 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanScale: Egocentric Human Video Can Outperform Real-Robot Data for Embodied Pretraining
Jun 18, 2026Embodied foundation models are expected to benefit from data scaling like large language models, but face a much tighter data bottleneck. Teleoperated real-robot trajectories remain the dominant pretraining source due to their precise action supervision and embodiment alignment, yet their scalability is limited by high collection cost, acquisition difficulty, and low behavioral and environmental diversity. These limitations have sparked interest in egocentric human video as a scalable, substantially lower-cost, and more diverse alternative for embodied model pretraining. However, its effectiveness compared to teleoperated real-robot data remains underexplored. To address this question, we conduct a systematic study comparing egocentric human video and teleoperated real-robot trajectories as pretraining data sources for embodied foundation models, under fixed post-training and validation protocols. Surprisingly, we find that egocentric data, when processed through a carefully designed filtering and labeling pipeline, is not merely a viable substitute for model pretraining but can lead to superior performance. With the same amount of pretraining data, models pretrained on egocentric data achieve a 24% lower validation loss on real-robot action prediction, as well as 52.5% and 90% higher success rates on in-distribution and out-of-distribution real-robot task execution, respectively. This finding verifies a scalable paradigm for embodied foundation models: pretrain on egocentric human video to learn diverse world representations, then adapt with a small amount of labeled real-robot data for action-space alignment. We hope this study encourages broader exploration of egocentric data and offers guidance for data quality assessment before costly robot data collection.
PuYun-LDM: A Latent Diffusion Model for High-Resolution Ensemble Weather Forecasts
Feb 13, 2026Latent diffusion models (LDMs) suffer from limited diffusability in high-resolution (<=0.25°) ensemble weather forecasting, where diffusability characterizes how easily a latent data distribution can be modeled by a diffusion process. Unlike natural image fields, meteorological fields lack task-agnostic foundation models and explicit semantic structures, making VFM-based regularization inapplicable. Moreover, existing frequency-based approaches impose identical spectral regularization across channels under a homogeneity assumption, which leads to uneven regularization strength under the inter-variable spectral heterogeneity in multivariate meteorological data. To address these challenges, we propose a 3D Masked AutoEncoder (3D-MAE) that encodes weather-state evolution features as an additional conditioning for the diffusion model, together with a Variable-Aware Masked Frequency Modeling (VA-MFM) strategy that adaptively selects thresholds based on the spectral energy distribution of each variable. Together, we propose PuYun-LDM, which enhances latent diffusability and achieves superior performance to ENS at short lead times while remaining comparable to ENS at longer horizons. PuYun-LDM generates a 15-day global forecast with a 6-hour temporal resolution in five minutes on a single NVIDIA H200 GPU, while ensemble forecasts can be efficiently produced in parallel.
Training-Free Text-Guided Color Editing with Multi-Modal Diffusion Transformer
Aug 12, 2025

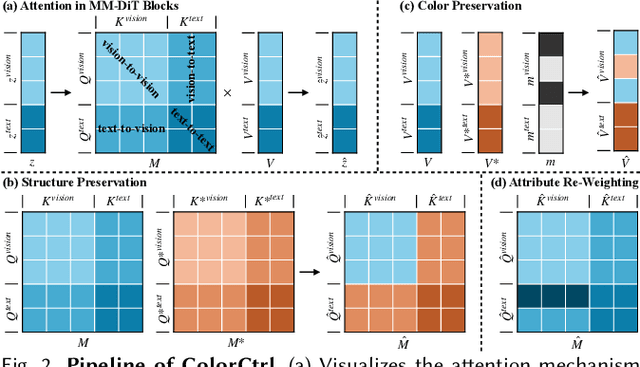
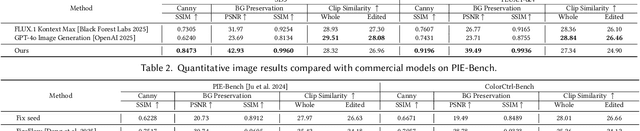
Text-guided color editing in images and videos is a fundamental yet unsolved problem, requiring fine-grained manipulation of color attributes, including albedo, light source color, and ambient lighting, while preserving physical consistency in geometry, material properties, and light-matter interactions. Existing training-free methods offer broad applicability across editing tasks but struggle with precise color control and often introduce visual inconsistency in both edited and non-edited regions. In this work, we present ColorCtrl, a training-free color editing method that leverages the attention mechanisms of modern Multi-Modal Diffusion Transformers (MM-DiT). By disentangling structure and color through targeted manipulation of attention maps and value tokens, our method enables accurate and consistent color editing, along with word-level control of attribute intensity. Our method modifies only the intended regions specified by the prompt, leaving unrelated areas untouched. Extensive experiments on both SD3 and FLUX.1-dev demonstrate that ColorCtrl outperforms existing training-free approaches and achieves state-of-the-art performances in both edit quality and consistency. Furthermore, our method surpasses strong commercial models such as FLUX.1 Kontext Max and GPT-4o Image Generation in terms of consistency. When extended to video models like CogVideoX, our approach exhibits greater advantages, particularly in maintaining temporal coherence and editing stability. Finally, our method also generalizes to instruction-based editing diffusion models such as Step1X-Edit and FLUX.1 Kontext dev, further demonstrating its versatility.
Taming Teacher Forcing for Masked Autoregressive Video Generation
Jan 21, 2025



