 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Vision Replace Text in Working Memory? Evidence from Spatial n-Back in Vision-Language Models
Feb 04, 2026Working memory is a central component of intelligent behavior, providing a dynamic workspace for maintaining and updating task-relevant information. Recent work has used n-back tasks to probe working-memory-like behavior in large language models, but it is unclear whether the same probe elicits comparable computations when information is carried in a visual rather than textual code in vision-language models. We evaluate Qwen2.5 and Qwen2.5-VL on a controlled spatial n-back task presented as matched text-rendered or image-rendered grids. Across conditions, models show reliably higher accuracy and d' with text than with vision. To interpret these differences at the process level, we use trial-wise log-probability evidence and find that nominal 2/3-back often fails to reflect the instructed lag and instead aligns with a recency-locked comparison. We further show that grid size alters recent-repeat structure in the stimulus stream, thereby changing interference and error patterns. These results motivate computation-sensitive interpretations of multimodal working memory.
When KV Cache Reuse Fails in Multi-Agent Systems: Cross-Candidate Interaction is Crucial for LLM Judges
Jan 13, 2026Multi-agent LLM systems routinely generate multiple candidate responses that are aggregated by an LLM judge. To reduce the dominant prefill cost in such pipelines, recent work advocates KV cache reuse across partially shared contexts and reports substantial speedups for generation agents. In this work, we show that these efficiency gains do not transfer uniformly to judge-centric inference. Across GSM8K, MMLU, and HumanEval, we find that reuse strategies that are effective for execution agents can severely perturb judge behavior: end-task accuracy may appear stable, yet the judge's selection becomes highly inconsistent with dense prefill. We quantify this risk using Judge Consistency Rate (JCR) and provide diagnostics showing that reuse systematically weakens cross-candidate attention, especially for later candidate blocks. Our ablation further demonstrates that explicit cross-candidate interaction is crucial for preserving dense-prefill decisions. Overall, our results identify a previously overlooked failure mode of KV cache reuse and highlight judge-centric inference as a distinct regime that demands dedicated, risk-aware system design.
