 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeULTRA: Unified Multimodal Control for Autonomous Humanoid Whole-Body Loco-Manipulation
Mar 03, 2026Achieving autonomous and versatile whole-body loco-manipulation remains a central barrier to making humanoids practically useful. Yet existing approaches are fundamentally constrained: retargeted data are often scarce or low-quality; methods struggle to scale to large skill repertoires; and, most importantly, they rely on tracking predefined motion references rather than generating behavior from perception and high-level task specifications. To address these limitations, we propose ULTRA, a unified framework with two key components. First, we introduce a physics-driven neural retargeting algorithm that translates large-scale motion capture to humanoid embodiments while preserving physical plausibility for contact-rich interactions. Second, we learn a unified multimodal controller that supports both dense references and sparse task specifications, under sensing ranging from accurate motion-capture state to noisy egocentric visual inputs. We distill a universal tracking policy into this controller, compress motor skills into a compact latent space, and apply reinforcement learning finetuning to expand coverage and improve robustness under out-of-distribution scenarios. This enables coordinated whole-body behavior from sparse intent without test-time reference motions. We evaluate ULTRA in simulation and on a real Unitree G1 humanoid. Results show that ULTRA generalizes to autonomous, goal-conditioned whole-body loco-manipulation from egocentric perception, consistently outperforming tracking-only baselines with limited skills.
Learning Humanoid End-Effector Control for Open-Vocabulary Visual Loco-Manipulation
Feb 18, 2026Visual loco-manipulation of arbitrary objects in the wild with humanoid robots requires accurate end-effector (EE) control and a generalizable understanding of the scene via visual inputs (e.g., RGB-D images). Existing approaches are based on real-world imitation learning and exhibit limited generalization due to the difficulty in collecting large-scale training datasets. This paper presents a new paradigm, HERO, for object loco-manipulation with humanoid robots that combines the strong generalization and open-vocabulary understanding of large vision models with strong control performance from simulated training. We achieve this by designing an accurate residual-aware EE tracking policy. This EE tracking policy combines classical robotics with machine learning. It uses a) inverse kinematics to convert residual end-effector targets into reference trajectories, b) a learned neural forward model for accurate forward kinematics, c) goal adjustment, and d) replanning. Together, these innovations help us cut down the end-effector tracking error by 3.2x. We use this accurate end-effector tracker to build a modular system for loco-manipulation, where we use open-vocabulary large vision models for strong visual generalization. Our system is able to operate in diverse real-world environments, from offices to coffee shops, where the robot is able to reliably manipulate various everyday objects (e.g., mugs, apples, toys) on surfaces ranging from 43cm to 92cm in height. Systematic modular and end-to-end tests in simulation and the real world demonstrate the effectiveness of our proposed design. We believe the advances in this paper can open up new ways of training humanoid robots to interact with daily objects.
AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time
May 30, 2025This paper presents AlphaOne ($\alpha$1), a universal framework for modulating reasoning progress in large reasoning models (LRMs) at test time. $\alpha$1 first introduces $\alpha$ moment, which represents the scaled thinking phase with a universal parameter $\alpha$. Within this scaled pre-$\alpha$ moment phase, it dynamically schedules slow thinking transitions by modeling the insertion of reasoning transition tokens as a Bernoulli stochastic process. After the $\alpha$ moment, $\alpha$1 deterministically terminates slow thinking with the end-of-thinking token, thereby fostering fast reasoning and efficient answer generation. This approach unifies and generalizes existing monotonic scaling methods by enabling flexible and dense slow-to-fast reasoning modulation. Extensive empirical studies on various challenging benchmarks across mathematical, coding, and scientific domains demonstrate $\alpha$1's superior reasoning capability and efficiency. Project page: https://alphaone-project.github.io/
Perception in Reflection
Apr 09, 2025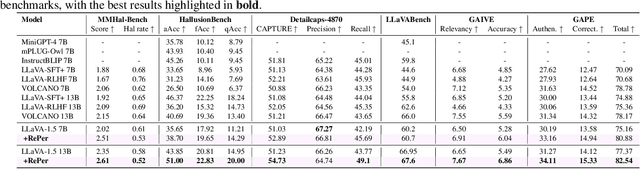



We present a perception in reflection paradigm designed to transcend the limitations of current large vision-language models (LVLMs), which are expected yet often fail to achieve perfect perception initially. Specifically, we propose Reflective Perception (RePer), a dual-model reflection mechanism that systematically alternates between policy and critic models, enables iterative refinement of visual perception. This framework is powered by Reflective Perceptual Learning (RPL), which reinforces intrinsic reflective capabilities through a methodically constructed visual reflection dataset and reflective unlikelihood training. Comprehensive experimental evaluation demonstrates RePer's quantifiable improvements in image understanding, captioning precision, and hallucination reduction. Notably, RePer achieves strong alignment between model attention patterns and human visual focus, while RPL optimizes fine-grained and free-form preference alignment. These advancements establish perception in reflection as a robust paradigm for future multimodal agents, particularly in tasks requiring complex reasoning and multi-step manipulation.
SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
Feb 18, 2025