We introduce MAGI, a hybrid video generation framework that combines masked modeling for intra-frame generation with causal modeling for next-frame generation. Our key innovation, Complete Teacher Forcing (CTF), conditions masked frames on complete observation frames rather than masked ones (namely Masked Teacher Forcing, MTF), enabling a smooth transition from token-level (patch-level) to frame-level autoregressive generation. CTF significantly outperforms MTF, achieving a +23% improvement in FVD scores on first-frame conditioned video prediction. To address issues like exposure bias, we employ targeted training strategies, setting a new benchmark in autoregressive video generation. Experiments show that MAGI can generate long, coherent video sequences exceeding 100 frames, even when trained on as few as 16 frames, highlighting its potential for scalable, high-quality video generation.
Portrait4D-v2: Pseudo Multi-View Data Creates Better 4D Head Synthesizer
Mar 20, 2024
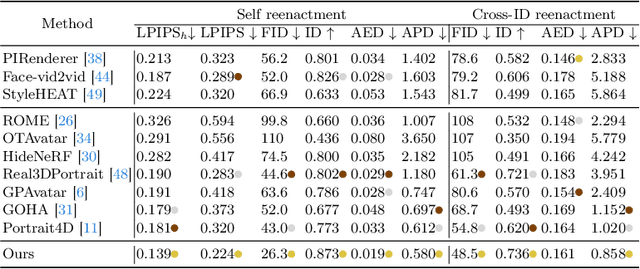
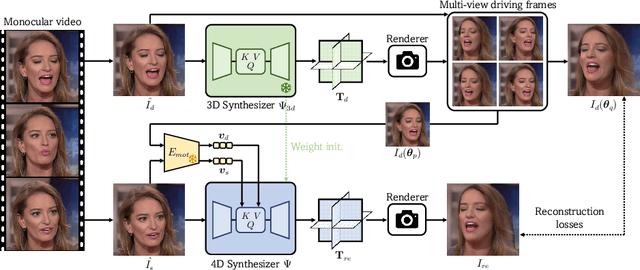

In this paper, we propose a novel learning approach for feed-forward one-shot 4D head avatar synthesis. Different from existing methods that often learn from reconstructing monocular videos guided by 3DMM, we employ pseudo multi-view videos to learn a 4D head synthesizer in a data-driven manner, avoiding reliance on inaccurate 3DMM reconstruction that could be detrimental to the synthesis performance. The key idea is to first learn a 3D head synthesizer using synthetic multi-view images to convert monocular real videos into multi-view ones, and then utilize the pseudo multi-view videos to learn a 4D head synthesizer via cross-view self-reenactment. By leveraging a simple vision transformer backbone with motion-aware cross-attentions, our method exhibits superior performance compared to previous methods in terms of reconstruction fidelity, geometry consistency, and motion control accuracy. We hope our method offers novel insights into integrating 3D priors with 2D supervisions for improved 4D head avatar creation.
PICTURE: PhotorealistIC virtual Try-on from UnconstRained dEsigns
Dec 07, 2023