Revisiting Data Auditing in Large Vision-Language Models
Apr 25, 2025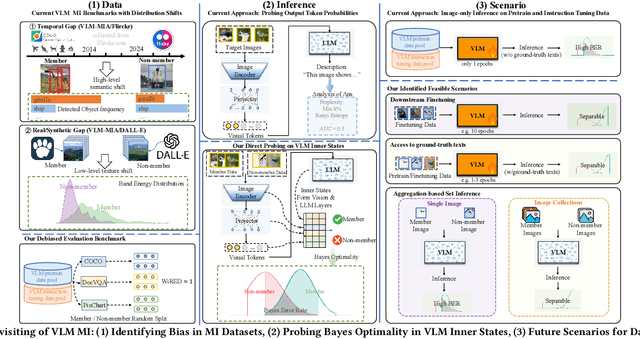
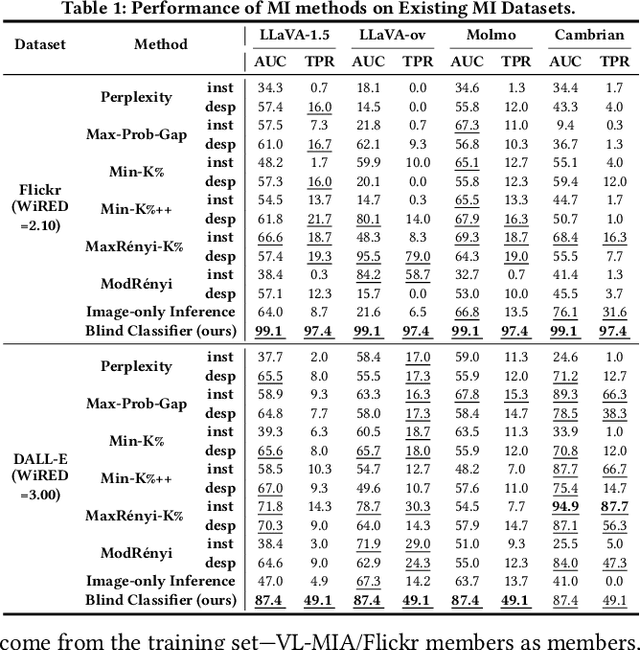
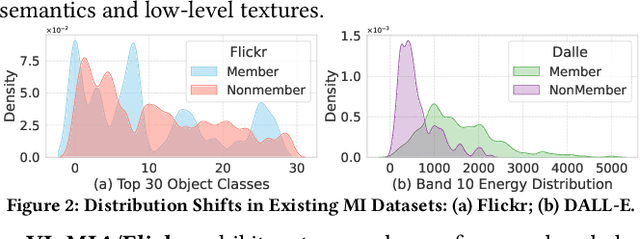
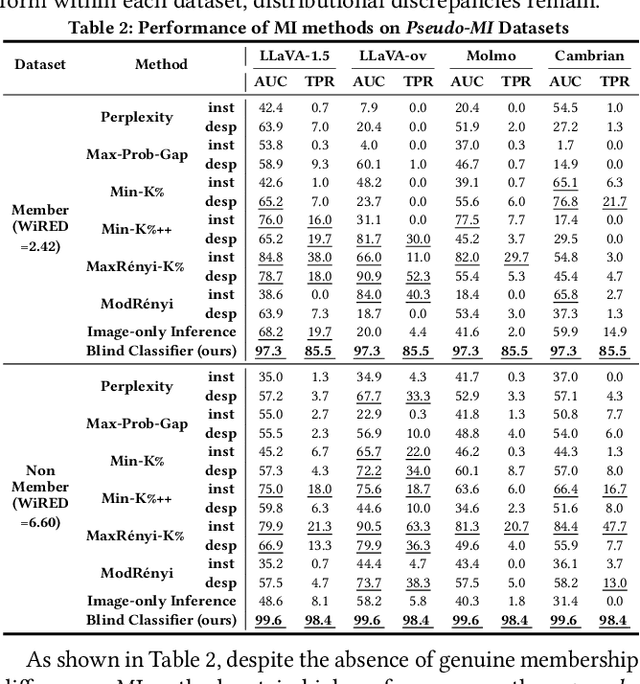
With the surge of large language models (LLMs), Large Vision-Language Models (VLMs)--which integrate vision encoders with LLMs for accurate visual grounding--have shown great potential in tasks like generalist agents and robotic control. However, VLMs are typically trained on massive web-scraped images, raising concerns over copyright infringement and privacy violations, and making data auditing increasingly urgent. Membership inference (MI), which determines whether a sample was used in training, has emerged as a key auditing technique, with promising results on open-source VLMs like LLaVA (AUC > 80%). In this work, we revisit these advances and uncover a critical issue: current MI benchmarks suffer from distribution shifts between member and non-member images, introducing shortcut cues that inflate MI performance. We further analyze the nature of these shifts and propose a principled metric based on optimal transport to quantify the distribution discrepancy. To evaluate MI in realistic settings, we construct new benchmarks with i.i.d. member and non-member images. Existing MI methods fail under these unbiased conditions, performing only marginally better than chance. Further, we explore the theoretical upper bound of MI by probing the Bayes Optimality within the VLM's embedding space and find the irreducible error rate remains high. Despite this pessimistic outlook, we analyze why MI for VLMs is particularly challenging and identify three practical scenarios--fine-tuning, access to ground-truth texts, and set-based inference--where auditing becomes feasible. Our study presents a systematic view of the limits and opportunities of MI for VLMs, providing guidance for future efforts in trustworthy data auditing.
RGAR: Recurrence Generation-augmented Retrieval for Factual-aware Medical Question Answering
Feb 19, 2025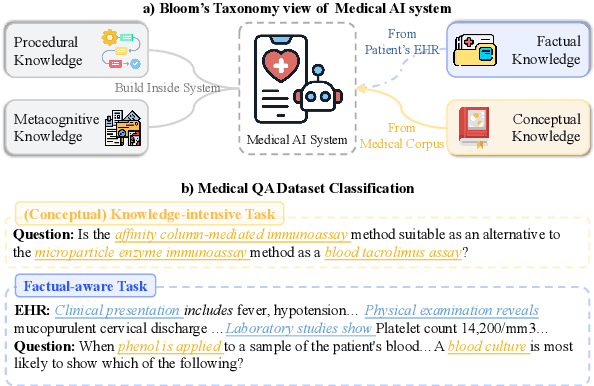
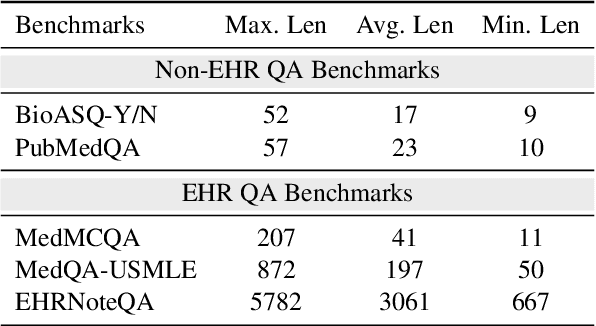
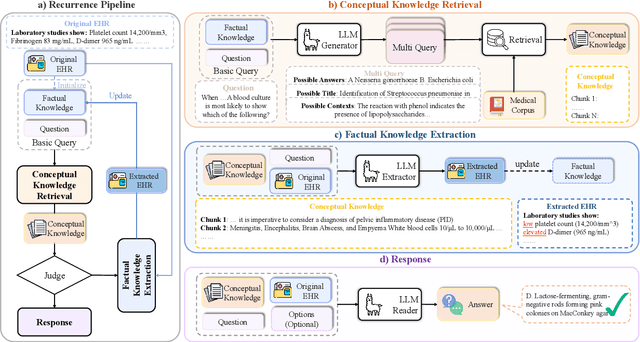
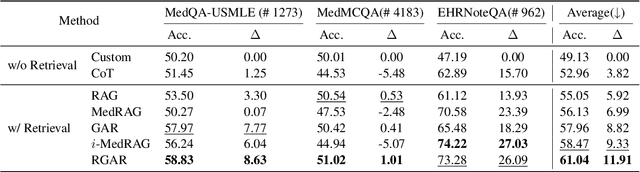
