 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Vision Replace Text in Working Memory? Evidence from Spatial n-Back in Vision-Language Models
Feb 04, 2026Working memory is a central component of intelligent behavior, providing a dynamic workspace for maintaining and updating task-relevant information. Recent work has used n-back tasks to probe working-memory-like behavior in large language models, but it is unclear whether the same probe elicits comparable computations when information is carried in a visual rather than textual code in vision-language models. We evaluate Qwen2.5 and Qwen2.5-VL on a controlled spatial n-back task presented as matched text-rendered or image-rendered grids. Across conditions, models show reliably higher accuracy and d' with text than with vision. To interpret these differences at the process level, we use trial-wise log-probability evidence and find that nominal 2/3-back often fails to reflect the instructed lag and instead aligns with a recency-locked comparison. We further show that grid size alters recent-repeat structure in the stimulus stream, thereby changing interference and error patterns. These results motivate computation-sensitive interpretations of multimodal working memory.
When KV Cache Reuse Fails in Multi-Agent Systems: Cross-Candidate Interaction is Crucial for LLM Judges
Jan 13, 2026Multi-agent LLM systems routinely generate multiple candidate responses that are aggregated by an LLM judge. To reduce the dominant prefill cost in such pipelines, recent work advocates KV cache reuse across partially shared contexts and reports substantial speedups for generation agents. In this work, we show that these efficiency gains do not transfer uniformly to judge-centric inference. Across GSM8K, MMLU, and HumanEval, we find that reuse strategies that are effective for execution agents can severely perturb judge behavior: end-task accuracy may appear stable, yet the judge's selection becomes highly inconsistent with dense prefill. We quantify this risk using Judge Consistency Rate (JCR) and provide diagnostics showing that reuse systematically weakens cross-candidate attention, especially for later candidate blocks. Our ablation further demonstrates that explicit cross-candidate interaction is crucial for preserving dense-prefill decisions. Overall, our results identify a previously overlooked failure mode of KV cache reuse and highlight judge-centric inference as a distinct regime that demands dedicated, risk-aware system design.
Training-Free Text-Guided Color Editing with Multi-Modal Diffusion Transformer
Aug 12, 2025

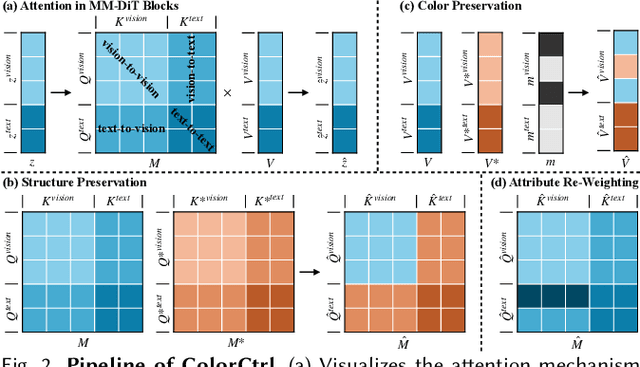
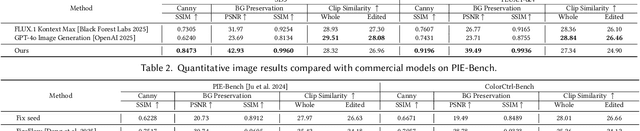
Text-guided color editing in images and videos is a fundamental yet unsolved problem, requiring fine-grained manipulation of color attributes, including albedo, light source color, and ambient lighting, while preserving physical consistency in geometry, material properties, and light-matter interactions. Existing training-free methods offer broad applicability across editing tasks but struggle with precise color control and often introduce visual inconsistency in both edited and non-edited regions. In this work, we present ColorCtrl, a training-free color editing method that leverages the attention mechanisms of modern Multi-Modal Diffusion Transformers (MM-DiT). By disentangling structure and color through targeted manipulation of attention maps and value tokens, our method enables accurate and consistent color editing, along with word-level control of attribute intensity. Our method modifies only the intended regions specified by the prompt, leaving unrelated areas untouched. Extensive experiments on both SD3 and FLUX.1-dev demonstrate that ColorCtrl outperforms existing training-free approaches and achieves state-of-the-art performances in both edit quality and consistency. Furthermore, our method surpasses strong commercial models such as FLUX.1 Kontext Max and GPT-4o Image Generation in terms of consistency. When extended to video models like CogVideoX, our approach exhibits greater advantages, particularly in maintaining temporal coherence and editing stability. Finally, our method also generalizes to instruction-based editing diffusion models such as Step1X-Edit and FLUX.1 Kontext dev, further demonstrating its versatility.
