 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEE-Few: Seed, Expand and Entail for Few-shot Named Entity Recognition
Oct 11, 2022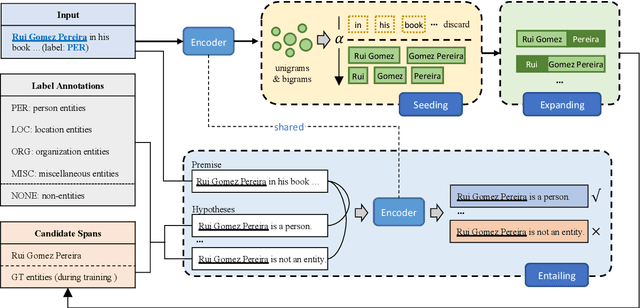
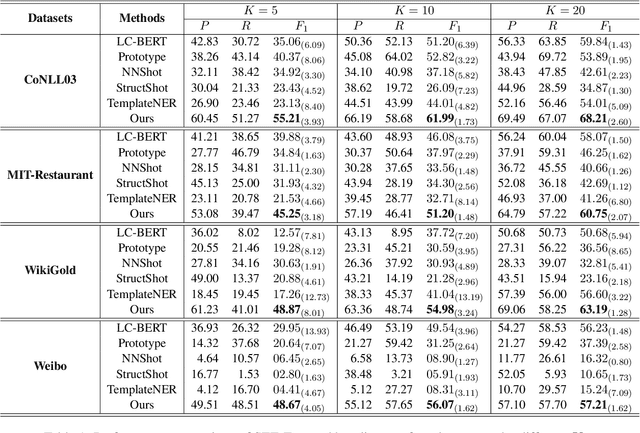
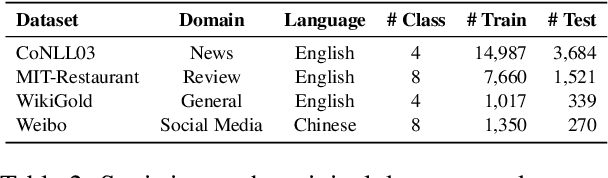
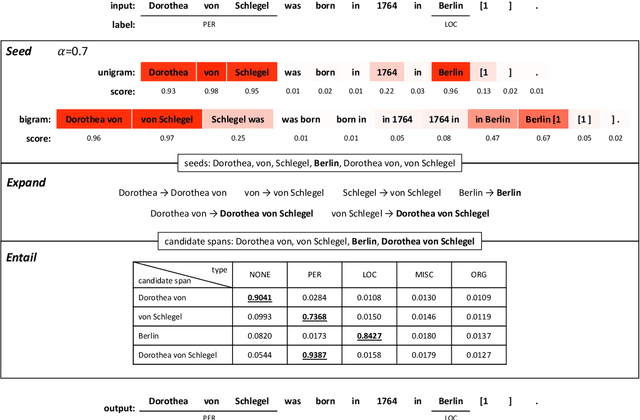
Few-shot named entity recognition (NER) aims at identifying named entities based on only few labeled instances. Current few-shot NER methods focus on leveraging existing datasets in the rich-resource domains which might fail in a training-from-scratch setting where no source-domain data is used. To tackle training-from-scratch setting, it is crucial to make full use of the annotation information (the boundaries and entity types). Therefore, in this paper, we propose a novel multi-task (Seed, Expand and Entail) learning framework, SEE-Few, for Few-shot NER without using source domain data. The seeding and expanding modules are responsible for providing as accurate candidate spans as possible for the entailing module. The entailing module reformulates span classification as a textual entailment task, leveraging both the contextual clues and entity type information. All the three modules share the same text encoder and are jointly learned. Experimental results on four benchmark datasets under the training-from-scratch setting show that the proposed method outperformed state-of-the-art few-shot NER methods with a large margin. Our code is available at \url{https://github.com/unveiled-the-red-hat/SEE-Few}.
Enforcing Deterministic Constraints on Generative Adversarial Networks for Emulating Physical Systems
Nov 15, 2019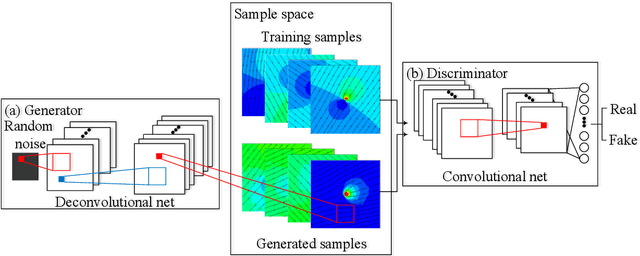
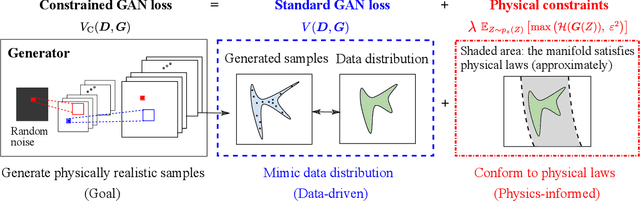

