 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference Optimization of Foundation Models on AI Accelerators
Jul 12, 2024



Powerful foundation models, including large language models (LLMs), with Transformer architectures have ushered in a new era of Generative AI across various industries. Industry and research community have witnessed a large number of new applications, based on those foundation models. Such applications include question and answer, customer services, image and video generation, and code completions, among others. However, as the number of model parameters reaches to hundreds of billions, their deployment incurs prohibitive inference costs and high latency in real-world scenarios. As a result, the demand for cost-effective and fast inference using AI accelerators is ever more higher. To this end, our tutorial offers a comprehensive discussion on complementary inference optimization techniques using AI accelerators. Beginning with an overview of basic Transformer architectures and deep learning system frameworks, we deep dive into system optimization techniques for fast and memory-efficient attention computations and discuss how they can be implemented efficiently on AI accelerators. Next, we describe architectural elements that are key for fast transformer inference. Finally, we examine various model compression and fast decoding strategies in the same context.
Bifurcated Attention for Single-Context Large-Batch Sampling
Mar 13, 2024In our study, we present bifurcated attention, a method developed for language model inference in single-context batch sampling contexts. This approach aims to reduce redundant memory IO costs, a significant factor in latency for high batch sizes and long context lengths. Bifurcated attention achieves this by dividing the attention mechanism during incremental decoding into two distinct GEMM operations, focusing on the KV cache from prefill and the decoding process. This method ensures precise computation and maintains the usual computational load (FLOPs) of standard attention mechanisms, but with reduced memory IO. Bifurcated attention is also compatible with multi-query attention mechanism known for reduced memory IO for KV cache, further enabling higher batch size and context length. The resulting efficiency leads to lower latency, improving suitability for real-time applications, e.g., enabling massively-parallel answer generation without substantially increasing latency, enhancing performance when integrated with postprocessing techniques such as reranking.
Driving Scene Perception Network: Real-time Joint Detection, Depth Estimation and Semantic Segmentation
Mar 10, 2018

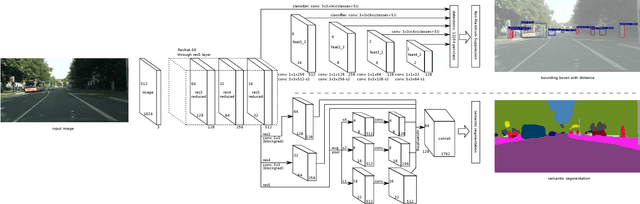

As the demand for enabling high-level autonomous driving has increased in recent years and visual perception is one of the critical features to enable fully autonomous driving, in this paper, we introduce an efficient approach for simultaneous object detection, depth estimation and pixel-level semantic segmentation using a shared convolutional architecture. The proposed network model, which we named Driving Scene Perception Network (DSPNet), uses multi-level feature maps and multi-task learning to improve the accuracy and efficiency of object detection, depth estimation and image segmentation tasks from a single input image. Hence, the resulting network model uses less than 850 MiB of GPU memory and achieves 14.0 fps on NVIDIA GeForce GTX 1080 with a 1024x512 input image, and both precision and efficiency have been improved over combination of single tasks.