules have to be inferred from past observations of the system's behaviour. This is a challenging problem for two reasons: First, observational effects are often unrepresentative of the underlying causal effect because they are skewed by the presence of confounding factors. Second, naive empirical estimations of a rule's effect have a high variance, and, hence, their maximisation can lead to random results. To address these issues, first we measure the causal effect of a rule from observational data---adjusting for the effect of potential confounders. Importantly, we provide a graphical criteria under which causal rule discovery is possible. Moreover, to discover reliable causal rules from a sample, we propose a conservative and consistent estimator of the causal effect, and derive an efficient and exact algorithm that maximises the estimator. On synthetic data, the proposed estimator converges faster to the ground truth than the naive estimator and recovers relevant causal rules even at small sample sizes. Extensive experiments on a variety of real-world datasets show that the proposed algorithm is efficient and discovers meaningful rules.