Medical question answering requires extensive access to specialized conceptual knowledge. The current paradigm, Retrieval-Augmented Generation (RAG), acquires expertise medical knowledge through large-scale corpus retrieval and uses this knowledge to guide a general-purpose large language model (LLM) for generating answers. However, existing retrieval approaches often overlook the importance of factual knowledge, which limits the relevance of retrieved conceptual knowledge and restricts its applicability in real-world scenarios, such as clinical decision-making based on Electronic Health Records (EHRs). This paper introduces RGAR, a recurrence generation-augmented retrieval framework that retrieves both relevant factual and conceptual knowledge from dual sources (i.e., EHRs and the corpus), allowing them to interact and refine each another. Through extensive evaluation across three factual-aware medical question answering benchmarks, RGAR establishes a new state-of-the-art performance among medical RAG systems. Notably, the Llama-3.1-8B-Instruct model with RGAR surpasses the considerably larger, RAG-enhanced GPT-3.5. Our findings demonstrate the benefit of extracting factual knowledge for retrieval, which consistently yields improved generation quality.
Efficient and Effective Model Extraction
Sep 24, 2024



Model extraction aims to create a functionally similar copy from a machine learning as a service (MLaaS) API with minimal overhead, typically for illicit profit or as a precursor to further attacks, posing a significant threat to the MLaaS ecosystem. However, recent studies have shown that model extraction is highly inefficient, particularly when the target task distribution is unavailable. In such cases, even substantially increasing the attack budget fails to produce a sufficiently similar replica, reducing the adversary's motivation to pursue extraction attacks. In this paper, we revisit the elementary design choices throughout the extraction lifecycle. We propose an embarrassingly simple yet dramatically effective algorithm, Efficient and Effective Model Extraction (E3), focusing on both query preparation and training routine. E3 achieves superior generalization compared to state-of-the-art methods while minimizing computational costs. For instance, with only 0.005 times the query budget and less than 0.2 times the runtime, E3 outperforms classical generative model based data-free model extraction by an absolute accuracy improvement of over 50% on CIFAR-10. Our findings underscore the persistent threat posed by model extraction and suggest that it could serve as a valuable benchmarking algorithm for future security evaluations.
