 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartNerFace: Part-based Neural Radiance Fields for Animatable Facial Avatar Reconstruction
Apr 15, 2026We present PartNerFace, a part-based neural radiance fields approach, for reconstructing animatable facial avatar from monocular RGB videos. Existing solutions either simply condition the implicit network with the morphable model parameters or learn an imaginary canonical radiance field, making them fail to generalize to unseen facial expressions and capture fine-scale motion details. To address these challenges, we first apply inverse skinning based on a parametric head model to map an observed point to the canonical space, and then model fine-scale motions with a part-based deformation field. Our key insight is that the deformation of different facial parts should be modeled differently. Specifically, our part-based deformation field consists of multiple local MLPs to adaptively partition the canonical space into different parts, where the deformation of a 3D point is computed by aggregating the prediction of all local MLPs by a soft-weighting mechanism. Extensive experiments demonstrate that our method generalizes well to unseen expressions and is capable of modeling fine-scale facial motions, outperforming state-of-the-art methods both quantitatively and qualitatively.
Learning One-Shot 4D Head Avatar Synthesis using Synthetic Data
Nov 30, 2023



Existing one-shot 4D head synthesis methods usually learn from monocular videos with the aid of 3DMM reconstruction, yet the latter is evenly challenging which restricts them from reasonable 4D head synthesis. We present a method to learn one-shot 4D head synthesis via large-scale synthetic data. The key is to first learn a part-wise 4D generative model from monocular images via adversarial learning, to synthesize multi-view images of diverse identities and full motions as training data; then leverage a transformer-based animatable triplane reconstructor to learn 4D head reconstruction using the synthetic data. A novel learning strategy is enforced to enhance the generalizability to real images by disentangling the learning process of 3D reconstruction and reenactment. Experiments demonstrate our superiority over the prior art.
Reinforced Disentanglement for Face Swapping without Skip Connection
Aug 03, 2023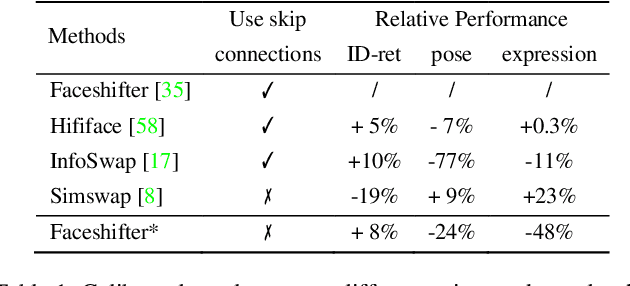
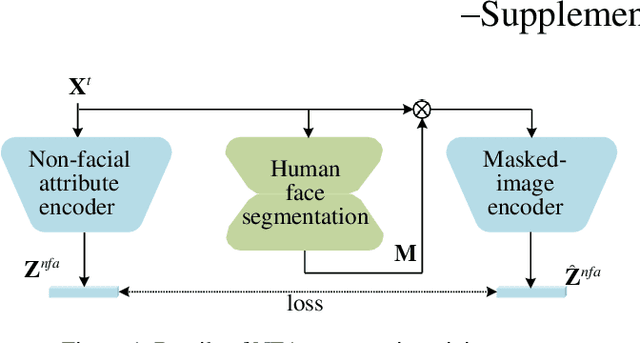
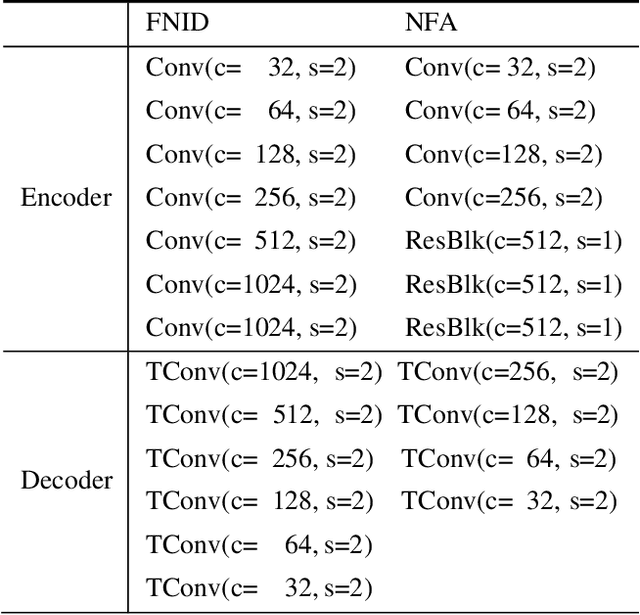

The SOTA face swap models still suffer the problem of either target identity (i.e., shape) being leaked or the target non-identity attributes (i.e., background, hair) failing to be fully preserved in the final results. We show that this insufficient disentanglement is caused by two flawed designs that were commonly adopted in prior models: (1) counting on only one compressed encoder to represent both the semantic-level non-identity facial attributes(i.e., pose) and the pixel-level non-facial region details, which is contradictory to satisfy at the same time; (2) highly relying on long skip-connections between the encoder and the final generator, leaking a certain amount of target face identity into the result. To fix them, we introduce a new face swap framework called 'WSC-swap' that gets rid of skip connections and uses two target encoders to respectively capture the pixel-level non-facial region attributes and the semantic non-identity attributes in the face region. To further reinforce the disentanglement learning for the target encoder, we employ both identity removal loss via adversarial training (i.e., GAN) and the non-identity preservation loss via prior 3DMM models like [11]. Extensive experiments on both FaceForensics++ and CelebA-HQ show that our results significantly outperform previous works on a rich set of metrics, including one novel metric for measuring identity consistency that was completely neglected before.