In this paper, we propose a novel virtual try-on from unconstrained designs (ucVTON) task to enable photorealistic synthesis of personalized composite clothing on input human images. Unlike prior arts constrained by specific input types, our method allows flexible specification of style (text or image) and texture (full garment, cropped sections, or texture patches) conditions. To address the entanglement challenge when using full garment images as conditions, we develop a two-stage pipeline with explicit disentanglement of style and texture. In the first stage, we generate a human parsing map reflecting the desired style conditioned on the input. In the second stage, we composite textures onto the parsing map areas based on the texture input. To represent complex and non-stationary textures that have never been achieved in previous fashion editing works, we first propose extracting hierarchical and balanced CLIP features and applying position encoding in VTON. Experiments demonstrate superior synthesis quality and personalization enabled by our method. The flexible control over style and texture mixing brings virtual try-on to a new level of user experience for online shopping and fashion design.
AgentAvatar: Disentangling Planning, Driving and Rendering for Photorealistic Avatar Agents
Dec 04, 2023



In this study, our goal is to create interactive avatar agents that can autonomously plan and animate nuanced facial movements realistically, from both visual and behavioral perspectives. Given high-level inputs about the environment and agent profile, our framework harnesses LLMs to produce a series of detailed text descriptions of the avatar agents' facial motions. These descriptions are then processed by our task-agnostic driving engine into motion token sequences, which are subsequently converted into continuous motion embeddings that are further consumed by our standalone neural-based renderer to generate the final photorealistic avatar animations. These streamlined processes allow our framework to adapt to a variety of non-verbal avatar interactions, both monadic and dyadic. Our extensive study, which includes experiments on both newly compiled and existing datasets featuring two types of agents -- one capable of monadic interaction with the environment, and the other designed for dyadic conversation -- validates the effectiveness and versatility of our approach. To our knowledge, we advanced a leap step by combining LLMs and neural rendering for generalized non-verbal prediction and photo-realistic rendering of avatar agents.
Learning One-Shot 4D Head Avatar Synthesis using Synthetic Data
Nov 30, 2023



