 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Fairness of Discriminative Foundation Models in Computer Vision
Oct 18, 2023We propose a novel taxonomy for bias evaluation of discriminative foundation models, such as Contrastive Language-Pretraining (CLIP), that are used for labeling tasks. We then systematically evaluate existing methods for mitigating bias in these models with respect to our taxonomy. Specifically, we evaluate OpenAI's CLIP and OpenCLIP models for key applications, such as zero-shot classification, image retrieval and image captioning. We categorize desired behaviors based around three axes: (i) if the task concerns humans; (ii) how subjective the task is (i.e., how likely it is that people from a diverse range of backgrounds would agree on a labeling); and (iii) the intended purpose of the task and if fairness is better served by impartiality (i.e., making decisions independent of the protected attributes) or representation (i.e., making decisions to maximize diversity). Finally, we provide quantitative fairness evaluations for both binary-valued and multi-valued protected attributes over ten diverse datasets. We find that fair PCA, a post-processing method for fair representations, works very well for debiasing in most of the aforementioned tasks while incurring only minor loss of performance. However, different debiasing approaches vary in their effectiveness depending on the task. Hence, one should choose the debiasing approach depending on the specific use case.
Loss-Aversively Fair Classification
May 10, 2021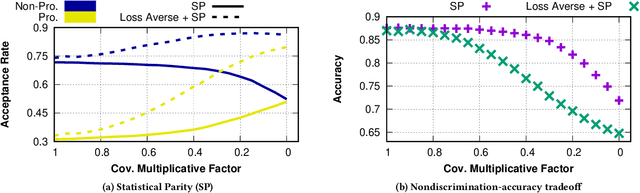
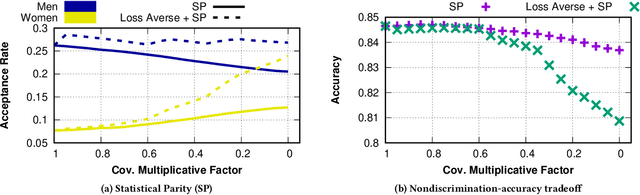
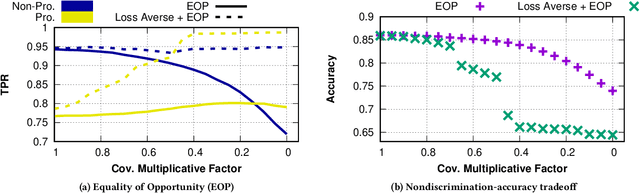
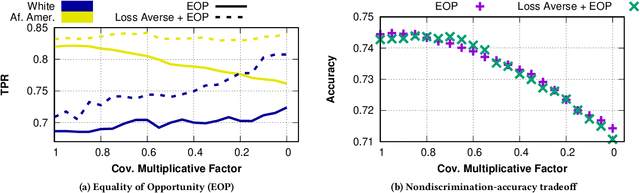
The use of algorithmic (learning-based) decision making in scenarios that affect human lives has motivated a number of recent studies to investigate such decision making systems for potential unfairness, such as discrimination against subjects based on their sensitive features like gender or race. However, when judging the fairness of a newly designed decision making system, these studies have overlooked an important influence on people's perceptions of fairness, which is how the new algorithm changes the status quo, i.e., decisions of the existing decision making system. Motivated by extensive literature in behavioral economics and behavioral psychology (prospect theory), we propose a notion of fair updates that we refer to as loss-averse updates. Loss-averse updates constrain the updates to yield improved (more beneficial) outcomes to subjects compared to the status quo. We propose tractable proxy measures that would allow this notion to be incorporated in the training of a variety of linear and non-linear classifiers. We show how our proxy measures can be combined with existing measures for training nondiscriminatory classifiers. Our evaluation using synthetic and real-world datasets demonstrates that the proposed proxy measures are effective for their desired tasks.
* 8 pages, Accepted at AIES 2019
Accounting for Model Uncertainty in Algorithmic Discrimination
May 10, 2021



Traditional approaches to ensure group fairness in algorithmic decision making aim to equalize ``total'' error rates for different subgroups in the population. In contrast, we argue that the fairness approaches should instead focus only on equalizing errors arising due to model uncertainty (a.k.a epistemic uncertainty), caused due to lack of knowledge about the best model or due to lack of data. In other words, our proposal calls for ignoring the errors that occur due to uncertainty inherent in the data, i.e., aleatoric uncertainty. We draw a connection between predictive multiplicity and model uncertainty and argue that the techniques from predictive multiplicity could be used to identify errors made due to model uncertainty. We propose scalable convex proxies to come up with classifiers that exhibit predictive multiplicity and empirically show that our methods are comparable in performance and up to four orders of magnitude faster than the current state-of-the-art. We further propose methods to achieve our goal of equalizing group error rates arising due to model uncertainty in algorithmic decision making and demonstrate the effectiveness of these methods using synthetic and real-world datasets.