 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialEvo: Self-Evolving Spatial Intelligence via Deterministic Geometric Environments
Apr 15, 2026Spatial reasoning over three-dimensional scenes is a core capability for embodied intelligence, yet continuous model improvement remains bottlenecked by the cost of geometric annotation. The self-evolving paradigm offers a promising path, but its reliance on model consensus to construct pseudo-labels causes training to reinforce rather than correct the model's own geometric errors. We identify a property unique to 3D spatial reasoning that circumvents this limitation: ground truth is a deterministic consequence of the underlying geometry, computable exactly from point clouds and camera poses without any model involvement. Building on this insight, we present SpatialEvo, a self-evolving framework for 3D spatial reasoning, centered on the Deterministic Geometric Environment (DGE). The DGE formalizes 16 spatial reasoning task categories under explicit geometric validation rules and converts unannotated 3D scenes into zero-noise interactive oracles, replacing model consensus with objective physical feedback. A single shared-parameter policy co-evolves across questioner and solver roles under DGE constraints: the questioner generates physically valid spatial questions grounded in scene observations, while the solver derives precise answers against DGE-verified ground truth. A task-adaptive scheduler endogenously concentrates training on the model's weakest categories, producing a dynamic curriculum without manual design. Experiments across nine benchmarks demonstrate that SpatialEvo achieves the highest average score at both 3B and 7B scales, with consistent gains on spatial reasoning benchmarks and no degradation on general visual understanding.
DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI
Feb 16, 2026Moving beyond the traditional paradigm of adapting internet-pretrained models to physical tasks, we present DM0, an Embodied-Native Vision-Language-Action (VLA) framework designed for Physical AI. Unlike approaches that treat physical grounding as a fine-tuning afterthought, DM0 unifies embodied manipulation and navigation by learning from heterogeneous data sources from the onset. Our methodology follows a comprehensive three-stage pipeline: Pretraining, Mid-Training, and Post-Training. First, we conduct large-scale unified pretraining on the Vision-Language Model (VLM) using diverse corpora--seamlessly integrating web text, autonomous driving scenarios, and embodied interaction logs-to jointly acquire semantic knowledge and physical priors. Subsequently, we build a flow-matching action expert atop the VLM. To reconcile high-level reasoning with low-level control, DM0 employs a hybrid training strategy: for embodied data, gradients from the action expert are not backpropagated to the VLM to preserve generalized representations, while the VLM remains trainable on non-embodied data. Furthermore, we introduce an Embodied Spatial Scaffolding strategy to construct spatial Chain-of-Thought (CoT) reasoning, effectively constraining the action solution space. Experiments on the RoboChallenge benchmark demonstrate that DM0 achieves state-of-the-art performance in both Specialist and Generalist settings on Table30.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
Perception-R1: Pioneering Perception Policy with Reinforcement Learning
Apr 10, 2025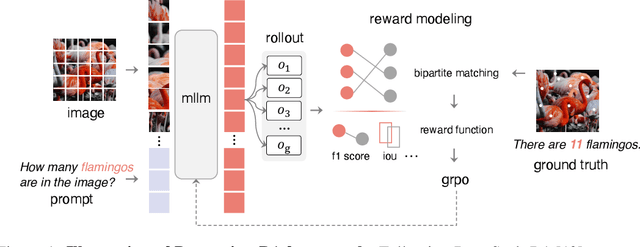
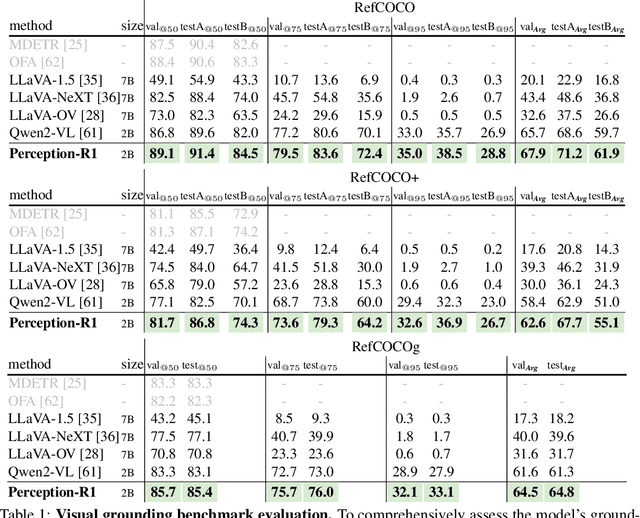
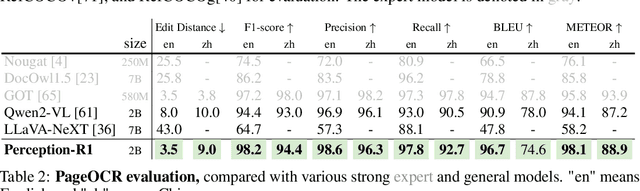
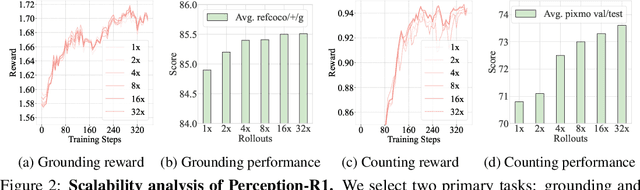
Inspired by the success of DeepSeek-R1, we explore the potential of rule-based reinforcement learning (RL) in MLLM post-training for perception policy learning. While promising, our initial experiments reveal that incorporating a thinking process through RL does not consistently lead to performance gains across all visual perception tasks. This leads us to delve into the essential role of RL in the context of visual perception. In this work, we return to the fundamentals and explore the effects of RL on different perception tasks. We observe that the perceptual complexity is a major factor in determining the effectiveness of RL. We also observe that reward design plays a crucial role in further approching the upper limit of model perception. To leverage these findings, we propose Perception-R1, a scalable RL framework using GRPO during MLLM post-training. With a standard Qwen2.5-VL-3B-Instruct, Perception-R1 achieves +4.2% on RefCOCO+, +17.9% on PixMo-Count, +4.2% on PageOCR, and notably, 31.9% AP on COCO2017 val for the first time, establishing a strong baseline for perception policy learning.