Large Language Models Have Intrinsic Meta-Cognition, but Need a Good Lens
Jun 10, 2025Previous research has primarily focused on the cognitive error detection capabilities of Large Language Models (LLMs), often prompting them to analyze mistakes in reasoning chains. However, few studies have examined the meta-cognitive abilities of LLMs (e.g., their self-awareness of step errors), which are crucial for their reliability. While studies on LLM self-evaluation present some measures, such as perplexity, which can reflect the answer correctness and be viewed as the lens of meta-cognition, they lack step-level analysis and adaptation. This paper studies the evaluation of LLM meta-cognition using the current lenses and how to improve these lenses. Specifically, we propose AutoMeco, an Automated Meta-cognition Evaluation framework for benchmarking the existing lenses. Furthermore, a training-free Markovian Intrinsic Reward Adjustment strategy, MIRA, is proposed to boost current meta-cognition lenses. Experimental results on three mathematical reasoning datasets and three LLMs show the reasonableness of AutoMeco by comparing it with Best-of-N verification. Moreover, the meta-cognition ability of LLMs can be better evaluated using MIRA.
SynGraph: A Dynamic Graph-LLM Synthesis Framework for Sparse Streaming User Sentiment Modeling
Mar 06, 2025User reviews on e-commerce platforms exhibit dynamic sentiment patterns driven by temporal and contextual factors. Traditional sentiment analysis methods focus on static reviews, failing to capture the evolving temporal relationship between user sentiment rating and textual content. Sentiment analysis on streaming reviews addresses this limitation by modeling and predicting the temporal evolution of user sentiments. However, it suffers from data sparsity, manifesting in temporal, spatial, and combined forms. In this paper, we introduce SynGraph, a novel framework designed to address data sparsity in sentiment analysis on streaming reviews. SynGraph alleviates data sparsity by categorizing users into mid-tail, long-tail, and extreme scenarios and incorporating LLM-augmented enhancements within a dynamic graph-based structure. Experiments on real-world datasets demonstrate its effectiveness in addressing sparsity and improving sentiment modeling in streaming reviews.
Explainable Depression Detection in Clinical Interviews with Personalized Retrieval-Augmented Generation
Mar 03, 2025Depression is a widespread mental health disorder, and clinical interviews are the gold standard for assessment. However, their reliance on scarce professionals highlights the need for automated detection. Current systems mainly employ black-box neural networks, which lack interpretability, which is crucial in mental health contexts. Some attempts to improve interpretability use post-hoc LLM generation but suffer from hallucination. To address these limitations, we propose RED, a Retrieval-augmented generation framework for Explainable depression Detection. RED retrieves evidence from clinical interview transcripts, providing explanations for predictions. Traditional query-based retrieval systems use a one-size-fits-all approach, which may not be optimal for depression detection, as user backgrounds and situations vary. We introduce a personalized query generation module that combines standard queries with user-specific background inferred by LLMs, tailoring retrieval to individual contexts. Additionally, to enhance LLM performance in social intelligence, we augment LLMs by retrieving relevant knowledge from a social intelligence datastore using an event-centric retriever. Experimental results on the real-world benchmark demonstrate RED's effectiveness compared to neural networks and LLM-based baselines.
PROPER: A Progressive Learning Framework for Personalized Large Language Models with Group-Level Adaptation
Mar 03, 2025Personalized large language models (LLMs) aim to tailor their outputs to user preferences. Recent advances in parameter-efficient fine-tuning (PEFT) methods have highlighted the effectiveness of adapting population-level LLMs to personalized LLMs by fine-tuning user-specific parameters with user history. However, user data is typically sparse, making it challenging to adapt LLMs to specific user patterns. To address this challenge, we propose PROgressive PERsonalization (PROPER), a novel progressive learning framework inspired by meso-level theory in social science. PROPER bridges population-level and user-level models by grouping users based on preferences and adapting LLMs in stages. It combines a Mixture-of-Experts (MoE) structure with Low Ranked Adaptation (LoRA), using a user-aware router to assign users to appropriate groups automatically. Additionally, a LoRA-aware router is proposed to facilitate the integration of individual user LoRAs with group-level LoRAs. Experimental results show that PROPER significantly outperforms SOTA models across multiple tasks, demonstrating the effectiveness of our approach.
Persuasion Should be Double-Blind: A Multi-Domain Dialogue Dataset With Faithfulness Based on Causal Theory of Mind
Feb 28, 2025Persuasive dialogue plays a pivotal role in human communication, influencing various domains. Recent persuasive dialogue datasets often fail to align with real-world interpersonal interactions, leading to unfaithful representations. For instance, unrealistic scenarios may arise, such as when the persuadee explicitly instructs the persuader on which persuasion strategies to employ, with each of the persuadee's questions corresponding to a specific strategy for the persuader to follow. This issue can be attributed to a violation of the "Double Blind" condition, where critical information is fully shared between participants. In actual human interactions, however, key information such as the mental state of the persuadee and the persuasion strategies of the persuader is not directly accessible. The persuader must infer the persuadee's mental state using Theory of Mind capabilities and construct arguments that align with the persuadee's motivations. To address this gap, we introduce ToMMA, a novel multi-agent framework for dialogue generation that is guided by causal Theory of Mind. This framework ensures that information remains undisclosed between agents, preserving "double-blind" conditions, while causal ToM directs the persuader's reasoning, enhancing alignment with human-like persuasion dynamics. Consequently, we present CToMPersu, a multi-domain, multi-turn persuasive dialogue dataset that tackles both double-blind and logical coherence issues, demonstrating superior performance across multiple metrics and achieving better alignment with real human dialogues. Our dataset and prompts are available at https://github.com/DingyiZhang/ToMMA-CToMPersu .