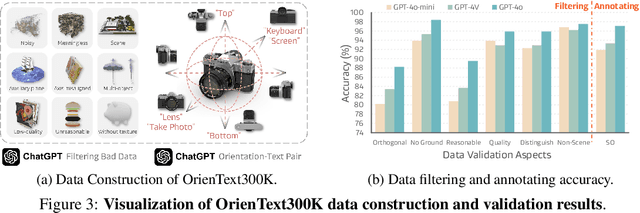
Spatial intelligence is a critical component of embodied AI, promoting robots to understand and interact with their environments. While recent advances have enhanced the ability of VLMs to perceive object locations and positional relationships, they still lack the capability to precisely understand object orientations-a key requirement for tasks involving fine-grained manipulations. Addressing this limitation not only requires geometric reasoning but also an expressive and intuitive way to represent orientation. In this context, we propose that natural language offers a more flexible representation space than canonical frames, making it particularly suitable for instruction-following robotic systems. In this paper, we introduce the concept of semantic orientation, which defines object orientations using natural language in a reference-frame-free manner (e.g., the ''plug-in'' direction of a USB or the ''handle'' direction of a knife). To support this, we construct OrienText300K, a large-scale dataset of 3D models annotated with semantic orientations that link geometric understanding to functional semantics. By integrating semantic orientation into a VLM system, we enable robots to generate manipulation actions with both positional and orientational constraints. Extensive experiments in simulation and real world demonstrate that our approach significantly enhances robotic manipulation capabilities, e.g., 48.7% accuracy on Open6DOR and 74.9% accuracy on SIMPLER.
Learning Getting-Up Policies for Real-World Humanoid Robots
Feb 17, 2025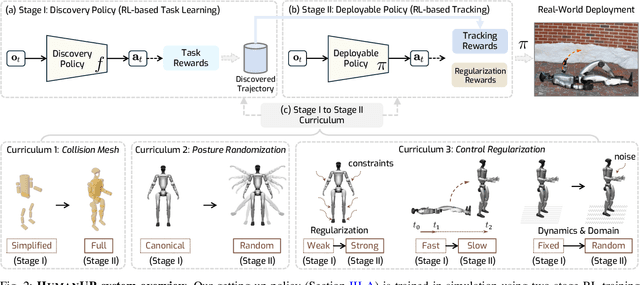
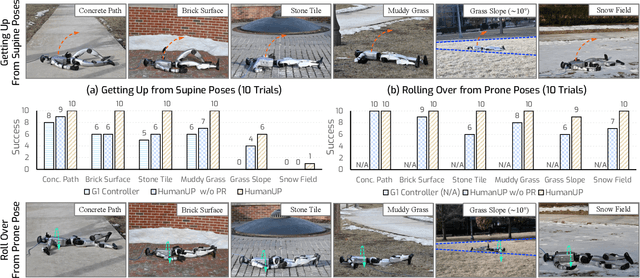
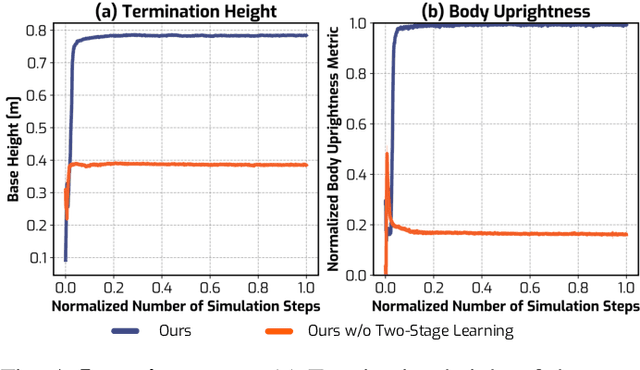
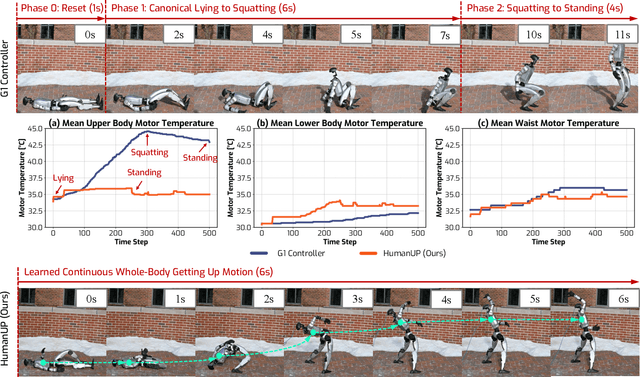
Automatic fall recovery is a crucial prerequisite before humanoid robots can be reliably deployed. Hand-designing controllers for getting up is difficult because of the varied configurations a humanoid can end up in after a fall and the challenging terrains humanoid robots are expected to operate on. This paper develops a learning framework to produce controllers that enable humanoid robots to get up from varying configurations on varying terrains. Unlike previous successful applications of humanoid locomotion learning, the getting-up task involves complex contact patterns, which necessitates accurately modeling the collision geometry and sparser rewards. We address these challenges through a two-phase approach that follows a curriculum. The first stage focuses on discovering a good getting-up trajectory under minimal constraints on smoothness or speed / torque limits. The second stage then refines the discovered motions into deployable (i.e. smooth and slow) motions that are robust to variations in initial configuration and terrains. We find these innovations enable a real-world G1 humanoid robot to get up from two main situations that we considered: a) lying face up and b) lying face down, both tested on flat, deformable, slippery surfaces and slopes (e.g., sloppy grass and snowfield). To the best of our knowledge, this is the first successful demonstration of learned getting-up policies for human-sized humanoid robots in the real world. Project page: https://humanoid-getup.github.io/
Taming Teacher Forcing for Masked Autoregressive Video Generation
Jan 21, 2025