Perception in Reflection
Apr 09, 2025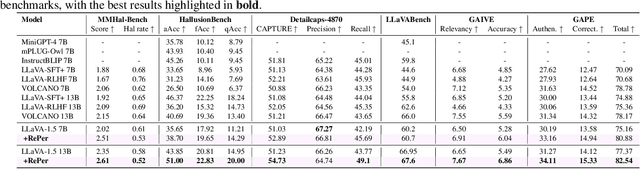



We present a perception in reflection paradigm designed to transcend the limitations of current large vision-language models (LVLMs), which are expected yet often fail to achieve perfect perception initially. Specifically, we propose Reflective Perception (RePer), a dual-model reflection mechanism that systematically alternates between policy and critic models, enables iterative refinement of visual perception. This framework is powered by Reflective Perceptual Learning (RPL), which reinforces intrinsic reflective capabilities through a methodically constructed visual reflection dataset and reflective unlikelihood training. Comprehensive experimental evaluation demonstrates RePer's quantifiable improvements in image understanding, captioning precision, and hallucination reduction. Notably, RePer achieves strong alignment between model attention patterns and human visual focus, while RPL optimizes fine-grained and free-form preference alignment. These advancements establish perception in reflection as a robust paradigm for future multimodal agents, particularly in tasks requiring complex reasoning and multi-step manipulation.
Unhackable Temporal Rewarding for Scalable Video MLLMs
Feb 17, 2025



In the pursuit of superior video-processing MLLMs, we have encountered a perplexing paradox: the "anti-scaling law", where more data and larger models lead to worse performance. This study unmasks the culprit: "temporal hacking", a phenomenon where models shortcut by fixating on select frames, missing the full video narrative. In this work, we systematically establish a comprehensive theory of temporal hacking, defining it from a reinforcement learning perspective, introducing the Temporal Perplexity (TPL) score to assess this misalignment, and proposing the Unhackable Temporal Rewarding (UTR) framework to mitigate the temporal hacking. Both theoretically and empirically, TPL proves to be a reliable indicator of temporal modeling quality, correlating strongly with frame activation patterns. Extensive experiments reveal that UTR not only counters temporal hacking but significantly elevates video comprehension capabilities. This work not only advances video-AI systems but also illuminates the critical importance of aligning proxy rewards with true objectives in MLLM development.
PerPO: Perceptual Preference Optimization via Discriminative Rewarding
Feb 05, 2025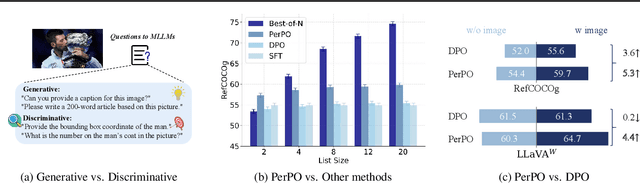
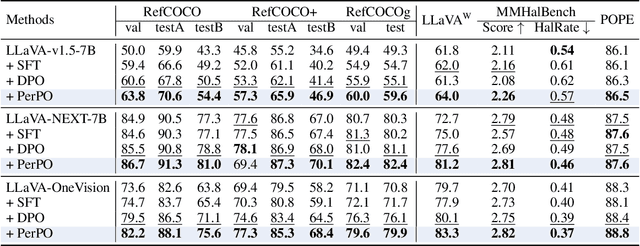
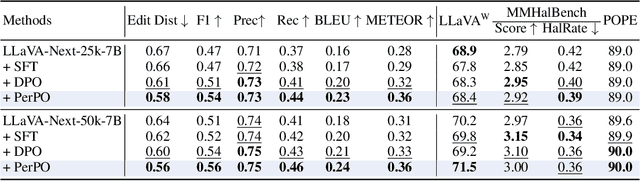
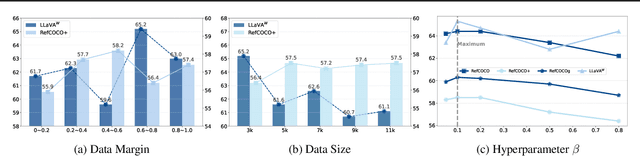
This paper presents Perceptual Preference Optimization (PerPO), a perception alignment method aimed at addressing the visual discrimination challenges in generative pre-trained multimodal large language models (MLLMs). To align MLLMs with human visual perception process, PerPO employs discriminative rewarding to gather diverse negative samples, followed by listwise preference optimization to rank them.By utilizing the reward as a quantitative margin for ranking, our method effectively bridges generative preference optimization and discriminative empirical risk minimization. PerPO significantly enhances MLLMs' visual discrimination capabilities while maintaining their generative strengths, mitigates image-unconditional reward hacking, and ensures consistent performance across visual tasks. This work marks a crucial step towards more perceptually aligned and versatile MLLMs. We also hope that PerPO will encourage the community to rethink MLLM alignment strategies.