Reliable Model Watermarking: Defending Against Theft without Compromising on Evasion
Apr 21, 2024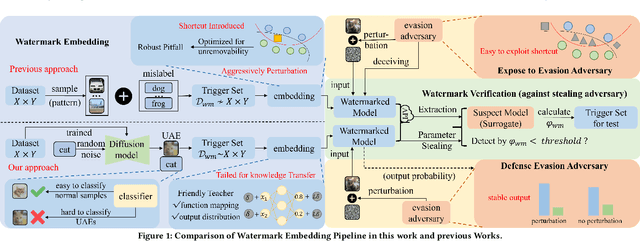
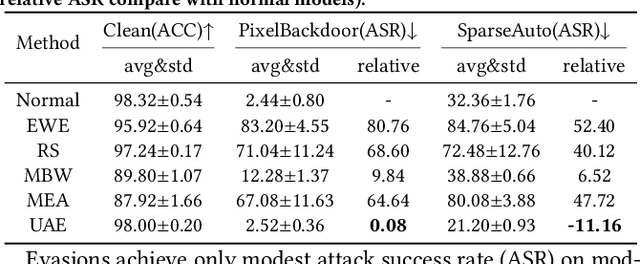
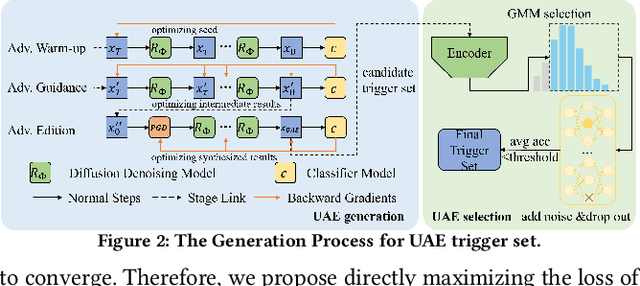

With the rise of Machine Learning as a Service (MLaaS) platforms,safeguarding the intellectual property of deep learning models is becoming paramount. Among various protective measures, trigger set watermarking has emerged as a flexible and effective strategy for preventing unauthorized model distribution. However, this paper identifies an inherent flaw in the current paradigm of trigger set watermarking: evasion adversaries can readily exploit the shortcuts created by models memorizing watermark samples that deviate from the main task distribution, significantly impairing their generalization in adversarial settings. To counteract this, we leverage diffusion models to synthesize unrestricted adversarial examples as trigger sets. By learning the model to accurately recognize them, unique watermark behaviors are promoted through knowledge injection rather than error memorization, thus avoiding exploitable shortcuts. Furthermore, we uncover that the resistance of current trigger set watermarking against removal attacks primarily relies on significantly damaging the decision boundaries during embedding, intertwining unremovability with adverse impacts. By optimizing the knowledge transfer properties of protected models, our approach conveys watermark behaviors to extraction surrogates without aggressively decision boundary perturbation. Experimental results on CIFAR-10/100 and Imagenette datasets demonstrate the effectiveness of our method, showing not only improved robustness against evasion adversaries but also superior resistance to watermark removal attacks compared to state-of-the-art solutions.
Improve Deep Forest with Learnable Layerwise Augmentation Policy Schedule
Sep 16, 2023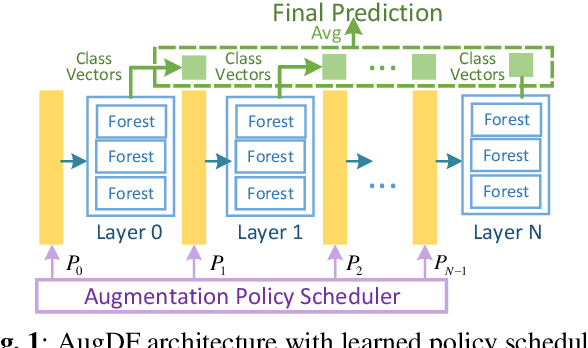
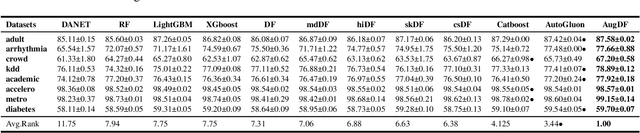
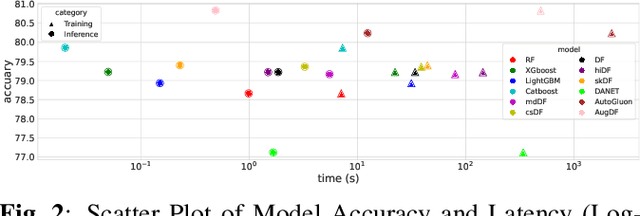
As a modern ensemble technique, Deep Forest (DF) employs a cascading structure to construct deep models, providing stronger representational power compared to traditional decision forests. However, its greedy multi-layer learning procedure is prone to overfitting, limiting model effectiveness and generalizability. This paper presents an optimized Deep Forest, featuring learnable, layerwise data augmentation policy schedules. Specifically, We introduce the Cut Mix for Tabular data (CMT) augmentation technique to mitigate overfitting and develop a population-based search algorithm to tailor augmentation intensity for each layer. Additionally, we propose to incorporate outputs from intermediate layers into a checkpoint ensemble for more stable performance. Experimental results show that our method sets new state-of-the-art (SOTA) benchmarks in various tabular classification tasks, outperforming shallow tree ensembles, deep forests, deep neural network, and AutoML competitors. The learned policies also transfer effectively to Deep Forest variants, underscoring its potential for enhancing non-differentiable deep learning modules in tabular signal processing.