We introduce MAGI, a hybrid video generation framework that combines masked modeling for intra-frame generation with causal modeling for next-frame generation. Our key innovation, Complete Teacher Forcing (CTF), conditions masked frames on complete observation frames rather than masked ones (namely Masked Teacher Forcing, MTF), enabling a smooth transition from token-level (patch-level) to frame-level autoregressive generation. CTF significantly outperforms MTF, achieving a +23% improvement in FVD scores on first-frame conditioned video prediction. To address issues like exposure bias, we employ targeted training strategies, setting a new benchmark in autoregressive video generation. Experiments show that MAGI can generate long, coherent video sequences exceeding 100 frames, even when trained on as few as 16 frames, highlighting its potential for scalable, high-quality video generation.
Positional Prompt Tuning for Efficient 3D Representation Learning
Aug 21, 2024

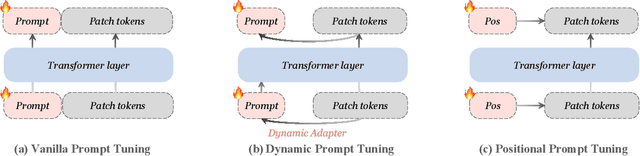

Point cloud analysis has achieved significant development and is well-performed in multiple downstream tasks like point cloud classification and segmentation, etc. Being conscious of the simplicity of the position encoding structure in Transformer-based architectures, we attach importance to the position encoding as a high-dimensional part and the patch encoder to offer multi-scale information. Together with the sequential Transformer, the whole module with position encoding comprehensively constructs a multi-scale feature abstraction module that considers both the local parts from the patch and the global parts from center points as position encoding. With only a few parameters, the position embedding module fits the setting of PEFT (Parameter-Efficient Fine-Tuning) tasks pretty well. Thus we unfreeze these parameters as a fine-tuning part. At the same time, we review the existing prompt and adapter tuning methods, proposing a fresh way of prompts and synthesizing them with adapters as dynamic adjustments. Our Proposed method of PEFT tasks, namely PPT, with only 1.05% of parameters for training, gets state-of-the-art results in several mainstream datasets, such as 95.01% accuracy in the ScanObjectNN OBJ_BG dataset. Codes will be released at https://github.com/zsc000722/PPT.
DreamBench++: A Human-Aligned Benchmark for Personalized Image Generation
Jun 24, 2024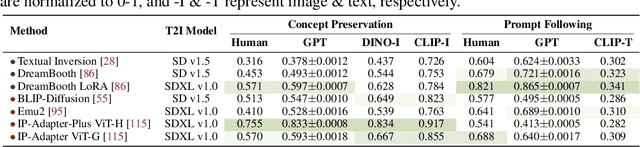



Personalized image generation holds great promise in assisting humans in everyday work and life due to its impressive function in creatively generating personalized content. However, current evaluations either are automated but misalign with humans or require human evaluations that are time-consuming and expensive. In this work, we present DreamBench++, a human-aligned benchmark automated by advanced multimodal GPT models. Specifically, we systematically design the prompts to let GPT be both human-aligned and self-aligned, empowered with task reinforcement. Further, we construct a comprehensive dataset comprising diverse images and prompts. By benchmarking 7 modern generative models, we demonstrate that DreamBench++ results in significantly more human-aligned evaluation, helping boost the community with innovative findings.
ShapeLLM: Universal 3D Object Understanding for Embodied Interaction
Mar 06, 2024



This paper presents ShapeLLM, the first 3D Multimodal Large Language Model (LLM) designed for embodied interaction, exploring a universal 3D object understanding with 3D point clouds and languages. ShapeLLM is built upon an improved 3D encoder by extending ReCon to ReCon++ that benefits from multi-view image distillation for enhanced geometry understanding. By utilizing ReCon++ as the 3D point cloud input encoder for LLMs, ShapeLLM is trained on constructed instruction-following data and tested on our newly human-curated evaluation benchmark, 3D MM-Vet. ReCon++ and ShapeLLM achieve state-of-the-art performance in 3D geometry understanding and language-unified 3D interaction tasks, such as embodied visual grounding.