Existing one-shot 4D head synthesis methods usually learn from monocular videos with the aid of 3DMM reconstruction, yet the latter is evenly challenging which restricts them from reasonable 4D head synthesis. We present a method to learn one-shot 4D head synthesis via large-scale synthetic data. The key is to first learn a part-wise 4D generative model from monocular images via adversarial learning, to synthesize multi-view images of diverse identities and full motions as training data; then leverage a transformer-based animatable triplane reconstructor to learn 4D head reconstruction using the synthetic data. A novel learning strategy is enforced to enhance the generalizability to real images by disentangling the learning process of 3D reconstruction and reenactment. Experiments demonstrate our superiority over the prior art.
Talking Head Generation with Probabilistic Audio-to-Visual Diffusion Priors
Dec 07, 2022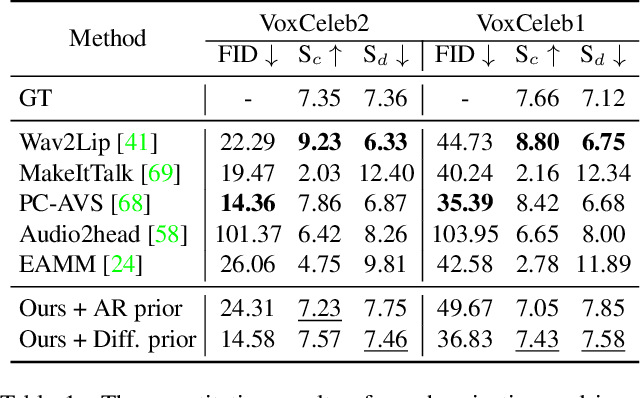
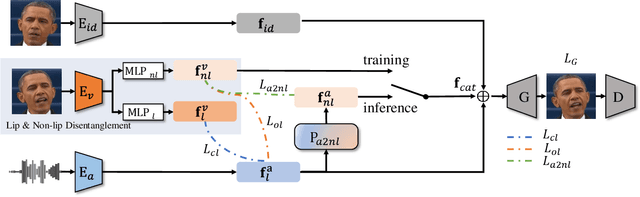
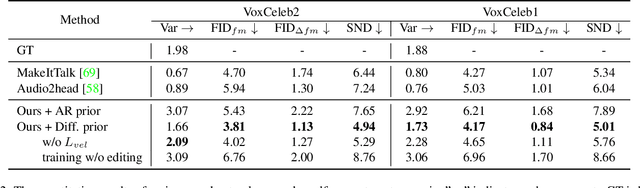
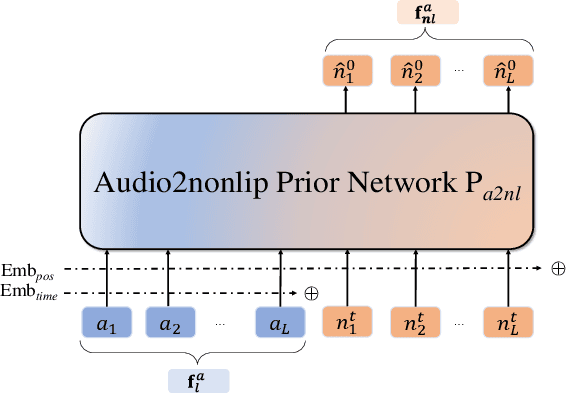
In this paper, we introduce a simple and novel framework for one-shot audio-driven talking head generation. Unlike prior works that require additional driving sources for controlled synthesis in a deterministic manner, we instead probabilistically sample all the holistic lip-irrelevant facial motions (i.e. pose, expression, blink, gaze, etc.) to semantically match the input audio while still maintaining both the photo-realism of audio-lip synchronization and the overall naturalness. This is achieved by our newly proposed audio-to-visual diffusion prior trained on top of the mapping between audio and disentangled non-lip facial representations. Thanks to the probabilistic nature of the diffusion prior, one big advantage of our framework is it can synthesize diverse facial motion sequences given the same audio clip, which is quite user-friendly for many real applications. Through comprehensive evaluations on public benchmarks, we conclude that (1) our diffusion prior outperforms auto-regressive prior significantly on almost all the concerned metrics; (2) our overall system is competitive with prior works in terms of audio-lip synchronization but can effectively sample rich and natural-looking lip-irrelevant facial motions while still semantically harmonized with the audio input.
Progressive Disentangled Representation Learning for Fine-Grained Controllable Talking Head Synthesis
Nov 26, 2022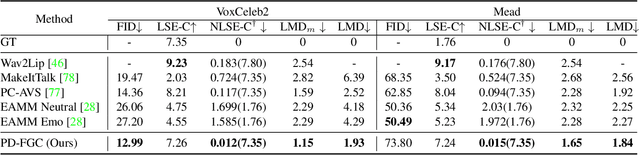
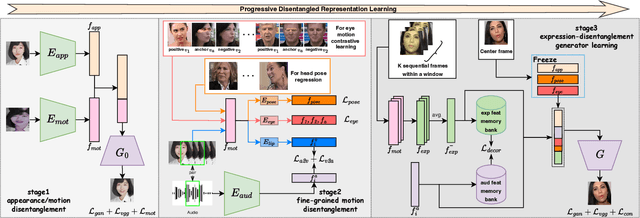
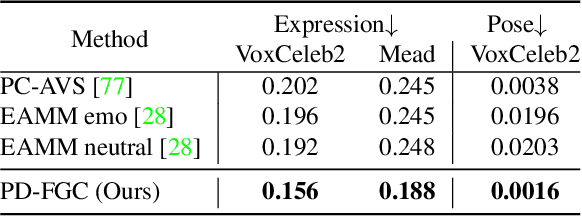

We present a novel one-shot talking head synthesis method that achieves disentangled and fine-grained control over lip motion, eye gaze&blink, head pose, and emotional expression. We represent different motions via disentangled latent representations and leverage an image generator to synthesize talking heads from them. To effectively disentangle each motion factor, we propose a progressive disentangled representation learning strategy by separating the factors in a coarse-to-fine manner, where we first extract unified motion feature from the driving signal, and then isolate each fine-grained motion from the unified feature. We introduce motion-specific contrastive learning and regressing for non-emotional motions, and feature-level decorrelation and self-reconstruction for emotional expression, to fully utilize the inherent properties of each motion factor in unstructured video data to achieve disentanglement. Experiments show that our method provides high quality speech&lip-motion synchronization along with precise and disentangled control over multiple extra facial motions, which can hardly be achieved by previous methods.