Benchmarking Temporal Reasoning and Alignment Across Chinese Dynasties
Feb 24, 2025Temporal reasoning is fundamental to human cognition and is crucial for various real-world applications. While recent advances in Large Language Models have demonstrated promising capabilities in temporal reasoning, existing benchmarks primarily rely on rule-based construction, lack contextual depth, and involve a limited range of temporal entities. To address these limitations, we introduce Chinese Time Reasoning (CTM), a benchmark designed to evaluate LLMs on temporal reasoning within the extensive scope of Chinese dynastic chronology. CTM emphasizes cross-entity relationships, pairwise temporal alignment, and contextualized and culturally-grounded reasoning, providing a comprehensive evaluation. Extensive experimental results reveal the challenges posed by CTM and highlight potential avenues for improvement.
RGAR: Recurrence Generation-augmented Retrieval for Factual-aware Medical Question Answering
Feb 19, 2025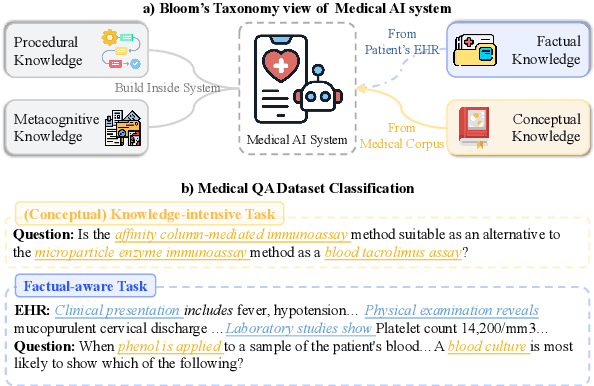
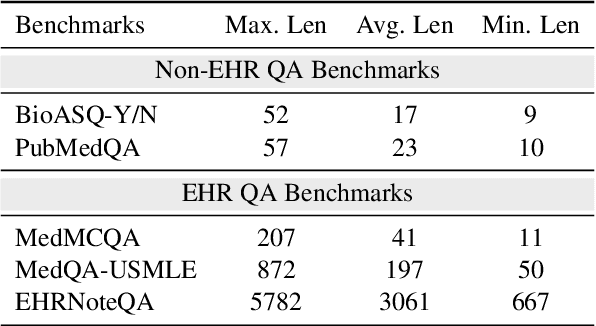
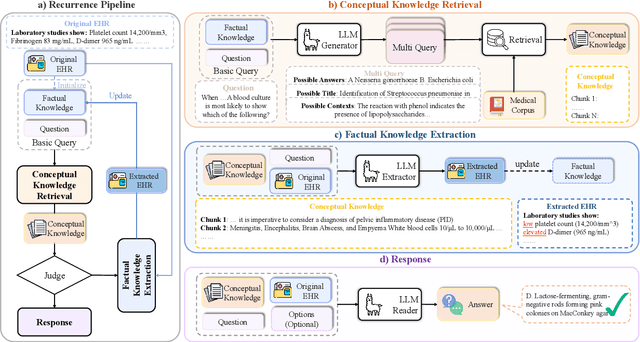
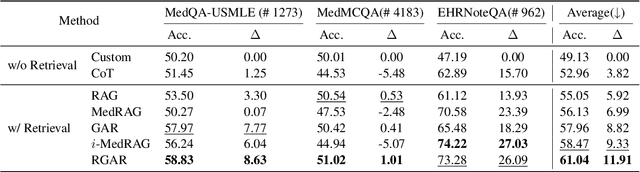
Medical question answering requires extensive access to specialized conceptual knowledge. The current paradigm, Retrieval-Augmented Generation (RAG), acquires expertise medical knowledge through large-scale corpus retrieval and uses this knowledge to guide a general-purpose large language model (LLM) for generating answers. However, existing retrieval approaches often overlook the importance of factual knowledge, which limits the relevance of retrieved conceptual knowledge and restricts its applicability in real-world scenarios, such as clinical decision-making based on Electronic Health Records (EHRs). This paper introduces RGAR, a recurrence generation-augmented retrieval framework that retrieves both relevant factual and conceptual knowledge from dual sources (i.e., EHRs and the corpus), allowing them to interact and refine each another. Through extensive evaluation across three factual-aware medical question answering benchmarks, RGAR establishes a new state-of-the-art performance among medical RAG systems. Notably, the Llama-3.1-8B-Instruct model with RGAR surpasses the considerably larger, RAG-enhanced GPT-3.5. Our findings demonstrate the benefit of extracting factual knowledge for retrieval, which consistently yields improved generation quality.