A Novel Scene Text Detection Algorithm Based On Convolutional Neural Network
Apr 07, 2016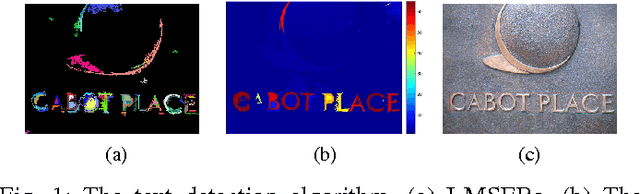
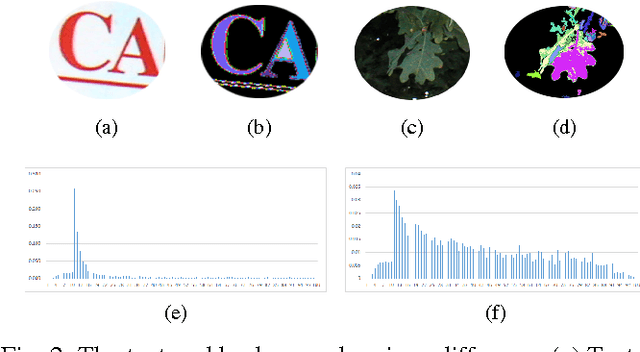
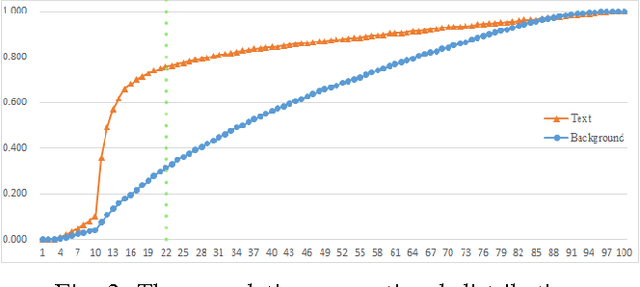
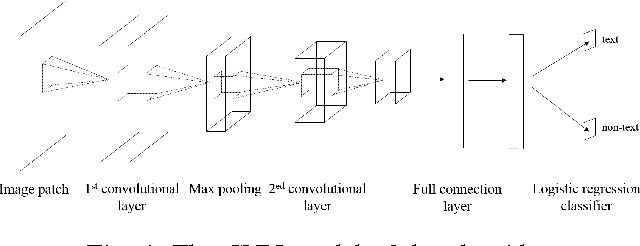
Candidate text region extraction plays a critical role in convolutional neural network (CNN) based text detection from natural images. In this paper, we propose a CNN based scene text detection algorithm with a new text region extractor. The so called candidate text region extractor I-MSER is based on Maximally Stable Extremal Region (MSER), which can improve the independency and completeness of the extracted candidate text regions. Design of I-MSER is motivated by the observation that text MSERs have high similarity and are close to each other. The independency of candidate text regions obtained by I-MSER is guaranteed by selecting the most representative regions from a MSER tree which is generated according to the spatial overlapping relationship among the MSERs. A multi-layer CNN model is trained to score the confidence value of the extracted regions extracted by the I-MSER for text detection. The new text detection algorithm based on I-MSER is evaluated with wide-used ICDAR 2011 and 2013 datasets and shows improved detection performance compared to the existing algorithms.
A CNN Based Scene Chinese Text Recognition Algorithm With Synthetic Data Engine
Apr 07, 2016
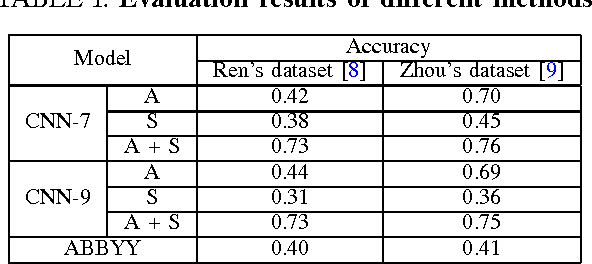
Scene text recognition plays an important role in many computer vision applications. The small size of available public available scene text datasets is the main challenge when training a text recognition CNN model. In this paper, we propose a CNN based Chinese text recognition algorithm. To enlarge the dataset for training the CNN model, we design a synthetic data engine for Chinese scene character generation, which generates representative character images according to the fonts use frequency of Chinese texts. As the Chinese text is more complex, the English text recognition CNN architecture is modified for Chinese text. To ensure the small size nature character dataset and the large size artificial character dataset are comparable in training, the CNN model are trained progressively. The proposed Chinese text recognition algorithm is evaluated with two Chinese text datasets. The algorithm achieves better recognize accuracy compared to the baseline methods.