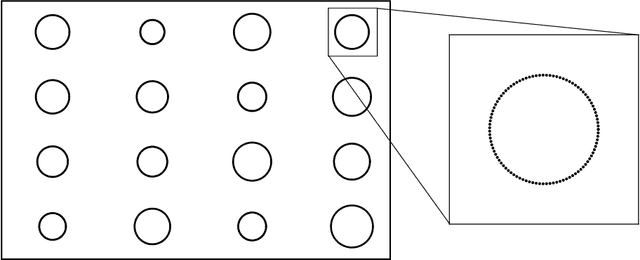
Generative adversarial networks (GANs) are initially proposed to generate images by learning from a large number of samples. Recently, GANs have been used to emulate complex physical systems such as turbulent flows. However, a critical question must be answered before GANs can be considered trusted emulators for physical systems: do GANs-generated samples conform to the various physical constraints? These include both deterministic constraints (e.g., conservation laws) and statistical constraints (e.g., energy spectrum in turbulent flows). The latter has been studied in a companion paper (Wu et al. 2019. Enforcing statistical constraints in generative adversarial networks for modeling chaotic dynamical systems. arxiv:1905.06841). In the present work, we enforce deterministic yet approximate constraints on GANs by incorporating them into the loss function of the generator. We evaluate the performance of physics-constrained GANs on two representative tasks with geometrical constraints (generating points on circles) and differential constraints (generating divergence-free flow velocity fields), respectively. In both cases, the constrained GANs produced samples that precisely conform to the underlying constraints, even though the constraints are only enforced approximately. More importantly, the imposed constraints significantly accelerate the convergence and improve the robustness in the training. These improvements are noteworthy, as the convergence and robustness are two well-known obstacles in the training of GANs.
Driving Scene Perception Network: Real-time Joint Detection, Depth Estimation and Semantic Segmentation
Mar 10, 2018

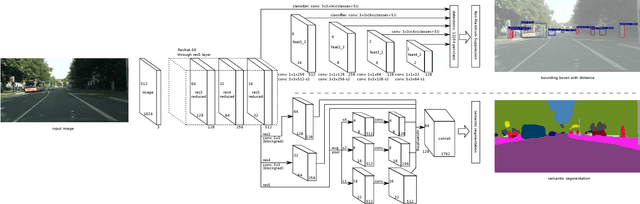

As the demand for enabling high-level autonomous driving has increased in recent years and visual perception is one of the critical features to enable fully autonomous driving, in this paper, we introduce an efficient approach for simultaneous object detection, depth estimation and pixel-level semantic segmentation using a shared convolutional architecture. The proposed network model, which we named Driving Scene Perception Network (DSPNet), uses multi-level feature maps and multi-task learning to improve the accuracy and efficiency of object detection, depth estimation and image segmentation tasks from a single input image. Hence, the resulting network model uses less than 850 MiB of GPU memory and achieves 14.0 fps on NVIDIA GeForce GTX 1080 with a 1024x512 input image, and both precision and efficiency have been improved over combination of single tasks.