 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerPO: Perceptual Preference Optimization via Discriminative Rewarding
Paper and Code
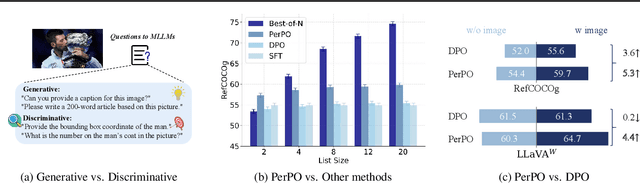
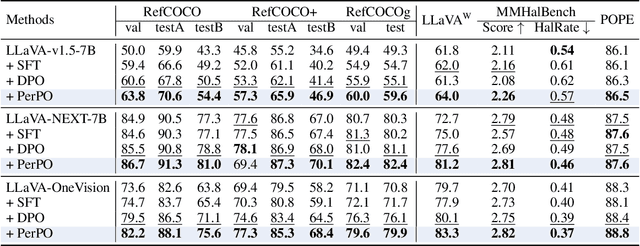
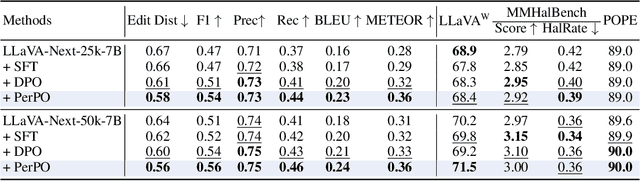
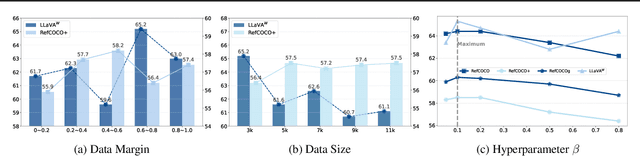
This paper presents Perceptual Preference Optimization (PerPO), a perception alignment method aimed at addressing the visual discrimination challenges in generative pre-trained multimodal large language models (MLLMs). To align MLLMs with human visual perception process, PerPO employs discriminative rewarding to gather diverse negative samples, followed by listwise preference optimization to rank them.By utilizing the reward as a quantitative margin for ranking, our method effectively bridges generative preference optimization and discriminative empirical risk minimization. PerPO significantly enhances MLLMs' visual discrimination capabilities while maintaining their generative strengths, mitigates image-unconditional reward hacking, and ensures consistent performance across visual tasks. This work marks a crucial step towards more perceptually aligned and versatile MLLMs. We also hope that PerPO will encourage the community to rethink MLLM alignment strategies.