 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Rank: A Graph Theoretical Approach to Pruning Large Language Models
Paper and Code
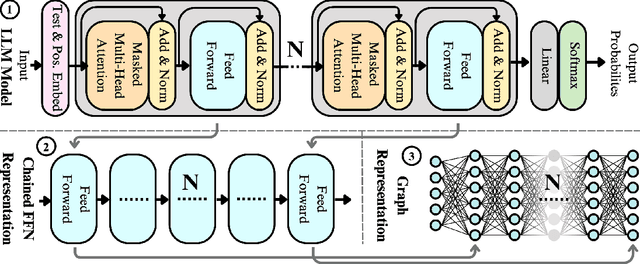

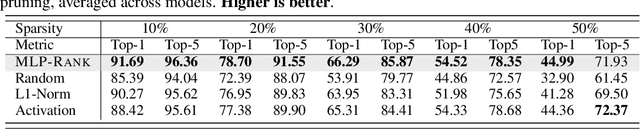
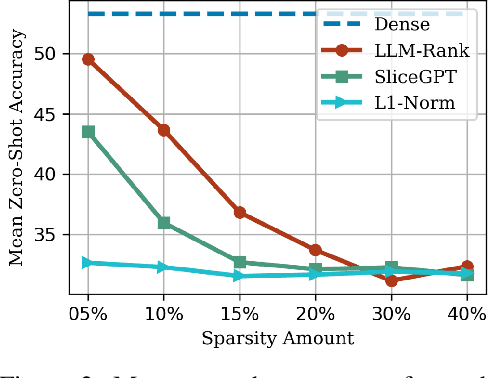
The evolving capabilities of large language models are accompanied by growing sizes and deployment costs, necessitating effective inference optimisation techniques. We propose a novel pruning method utilising centrality measures from graph theory, reducing both the computational requirements and the memory footprint of these models. Specifically, we devise a method for creating a weighted directed acyclical graph representation of multilayer perceptrons to which we apply a modified version of the weighted PageRank centrality measure to compute node importance scores. In combination with uniform pruning this leads to structured sparsity. We call this pruning method MLPRank. Furthermore we introduce an extension to decoder-only transformer models and call it LLMRank. For both variants we demonstrate a strong performance. With MLPRank on average leading to 6.09 % higher accuracy retention than three popular baselines and 13.42 % with LLMRank compared to two popular baselines.